Optimizing Privacy and Utility Tradeoffs for Group Interests Through Harmonization
2404.05043
0
0
Abstract
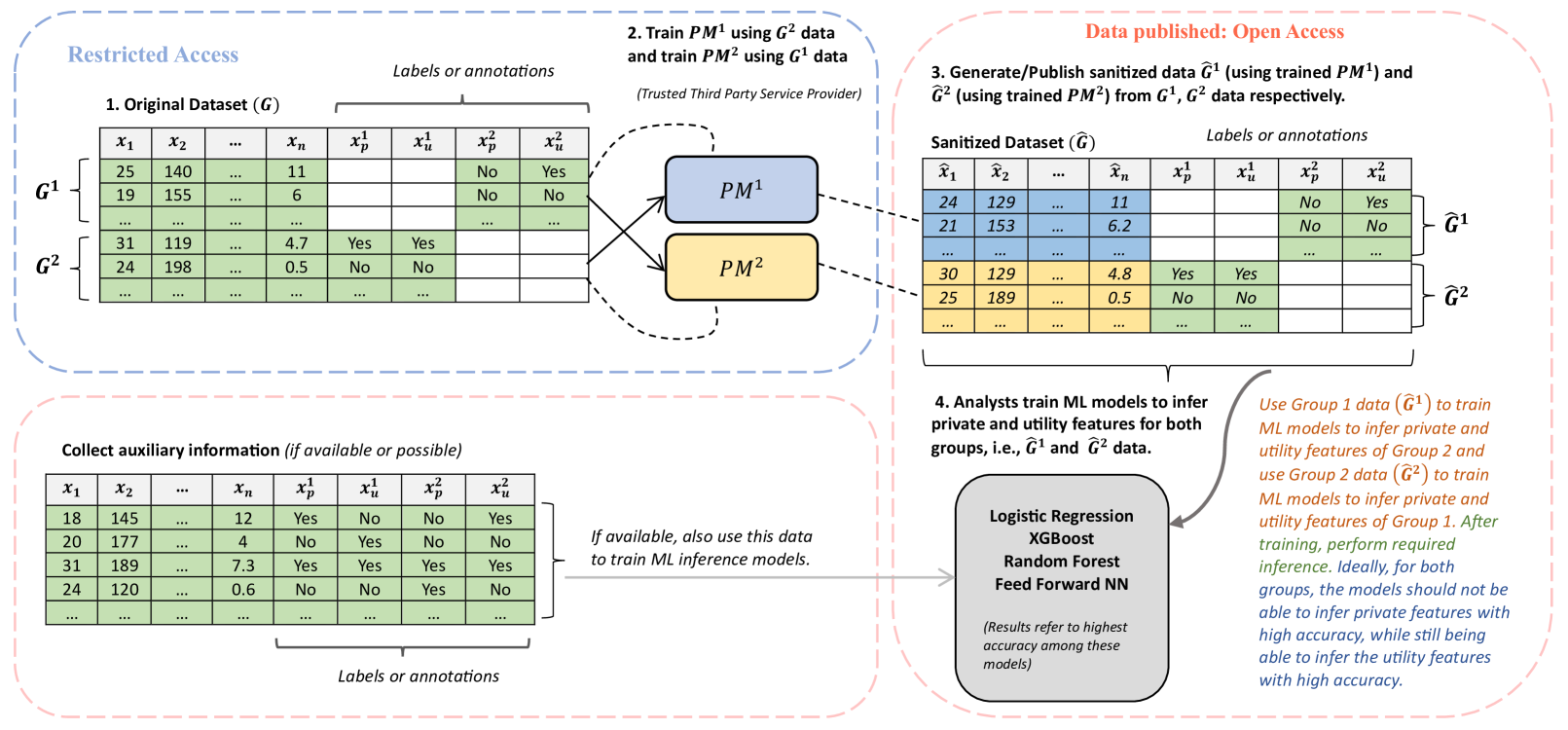
We propose a novel problem formulation to address the privacy-utility tradeoff, specifically when dealing with two distinct user groups characterized by unique sets of private and utility attributes. Unlike previous studies that primarily focus on scenarios where all users share identical private and utility attributes and often rely on auxiliary datasets or manual annotations, we introduce a collaborative data-sharing mechanism between two user groups through a trusted third party. This third party uses adversarial privacy techniques with our proposed data-sharing mechanism to internally sanitize data for both groups and eliminates the need for manual annotation or auxiliary datasets. Our methodology ensures that private attributes cannot be accurately inferred while enabling highly accurate predictions of utility features. Importantly, even if analysts or adversaries possess auxiliary datasets containing raw data, they are unable to accurately deduce private features. Additionally, our data-sharing mechanism is compatible with various existing adversarially trained privacy techniques. We empirically demonstrate the effectiveness of our approach using synthetic and real-world datasets, showcasing its ability to balance the conflicting goals of privacy and utility.
