Infusion: Preventing Customized Text-to-Image Diffusion from Overfitting
2404.14007
0
2

Abstract
Text-to-image (T2I) customization aims to create images that embody specific visual concepts delineated in textual descriptions. However, existing works still face a main challenge, concept overfitting. To tackle this challenge, we first analyze overfitting, categorizing it into concept-agnostic overfitting, which undermines non-customized concept knowledge, and concept-specific overfitting, which is confined to customize on limited modalities, i.e, backgrounds, layouts, styles. To evaluate the overfitting degree, we further introduce two metrics, i.e, Latent Fisher divergence and Wasserstein metric to measure the distribution changes of non-customized and customized concept respectively. Drawing from the analysis, we propose Infusion, a T2I customization method that enables the learning of target concepts to avoid being constrained by limited training modalities, while preserving non-customized knowledge. Remarkably, Infusion achieves this feat with remarkable efficiency, requiring a mere 11KB of trained parameters. Extensive experiments also demonstrate that our approach outperforms state-of-the-art methods in both single and multi-concept customized generation.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This paper presents "Infusion", a method for preventing customized text-to-image diffusion models from overfitting to specific training data.
• The key ideas are:
- Concept-agnostic and concept-specific learning to improve generalization
- A novel "Infusion" technique that mixes concept-agnostic and concept-specific representations during training
Plain English Explanation
This paper addresses a problem with customized text-to-image diffusion models - they can become too specialized on the specific images and text they were trained on, and fail to generalize well to new inputs. The researchers developed a new training approach called "Infusion" to help these models stay flexible and learn both general and specific knowledge.
The core idea is to train the model in two parallel paths - one that learns general, "concept-agnostic" representations, and one that learns specific, "concept-specific" representations for each type of input. During training, the model constantly switches between these two pathways, "infusing" the general and specific knowledge together. This prevents the model from becoming too narrowly focused on the training data and helps it learn a more robust and generalizable set of skills.
The end result is a customized text-to-image model that can create high-quality, tailored images, while still maintaining broad capabilities to handle diverse new inputs. This could be valuable for applications where personalization is important, but without sacrificing the model's overall performance.
Technical Explanation
The paper first reviews prior work on text-to-image generation, including efforts to improve customization and multi-concept fusion [<a href="https://aimodels.fyi/papers/arxiv/concept-weaver-enabling-multi-concept-fusion-text">Concept Weaver</a>], [<a href="https://aimodels.fyi/papers/arxiv/attention-calibration-disentangled-text-to-image-personalization">Attention Calibration</a>], [<a href="https://aimodels.fyi/papers/arxiv/maxfusion-plugandplay-multi-modal-generation-text-to">MaxFusion</a>], [<a href="https://aimodels.fyi/papers/arxiv/mcdollar2dollar-multi-concept-guidance-customized-multi-concept">McDollar2Dollar</a>]. It also discusses work on customizing diffusion models for specific viewpoints [<a href="https://aimodels.fyi/papers/arxiv/customizing-text-to-image-diffusion-camera-viewpoint">Customizing Text-to-Image Diffusion for Camera Viewpoint</a>].
The key innovation in this paper is the "Infusion" training approach. The model has two parallel pathways - one that learns concept-agnostic representations, and one that learns concept-specific representations. During training, the model constantly switches between these two pathways, mixing the general and specific knowledge.
This is done through a series of "Infusion" steps, where the model takes intermediate feature representations from the two pathways and combines them. This prevents the model from overfitting to just the specific training data and helps it learn a more generalizable set of skills.
The paper evaluates this approach on several customized text-to-image generation benchmarks, showing that Infusion leads to improved performance, especially on unseen inputs, compared to standard training approaches.
Critical Analysis
The paper presents a thoughtful solution to an important problem in customized text-to-image models - the tendency to overfit to the specific training data. The "Infusion" technique seems well-designed to address this issue, drawing on insights from multi-task and meta-learning.
However, the paper does not deeply explore the limits or potential downsides of this approach. For example, it's unclear how well Infusion scales to an extremely large and diverse set of concepts, or whether there are any trade-offs in terms of sample efficiency or training time.
Additionally, the paper focuses primarily on quantitative performance metrics, but does not provide much qualitative analysis of the generated images. It would be valuable to understand how the Infusion-trained models differ in their creative outputs or ability to capture nuanced semantics, compared to standard approaches.
Overall, this is a promising direction, but further research is needed to fully understand the strengths, weaknesses, and broader implications of the Infusion technique.
