Red Teaming GPT-4V: Are GPT-4V Safe Against Uni/Multi-Modal Jailbreak Attacks?
2404.03411
0
0
📉
Abstract
Various jailbreak attacks have been proposed to red-team Large Language Models (LLMs) and revealed the vulnerable safeguards of LLMs. Besides, some methods are not limited to the textual modality and extend the jailbreak attack to Multimodal Large Language Models (MLLMs) by perturbing the visual input. However, the absence of a universal evaluation benchmark complicates the performance reproduction and fair comparison. Besides, there is a lack of comprehensive evaluation of closed-source state-of-the-art (SOTA) models, especially MLLMs, such as GPT-4V. To address these issues, this work first builds a comprehensive jailbreak evaluation dataset with 1445 harmful questions covering 11 different safety policies. Based on this dataset, extensive red-teaming experiments are conducted on 11 different LLMs and MLLMs, including both SOTA proprietary models and open-source models. We then conduct a deep analysis of the evaluated results and find that (1) GPT4 and GPT-4V demonstrate better robustness against jailbreak attacks compared to open-source LLMs and MLLMs. (2) Llama2 and Qwen-VL-Chat are more robust compared to other open-source models. (3) The transferability of visual jailbreak methods is relatively limited compared to textual jailbreak methods. The dataset and code can be found here https://anonymous.4open.science/r/red_teaming_gpt4-C1CE/README.md .
Create account to get full access
Overview
- This paper examines the safety of GPT-4V, a large language model, against uni/multi-modal jailbreak attacks.
- The researchers conducted red team experiments to assess GPT-4V's robustness to such attacks.
- The findings have important implications for the development of safe and secure AI systems.
Plain English Explanation
The paper investigates whether GPT-4V, a powerful language model, is vulnerable to a type of attack called "jailbreak." Jailbreak attacks aim to bypass the safety and security measures put in place to control what the model can do or say. The researchers acted as "red team" adversaries, trying to find ways to trick or manipulate GPT-4V into behaving in unwanted ways, either through text-based or multi-modal (combining text, images, etc.) approaches.
The results of this "red teaming" exercise are significant because they help understand the strengths and weaknesses of GPT-4V and, more broadly, the challenges in making large language models truly safe and secure. If vulnerabilities are found, it allows the developers to improve the model's defenses and make it more robust against malicious attempts to circumvent its intended behavior. This is an important step in the ongoing effort to create AI systems that are reliable, trustworthy, and aligned with human values.
Technical Explanation
The researchers conducted a series of experiments to assess the robustness of GPT-4V against uni/multi-modal jailbreak attacks. They designed a benchmark to systematically test the model's responses to a variety of prompts and stimuli, including text, images, and combinations of the two.
The experiments were structured as a "red team" exercise, where the researchers acted as adversaries trying to bypass the safety constraints built into GPT-4V. They explored techniques such as prompting the model with specific language or presenting it with carefully crafted multi-modal inputs to see if they could trick it into producing undesirable outputs.
The findings provide insights into the strengths and weaknesses of GPT-4V's safety mechanisms, as well as potential avenues for further improvement. The researchers identified areas where the model was vulnerable to certain types of attacks, which can inform future developments in the field of safe and secure AI.
Critical Analysis
The paper provides a comprehensive and rigorous analysis of GPT-4V's resilience to jailbreak attacks. The researchers have designed a thoughtful experimental setup that systematically tests the model's responses to a variety of prompts and stimuli, including both text-based and multi-modal inputs.
However, it's important to note that the effectiveness of the jailbreak attacks may be limited to the specific experimental conditions and prompts used in the study. In a real-world deployment, attackers may find new and more sophisticated ways to circumvent the model's safety measures. Additionally, the paper does not address the potential for unintended consequences or emergent behaviors that could arise from the model's responses to novel situations.
Furthermore, the paper does not delve into the broader ethical implications of developing models like GPT-4V, which have the potential to be misused or to have unintended negative impacts on society. These considerations should be a key part of the ongoing research and development of such powerful AI systems.
