Initial Exploration of Zero-Shot Privacy Utility Tradeoffs in Tabular Data Using GPT-4

0

Sign in to get full access
Overview
- This research paper explores the privacy-utility tradeoffs in using large language models (LLMs) like GPT-4 for tabular data tasks, taking a "zero-shot" approach that doesn't require model retraining.
- The researchers investigate how LLMs can be used to extract sensitive information from tabular data while maintaining utility for downstream tasks.
- They also consider the fairness implications of these privacy-utility tradeoffs, particularly when different groups have different privacy and utility preferences.
Plain English Explanation
The paper looks at how powerful language models like GPT-4 can be used to access private information in tabular data, while still keeping the data useful for other tasks. The researchers didn't need to retrain the models - they just used them "as-is" in a "zero-shot" way.
They wanted to understand the tradeoffs between protecting people's privacy and keeping the data useful. For example, if you tried to hide sensitive details, would that make the data less useful for things like predictions or analysis? And if different groups of people had different privacy needs, how could you balance that fairly?
The findings could help guide how we use advanced AI models like GPT-4 with real-world data, making sure we get the benefits while respecting people's privacy as much as possible. It's about finding the right balance and being thoughtful about the implications.
Technical Explanation
The paper explores "privacy-utility tradeoffs" in using large language models (LLMs) like GPT-4 for tasks involving tabular data. They take a "zero-shot" approach, which means they don't need to retrain the models.
The researchers investigate how LLMs can be used to "extract sensitive information" from tabular data while still maintaining utility for downstream tasks. They also consider the "fairness implications" of these privacy-utility tradeoffs, particularly when different groups have different privacy and utility preferences.
The team uses an "adversarial optimization" approach to explore this privacy-utility tradeoff space, generating adversarial examples that expose sensitive information while preserving task performance.
Critical Analysis
The paper provides a valuable initial exploration of a complex and timely issue - the privacy-utility tradeoffs when using powerful LLMs like GPT-4 on real-world data. However, the authors acknowledge that this is an initial study with limitations.
For example, the "zero-shot" approach may not capture the full complexity of how LLMs could be used in practice, where fine-tuning or other techniques might be employed. The fairness analysis is also limited in scope and would benefit from deeper investigation.
Additionally, the paper does not address potential mitigation strategies or broader societal implications in depth. Further research is needed to better understand how to responsibly deploy these technologies while protecting individual privacy and ensuring equitable outcomes.
Conclusion
This research represents an important first step in understanding the privacy-utility tradeoffs when using large language models like GPT-4 on sensitive tabular data. The findings highlight the need for continued careful study and responsible development of these powerful AI technologies.
As LLMs become more capable and widely adopted, proactively addressing privacy and fairness concerns will be crucial. This work lays the groundwork for further research and discussion on how to harness the benefits of these models while mitigating potential harms to individuals and communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Initial Exploration of Zero-Shot Privacy Utility Tradeoffs in Tabular Data Using GPT-4
Bishwas Mandal, George Amariucai, Shuangqing Wei
We investigate the application of large language models (LLMs), specifically GPT-4, to scenarios involving the tradeoff between privacy and utility in tabular data. Our approach entails prompting GPT-4 by transforming tabular data points into textual format, followed by the inclusion of precise sanitization instructions in a zero-shot manner. The primary objective is to sanitize the tabular data in such a way that it hinders existing machine learning models from accurately inferring private features while allowing models to accurately infer utility-related attributes. We explore various sanitization instructions. Notably, we discover that this relatively simple approach yields performance comparable to more complex adversarial optimization methods used for managing privacy-utility tradeoffs. Furthermore, while the prompts successfully obscure private features from the detection capabilities of existing machine learning models, we observe that this obscuration alone does not necessarily meet a range of fairness metrics. Nevertheless, our research indicates the potential effectiveness of LLMs in adhering to these fairness metrics, with some of our experimental results aligning with those achieved by well-established adversarial optimization techniques.
Read more4/9/2024

0
Can Large Language Models Automatically Jailbreak GPT-4V?
Yuanwei Wu, Yue Huang, Yixin Liu, Xiang Li, Pan Zhou, Lichao Sun
GPT-4V has attracted considerable attention due to its extraordinary capacity for integrating and processing multimodal information. At the same time, its ability of face recognition raises new safety concerns of privacy leakage. Despite researchers' efforts in safety alignment through RLHF or preprocessing filters, vulnerabilities might still be exploited. In our study, we introduce AutoJailbreak, an innovative automatic jailbreak technique inspired by prompt optimization. We leverage Large Language Models (LLMs) for red-teaming to refine the jailbreak prompt and employ weak-to-strong in-context learning prompts to boost efficiency. Furthermore, we present an effective search method that incorporates early stopping to minimize optimization time and token expenditure. Our experiments demonstrate that AutoJailbreak significantly surpasses conventional methods, achieving an Attack Success Rate (ASR) exceeding 95.3%. This research sheds light on strengthening GPT-4V security, underscoring the potential for LLMs to be exploited in compromising GPT-4V integrity.
Read more8/26/2024