Create account to get full access
Overview
- Explores the challenge of balancing privacy and utility in group settings when publishing data
- Proposes a harmonization approach to optimize this tradeoff and protect group interests
- Utilizes adversarial optimization techniques to find the best privacy-utility balance
Plain English Explanation
This paper examines the delicate balance between protecting individual privacy and maintaining useful information when publishing data about groups of people. The researchers recognize that in many real-world scenarios, such as healthcare or education, there is a need to share data to drive important insights and decisions, but doing so can also risk revealing sensitive personal information.
To address this challenge, the researchers propose a harmonization approach that aims to find the optimal tradeoff between privacy and utility. By using adversarial optimization techniques, the method seeks to protect the collective interests of the group, rather than focusing solely on individual privacy or data usefulness.
The key idea is to create a system that can automatically adjust the published data to maximize its value for analysis and decision-making, while also minimizing the risk of sensitive information being exposed. This allows organizations to share insights from group data in a way that respects the privacy concerns of the individuals involved.
Technical Explanation
The paper presents a framework for optimizing the privacy-utility tradeoff in group settings when publishing data. The researchers introduce a harmonization approach that uses adversarial optimization to find the best balance between protecting group privacy and maintaining the utility of the published data.
The key steps of the framework are:
- Defining a privacy metric to quantify the risk of individual re-identification from the published data
- Specifying a utility metric that captures the analytical value of the data
- Formulating an adversarial optimization problem to simultaneously minimize privacy risk and maximize utility
The researchers demonstrate the effectiveness of their approach through experimental evaluations on real-world datasets, showing that it can achieve better privacy-utility tradeoffs compared to baseline methods.
Critical Analysis
The paper provides a promising approach for addressing the challenging problem of balancing privacy and utility in group data publishing. By considering the collective interests of the group, rather than focusing solely on individual privacy or data usefulness, the proposed harmonization method offers a more nuanced and practical solution.
However, the paper does not fully address the potential difficulties in defining appropriate privacy and utility metrics, which can be highly context-dependent and subjective. Additionally, the adversarial optimization framework may be computationally intensive, particularly for large-scale datasets, and its performance could be sensitive to the specific choice of optimization algorithms and hyperparameters.
Further research is needed to explore the scalability and robustness of the harmonization approach, as well as to investigate potential biases or unintended consequences that may arise from the optimization process. It would also be valuable to conduct user studies to better understand the real-world preferences and concerns of individuals and groups when it comes to balancing privacy and utility in data publishing.
Conclusion
This paper presents a novel approach for optimizing the privacy-utility tradeoff in group data publishing. By proposing a harmonization framework that uses adversarial optimization to balance collective interests, the researchers offer a promising solution to a longstanding challenge in the field of data privacy and utility.
While the proposed method has some limitations and areas for further development, the paper's core ideas and insights could have significant implications for a wide range of applications, from healthcare and education to social policy and urban planning, where the responsible sharing of group data is crucial for driving informed decision-making and positive societal outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Group Decision-Making among Privacy-Aware Agents
Marios Papachristou, M. Amin Rahimian
0
0
How can individuals exchange information to learn from each other despite their privacy needs and security concerns? For example, consider individuals deliberating a contentious topic and being concerned about divulging their private experiences. Preserving individual privacy and enabling efficient social learning are both important desiderata but seem fundamentally at odds with each other and very hard to reconcile. We do so by controlling information leakage using rigorous statistical guarantees that are based on differential privacy (DP). Our agents use log-linear rules to update their beliefs after communicating with their neighbors. Adding DP randomization noise to beliefs provides communicating agents with plausible deniability with regard to their private information and their network neighborhoods. We consider two learning environments one for distributed maximum-likelihood estimation given a finite number of private signals and another for online learning from an infinite, intermittent signal stream. Noisy information aggregation in the finite case leads to interesting tradeoffs between rejecting low-quality states and making sure all high-quality states are accepted in the algorithm output. Our results flesh out the nature of the trade-offs in both cases between the quality of the group decision outcomes, learning accuracy, communication cost, and the level of privacy protections that the agents are afforded.
