InitNO: Boosting Text-to-Image Diffusion Models via Initial Noise Optimization
2404.04650
0
0

Abstract
Recent strides in the development of diffusion models, exemplified by advancements such as Stable Diffusion, have underscored their remarkable prowess in generating visually compelling images. However, the imperative of achieving a seamless alignment between the generated image and the provided prompt persists as a formidable challenge. This paper traces the root of these difficulties to invalid initial noise, and proposes a solution in the form of Initial Noise Optimization (InitNO), a paradigm that refines this noise. Considering text prompts, not all random noises are effective in synthesizing semantically-faithful images. We design the cross-attention response score and the self-attention conflict score to evaluate the initial noise, bifurcating the initial latent space into valid and invalid sectors. A strategically crafted noise optimization pipeline is developed to guide the initial noise towards valid regions. Our method, validated through rigorous experimentation, shows a commendable proficiency in generating images in strict accordance with text prompts. Our code is available at https://github.com/xiefan-guo/initno.
Create account to get full access
Overview
- This paper introduces a new technique called InitNO (Initial Noise Optimization) that can boost the performance of text-to-image diffusion models.
- Diffusion models are a type of generative AI that can create realistic images from text descriptions, but their performance can be limited by the initial noise used as input.
- InitNO optimizes the initial noise to better align with the target image, leading to improved image quality and coherence.
Plain English Explanation
InitNO: Boosting Text-to-Image Diffusion Models via Initial Noise Optimization is a technique that can make text-to-image AI systems better at generating high-quality images. These AI systems, called diffusion models, work by starting with random noise and then gradually transforming it into an image that matches a text description.
The key insight behind InitNO is that the initial random noise used as input to the diffusion model has a big impact on the final image quality. By optimizing this initial noise to better match the target image, the diffusion model can produce images that are more detailed, coherent, and faithful to the text prompt.
Imagine you're trying to draw a picture of a dog based on a written description. If you start with a completely random scribble, it will be very difficult to end up with an accurate drawing of the dog. But if you start with an initial sketch that already captures some of the key features - the general shape, the placement of the eyes and ears, etc. - it will be much easier to refine that into the final image. That's the basic idea behind InitNO.
The paper demonstrates that InitNO can lead to significant improvements in the quality and coherence of the images generated by diffusion models, without requiring any changes to the underlying model architecture. This makes it a versatile and easy-to-apply technique for boosting the performance of these powerful text-to-image AI systems.
Technical Explanation
The key innovation in InitNO: Boosting Text-to-Image Diffusion Models via Initial Noise Optimization is the use of an optimization procedure to generate the initial noise input to a text-to-image diffusion model. Diffusion models work by starting with random noise and then gradually transforming it into an image that matches a given text description.
The authors hypothesize that the quality of the final generated image is heavily influenced by the characteristics of the initial noise. By optimizing this initial noise to better align with the target image, the diffusion model can produce higher-quality and more coherent outputs.
To implement InitNO, the authors introduce an additional optimization step prior to the diffusion process. They define a loss function that measures the similarity between the initial noise and the target image, and then use gradient-based optimization to find an initial noise pattern that minimizes this loss. This optimized noise is then used as the starting point for the standard diffusion process.
The paper demonstrates the effectiveness of InitNO through extensive experiments on several text-to-image diffusion models and datasets. The results show that InitNO can significantly improve image quality, coherence, and fidelity to the text prompt, without requiring any changes to the underlying diffusion model architecture.
Critical Analysis
The InitNO paper presents a compelling and well-executed approach to boosting the performance of text-to-image diffusion models. However, there are a few potential limitations and areas for further research worth considering:
-
Generalization Capabilities: While the paper demonstrates strong results on the evaluated datasets, it's unclear how well InitNO would generalize to a wider range of text prompts and image domains. Further testing on more diverse datasets would help assess the broader applicability of this technique.
-
Computational Overhead: The additional optimization step introduced by InitNO adds computational complexity to the diffusion process. The authors mention that this overhead is relatively small, but the impact on inference time and resource requirements should be carefully considered, especially for real-time or deployment-focused applications.
-
Interaction with Diffusion Model Architecture: The paper treats the diffusion model as a black box and does not explore how InitNO might interact with different architectural choices or training regimes. Investigating these interactions could lead to further performance gains or insights into the underlying mechanisms.
Overall, the InitNO technique represents a promising approach to improving text-to-image diffusion models, and the authors have done a commendable job of demonstrating its effectiveness. Continued research in this direction, addressing the potential limitations, could lead to even more powerful and versatile text-to-image generation capabilities.
Conclusion
The InitNO paper introduces a novel technique for boosting the performance of text-to-image diffusion models. By optimizing the initial noise input to the diffusion process, the authors show that it's possible to generate higher-quality and more coherent images that better align with the given text descriptions.
This approach represents an important advancement in the field of text-to-image generation, as it allows for significant performance improvements without requiring changes to the underlying model architecture. As diffusion models continue to evolve and become more prominent, techniques like InitNO will be crucial for unlocking their full potential and enabling even more compelling and realistic image synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization
Luca Eyring, Shyamgopal Karthik, Karsten Roth, Alexey Dosovitskiy, Zeynep Akata
0
0
Text-to-Image (T2I) models have made significant advancements in recent years, but they still struggle to accurately capture intricate details specified in complex compositional prompts. While fine-tuning T2I models with reward objectives has shown promise, it suffers from reward hacking and may not generalize well to unseen prompt distributions. In this work, we propose Reward-based Noise Optimization (ReNO), a novel approach that enhances T2I models at inference by optimizing the initial noise based on the signal from one or multiple human preference reward models. Remarkably, solving this optimization problem with gradient ascent for 50 iterations yields impressive results on four different one-step models across two competitive benchmarks, T2I-CompBench and GenEval. Within a computational budget of 20-50 seconds, ReNO-enhanced one-step models consistently surpass the performance of all current open-source Text-to-Image models. Extensive user studies demonstrate that our model is preferred nearly twice as often compared to the popular SDXL model and is on par with the proprietary Stable Diffusion 3 with 8B parameters. Moreover, given the same computational resources, a ReNO-optimized one-step model outperforms widely-used open-source models such as SDXL and PixArt-$alpha$, highlighting the efficiency and effectiveness of ReNO in enhancing T2I model performance at inference time. Code is available at https://github.com/ExplainableML/ReNO.
6/7/2024