0
Anomaly Detection of Tabular Data Using LLMs
Aodong Li, Yunhan Zhao, Chen Qiu, Marius Kloft, Padhraic Smyth, Maja Rudolph, Stephan Mandt
Large language models (LLMs) have shown their potential in long-context understanding and mathematical reasoning. In this paper, we study the problem of using LLMs to detect tabular anomalies and show that pre-trained LLMs are zero-shot batch-level anomaly detectors. That is, without extra distribution-specific model fitting, they can discover hidden outliers in a batch of data, demonstrating their ability to identify low-density data regions. For LLMs that are not well aligned with anomaly detection and frequently output factual errors, we apply simple yet effective data-generating processes to simulate synthetic batch-level anomaly detection datasets and propose an end-to-end fine-tuning strategy to bring out the potential of LLMs in detecting real anomalies. Experiments on a large anomaly detection benchmark (ODDS) showcase i) GPT-4 has on-par performance with the state-of-the-art transductive learning-based anomaly detection methods and ii) the efficacy of our synthetic dataset and fine-tuning strategy in aligning LLMs to this task.
Read more6/26/2024
0
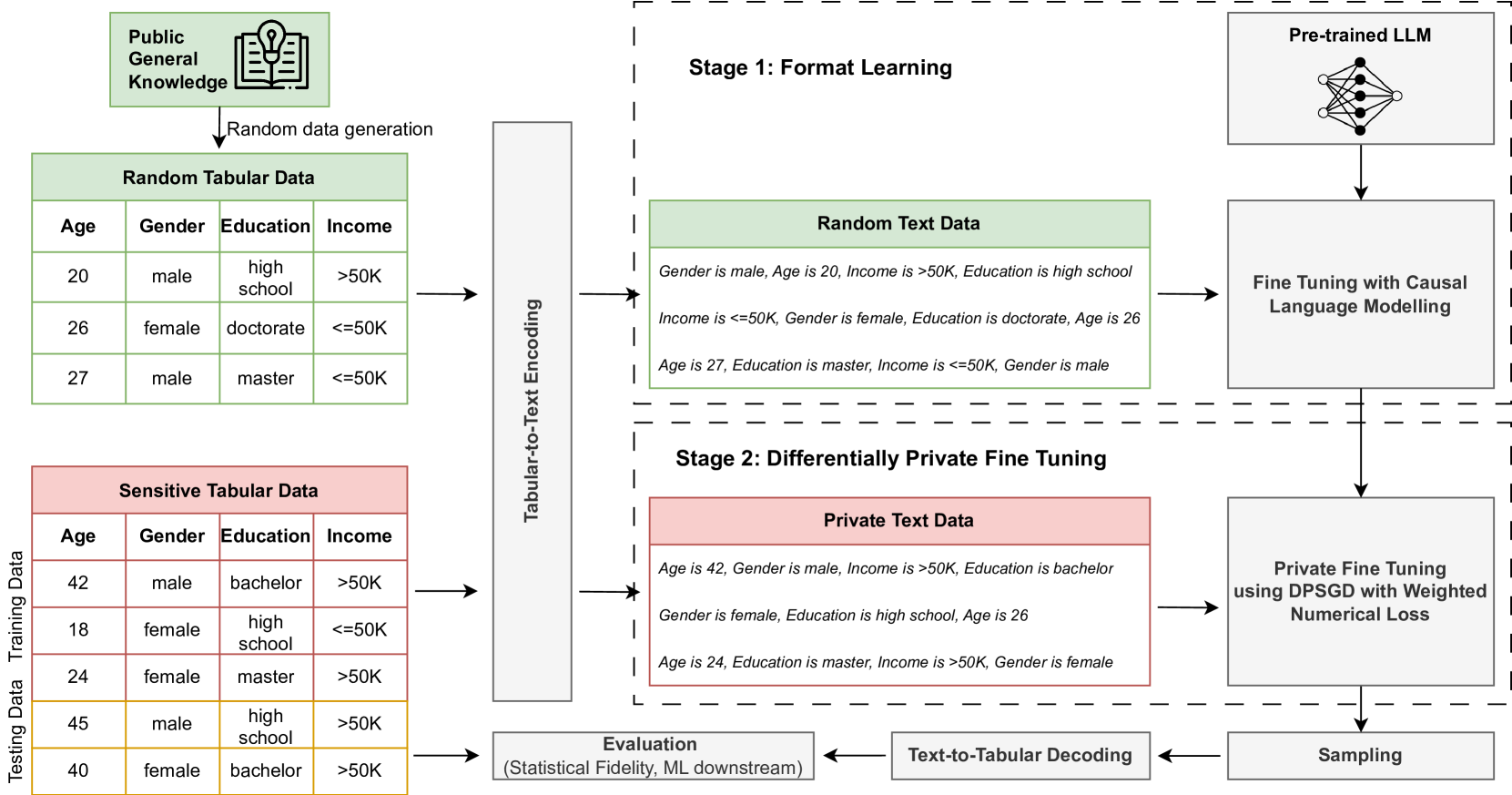
Differentially Private Tabular Data Synthesis using Large Language Models
Toan V. Tran, Li Xiong
Synthetic tabular data generation with differential privacy is a crucial problem to enable data sharing with formal privacy. Despite a rich history of methodological research and development, developing differentially private tabular data generators that can provide realistic synthetic datasets remains challenging. This paper introduces DP-LLMTGen -- a novel framework for differentially private tabular data synthesis that leverages pretrained large language models (LLMs). DP-LLMTGen models sensitive datasets using a two-stage fine-tuning procedure with a novel loss function specifically designed for tabular data. Subsequently, it generates synthetic data through sampling the fine-tuned LLMs. Our empirical evaluation demonstrates that DP-LLMTGen outperforms a variety of existing mechanisms across multiple datasets and privacy settings. Additionally, we conduct an ablation study and several experimental analyses to deepen our understanding of LLMs in addressing this important problem. Finally, we highlight the controllable generation ability of DP-LLMTGen through a fairness-constrained generation setting.
Read more6/4/2024