4/12/2024

MaSS: Multi-attribute Selective Suppression for Utility-preserving Data Transformation from an Information-theoretic Perspective
Yizhuo Chen, Chun-Fu Chen, Hsiang Hsu, Shaohan Hu, Marco Pistoia, Tarek Abdelzaher
0
0
The growing richness of large-scale datasets has been crucial in driving the rapid advancement and wide adoption of machine learning technologies. The massive collection and usage of data, however, pose an increasing risk for people's private and sensitive information due to either inadvertent mishandling or malicious exploitation. Besides legislative solutions, many technical approaches have been proposed towards data privacy protection. However, they bear various limitations such as leading to degraded data availability and utility, or relying on heuristics and lacking solid theoretical bases. To overcome these limitations, we propose a formal information-theoretic definition for this utility-preserving privacy protection problem, and design a data-driven learnable data transformation framework that is capable of selectively suppressing sensitive attributes from target datasets while preserving the other useful attributes, regardless of whether or not they are known in advance or explicitly annotated for preservation. We provide rigorous theoretical analyses on the operational bounds for our framework, and carry out comprehensive experimental evaluations using datasets of a variety of modalities, including facial images, voice audio clips, and human activity motion sensor signals. Results demonstrate the effectiveness and generalizability of our method under various configurations on a multitude of tasks.
5/27/2024

Initial Exploration of Zero-Shot Privacy Utility Tradeoffs in Tabular Data Using GPT-4
Bishwas Mandal, George Amariucai, Shuangqing Wei
0
0
We investigate the application of large language models (LLMs), specifically GPT-4, to scenarios involving the tradeoff between privacy and utility in tabular data. Our approach entails prompting GPT-4 by transforming tabular data points into textual format, followed by the inclusion of precise sanitization instructions in a zero-shot manner. The primary objective is to sanitize the tabular data in such a way that it hinders existing machine learning models from accurately inferring private features while allowing models to accurately infer utility-related attributes. We explore various sanitization instructions. Notably, we discover that this relatively simple approach yields performance comparable to more complex adversarial optimization methods used for managing privacy-utility tradeoffs. Furthermore, while the prompts successfully obscure private features from the detection capabilities of existing machine learning models, we observe that this obscuration alone does not necessarily meet a range of fairness metrics. Nevertheless, our research indicates the potential effectiveness of LLMs in adhering to these fairness metrics, with some of our experimental results aligning with those achieved by well-established adversarial optimization techniques.
4/9/2024
🗣️
Utility-Fairness Trade-Offs and How to Find Them
Sepehr Dehdashtian, Bashir Sadeghi, Vishnu Naresh Boddeti
0
0
When building classification systems with demographic fairness considerations, there are two objectives to satisfy: 1) maximizing utility for the specific task and 2) ensuring fairness w.r.t. a known demographic attribute. These objectives often compete, so optimizing both can lead to a trade-off between utility and fairness. While existing works acknowledge the trade-offs and study their limits, two questions remain unanswered: 1) What are the optimal trade-offs between utility and fairness? and 2) How can we numerically quantify these trade-offs from data for a desired prediction task and demographic attribute of interest? This paper addresses these questions. We introduce two utility-fairness trade-offs: the Data-Space and Label-Space Trade-off. The trade-offs reveal three regions within the utility-fairness plane, delineating what is fully and partially possible and impossible. We propose U-FaTE, a method to numerically quantify the trade-offs for a given prediction task and group fairness definition from data samples. Based on the trade-offs, we introduce a new scheme for evaluating representations. An extensive evaluation of fair representation learning methods and representations from over 1000 pre-trained models revealed that most current approaches are far from the estimated and achievable fairness-utility trade-offs across multiple datasets and prediction tasks.
4/16/2024