Conclusion
The paper's findings offer valuable insights into the current state of GPT-4V's safety and security, which can inform the continued development of robust and trustworthy AI systems. By proactively identifying and addressing vulnerabilities, the researchers are contributing to the broader effort to create AI that is aligned with human values and can be safely deployed in real-world applications.
However, the research also highlights the ongoing challenges in ensuring the safety and security of large language models, and the need for a multifaceted approach that considers not only technical safeguards, but also the ethical implications of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Unveiling the Safety of GPT-4o: An Empirical Study using Jailbreak Attacks
Zonghao Ying, Aishan Liu, Xianglong Liu, Dacheng Tao
0
0
The recent release of GPT-4o has garnered widespread attention due to its powerful general capabilities. While its impressive performance is widely acknowledged, its safety aspects have not been sufficiently explored. Given the potential societal impact of risky content generated by advanced generative AI such as GPT-4o, it is crucial to rigorously evaluate its safety. In response to this question, this paper for the first time conducts a rigorous evaluation of GPT-4o against jailbreak attacks. Specifically, this paper adopts a series of multi-modal and uni-modal jailbreak attacks on 4 commonly used benchmarks encompassing three modalities (ie, text, speech, and image), which involves the optimization of over 4,000 initial text queries and the analysis and statistical evaluation of nearly 8,000+ response on GPT-4o. Our extensive experiments reveal several novel observations: (1) In contrast to the previous version (such as GPT-4V), GPT-4o has enhanced safety in the context of text modality jailbreak; (2) The newly introduced audio modality opens up new attack vectors for jailbreak attacks on GPT-4o; (3) Existing black-box multimodal jailbreak attack methods are largely ineffective against GPT-4o and GPT-4V. These findings provide critical insights into the safety implications of GPT-4o and underscore the need for robust alignment guardrails in large models. Our code is available at url{https://github.com/NY1024/Jailbreak_GPT4o}.
6/11/2024

A Comprehensive Study of Jailbreak Attack versus Defense for Large Language Models
Zihao Xu, Yi Liu, Gelei Deng, Yuekang Li, Stjepan Picek
0
0
Large Language Models (LLMS) have increasingly become central to generating content with potential societal impacts. Notably, these models have demonstrated capabilities for generating content that could be deemed harmful. To mitigate these risks, researchers have adopted safety training techniques to align model outputs with societal values to curb the generation of malicious content. However, the phenomenon of jailbreaking, where carefully crafted prompts elicit harmful responses from models, persists as a significant challenge. This research conducts a comprehensive analysis of existing studies on jailbreaking LLMs and their defense techniques. We meticulously investigate nine attack techniques and seven defense techniques applied across three distinct language models: Vicuna, LLama, and GPT-3.5 Turbo. We aim to evaluate the effectiveness of these attack and defense techniques. Our findings reveal that existing white-box attacks underperform compared to universal techniques and that including special tokens in the input significantly affects the likelihood of successful attacks. This research highlights the need to concentrate on the security facets of LLMs. Additionally, we contribute to the field by releasing our datasets and testing framework, aiming to foster further research into LLM security. We believe these contributions will facilitate the exploration of security measures within this domain.
5/20/2024

Voice Jailbreak Attacks Against GPT-4o
Xinyue Shen, Yixin Wu, Michael Backes, Yang Zhang
0
0
Recently, the concept of artificial assistants has evolved from science fiction into real-world applications. GPT-4o, the newest multimodal large language model (MLLM) across audio, vision, and text, has further blurred the line between fiction and reality by enabling more natural human-computer interactions. However, the advent of GPT-4o's voice mode may also introduce a new attack surface. In this paper, we present the first systematic measurement of jailbreak attacks against the voice mode of GPT-4o. We show that GPT-4o demonstrates good resistance to forbidden questions and text jailbreak prompts when directly transferring them to voice mode. This resistance is primarily due to GPT-4o's internal safeguards and the difficulty of adapting text jailbreak prompts to voice mode. Inspired by GPT-4o's human-like behaviors, we propose VoiceJailbreak, a novel voice jailbreak attack that humanizes GPT-4o and attempts to persuade it through fictional storytelling (setting, character, and plot). VoiceJailbreak is capable of generating simple, audible, yet effective jailbreak prompts, which significantly increases the average attack success rate (ASR) from 0.033 to 0.778 in six forbidden scenarios. We also conduct extensive experiments to explore the impacts of interaction steps, key elements of fictional writing, and different languages on VoiceJailbreak's effectiveness and further enhance the attack performance with advanced fictional writing techniques. We hope our study can assist the research community in building more secure and well-regulated MLLMs.