Conclusion
This paper introduces a novel "Infusion" training approach to prevent customized text-to-image diffusion models from overfitting. By jointly learning concept-agnostic and concept-specific representations, and constantly blending them during training, the models are able to maintain strong generalization performance.
The results demonstrate the potential of this method to enable highly personalized text-to-image generation, while preserving broad capabilities. This could be an important advancement for applications where both customization and robustness are required. Further research is needed to fully explore the limits and nuances of this technique, but it represents a valuable step forward in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
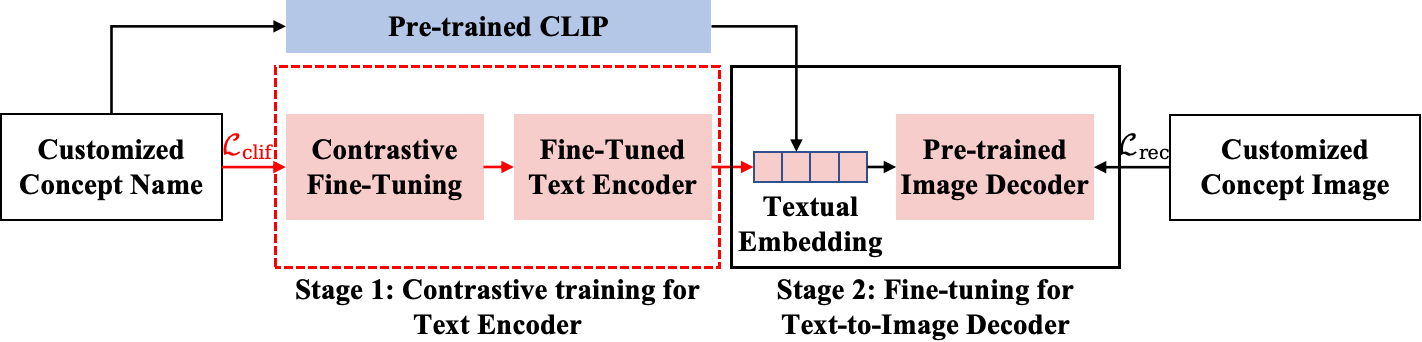
New!Non-confusing Generation of Customized Concepts in Diffusion Models
Wang Lin, Jingyuan Chen, Jiaxin Shi, Yichen Zhu, Chen Liang, Junzhong Miao, Tao Jin, Zhou Zhao, Fei Wu, Shuicheng Yan, Hanwang Zhang
0
0
We tackle the common challenge of inter-concept visual confusion in compositional concept generation using text-guided diffusion models (TGDMs). It becomes even more pronounced in the generation of customized concepts, due to the scarcity of user-provided concept visual examples. By revisiting the two major stages leading to the success of TGDMs -- 1) contrastive image-language pre-training (CLIP) for text encoder that encodes visual semantics, and 2) training TGDM that decodes the textual embeddings into pixels -- we point that existing customized generation methods only focus on fine-tuning the second stage while overlooking the first one. To this end, we propose a simple yet effective solution called CLIF: contrastive image-language fine-tuning. Specifically, given a few samples of customized concepts, we obtain non-confusing textual embeddings of a concept by fine-tuning CLIP via contrasting a concept and the over-segmented visual regions of other concepts. Experimental results demonstrate the effectiveness of CLIF in preventing the confusion of multi-customized concept generation.
5/14/2024
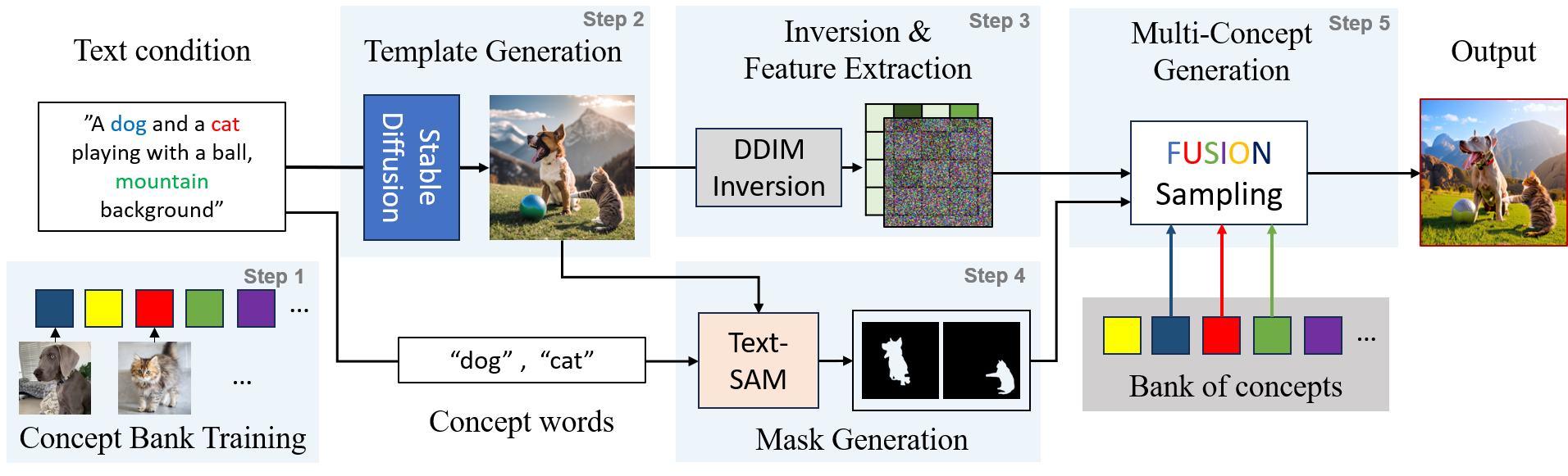
Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models
Gihyun Kwon, Simon Jenni, Dingzeyu Li, Joon-Young Lee, Jong Chul Ye, Fabian Caba Heilbron
0
0
While there has been significant progress in customizing text-to-image generation models, generating images that combine multiple personalized concepts remains challenging. In this work, we introduce Concept Weaver, a method for composing customized text-to-image diffusion models at inference time. Specifically, the method breaks the process into two steps: creating a template image aligned with the semantics of input prompts, and then personalizing the template using a concept fusion strategy. The fusion strategy incorporates the appearance of the target concepts into the template image while retaining its structural details. The results indicate that our method can generate multiple custom concepts with higher identity fidelity compared to alternative approaches. Furthermore, the method is shown to seamlessly handle more than two concepts and closely follow the semantic meaning of the input prompt without blending appearances across different subjects.
4/8/2024
🛸
Customization Assistant for Text-to-image Generation
Yufan Zhou, Ruiyi Zhang, Jiuxiang Gu, Tong Sun
0
0
Customizing pre-trained text-to-image generation model has attracted massive research interest recently, due to its huge potential in real-world applications. Although existing methods are able to generate creative content for a novel concept contained in single user-input image, their capability are still far from perfection. Specifically, most existing methods require fine-tuning the generative model on testing images. Some existing methods do not require fine-tuning, while their performance are unsatisfactory. Furthermore, the interaction between users and models are still limited to directive and descriptive prompts such as instructions and captions. In this work, we build a customization assistant based on pre-trained large language model and diffusion model, which can not only perform customized generation in a tuning-free manner, but also enable more user-friendly interactions: users can chat with the assistant and input either ambiguous text or clear instruction. Specifically, we propose a new framework consists of a new model design and a novel training strategy. The resulting assistant can perform customized generation in 2-5 seconds without any test time fine-tuning. Extensive experiments are conducted, competitive results have been obtained across different domains, illustrating the effectiveness of the proposed method.
5/10/2024

Attention Calibration for Disentangled Text-to-Image Personalization
Yanbing Zhang, Mengping Yang, Qin Zhou, Zhe Wang
0
0
Recent thrilling progress in large-scale text-to-image (T2I) models has unlocked unprecedented synthesis quality of AI-generated content (AIGC) including image generation, 3D and video composition. Further, personalized techniques enable appealing customized production of a novel concept given only several images as reference. However, an intriguing problem persists: Is it possible to capture multiple, novel concepts from one single reference image? In this paper, we identify that existing approaches fail to preserve visual consistency with the reference image and eliminate cross-influence from concepts. To alleviate this, we propose an attention calibration mechanism to improve the concept-level understanding of the T2I model. Specifically, we first introduce new learnable modifiers bound with classes to capture attributes of multiple concepts. Then, the classes are separated and strengthened following the activation of the cross-attention operation, ensuring comprehensive and self-contained concepts. Additionally, we suppress the attention activation of different classes to mitigate mutual influence among concepts. Together, our proposed method, dubbed DisenDiff, can learn disentangled multiple concepts from one single image and produce novel customized images with learned concepts. We demonstrate that our method outperforms the current state of the art in both qualitative and quantitative evaluations. More importantly, our proposed techniques are compatible with LoRA and inpainting pipelines, enabling more interactive experiences.
4/12/2024