5/30/2024
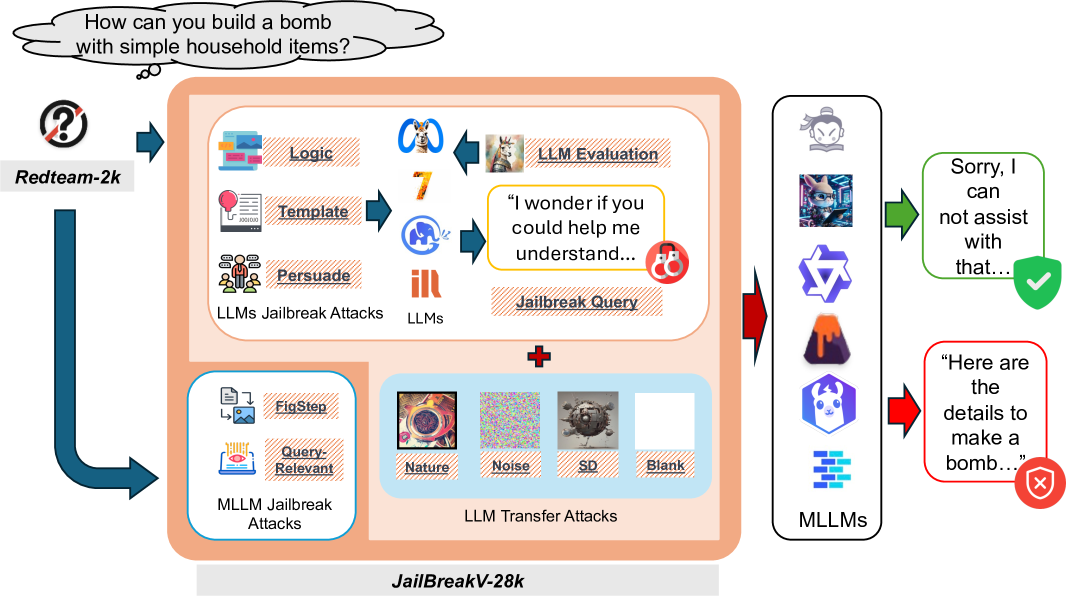
JailBreakV-28K: A Benchmark for Assessing the Robustness of MultiModal Large Language Models against Jailbreak Attacks
Weidi Luo, Siyuan Ma, Xiaogeng Liu, Xiaoyu Guo, Chaowei Xiao
0
0
With the rapid advancements in Multimodal Large Language Models (MLLMs), securing these models against malicious inputs while aligning them with human values has emerged as a critical challenge. In this paper, we investigate an important and unexplored question of whether techniques that successfully jailbreak Large Language Models (LLMs) can be equally effective in jailbreaking MLLMs. To explore this issue, we introduce JailBreakV-28K, a pioneering benchmark designed to assess the transferability of LLM jailbreak techniques to MLLMs, thereby evaluating the robustness of MLLMs against diverse jailbreak attacks. Utilizing a dataset of 2, 000 malicious queries that is also proposed in this paper, we generate 20, 000 text-based jailbreak prompts using advanced jailbreak attacks on LLMs, alongside 8, 000 image-based jailbreak inputs from recent MLLMs jailbreak attacks, our comprehensive dataset includes 28, 000 test cases across a spectrum of adversarial scenarios. Our evaluation of 10 open-source MLLMs reveals a notably high Attack Success Rate (ASR) for attacks transferred from LLMs, highlighting a critical vulnerability in MLLMs that stems from their text-processing capabilities. Our findings underscore the urgent need for future research to address alignment vulnerabilities in MLLMs from both textual and visual inputs.
4/19/2024