Tuning-Free Alignment of Diffusion Models with Direct Noise Optimization
Zhiwei Tang, Jiangweizhi Peng, Jiasheng Tang, Mingyi Hong, Fan Wang, Tsung-Hui Chang
0
0
In this work, we focus on the alignment problem of diffusion models with a continuous reward function, which represents specific objectives for downstream tasks, such as improving human preference. The central goal of the alignment problem is to adjust the distribution learned by diffusion models such that the generated samples maximize the target reward function. We propose a novel alignment approach, named Direct Noise Optimization (DNO), that optimizes the injected noise during the sampling process of diffusion models. By design, DNO is tuning-free and prompt-agnostic, as the alignment occurs in an online fashion during generation. We rigorously study the theoretical properties of DNO and also propose variants to deal with non-differentiable reward functions. Furthermore, we identify that naive implementation of DNO occasionally suffers from the out-of-distribution reward hacking problem, where optimized samples have high rewards but are no longer in the support of the pretrained distribution. To remedy this issue, we leverage classical high-dimensional statistics theory and propose to augment the DNO loss with certain probability regularization. We conduct extensive experiments on several popular reward functions trained on human feedback data and demonstrate that the proposed DNO approach achieves state-of-the-art reward scores as well as high image quality, all within a reasonable time budget for generation.
5/30/2024

The Crystal Ball Hypothesis in diffusion models: Anticipating object positions from initial noise
Yuanhao Ban, Ruochen Wang, Tianyi Zhou, Boqing Gong, Cho-Jui Hsieh, Minhao Cheng
0
0
Diffusion models have achieved remarkable success in text-to-image generation tasks; however, the role of initial noise has been rarely explored. In this study, we identify specific regions within the initial noise image, termed trigger patches, that play a key role for object generation in the resulting images. Notably, these patches are ``universal'' and can be generalized across various positions, seeds, and prompts. To be specific, extracting these patches from one noise and injecting them into another noise leads to object generation in targeted areas. We identify these patches by analyzing the dispersion of object bounding boxes across generated images, leading to the development of a posterior analysis technique. Furthermore, we create a dataset consisting of Gaussian noises labeled with bounding boxes corresponding to the objects appearing in the generated images and train a detector that identifies these patches from the initial noise. To explain the formation of these patches, we reveal that they are outliers in Gaussian noise, and follow distinct distributions through two-sample tests. Finally, we find the misalignment between prompts and the trigger patch patterns can result in unsuccessful image generations. The study proposes a reject-sampling strategy to obtain optimal noise, aiming to improve prompt adherence and positional diversity in image generation.
6/5/2024
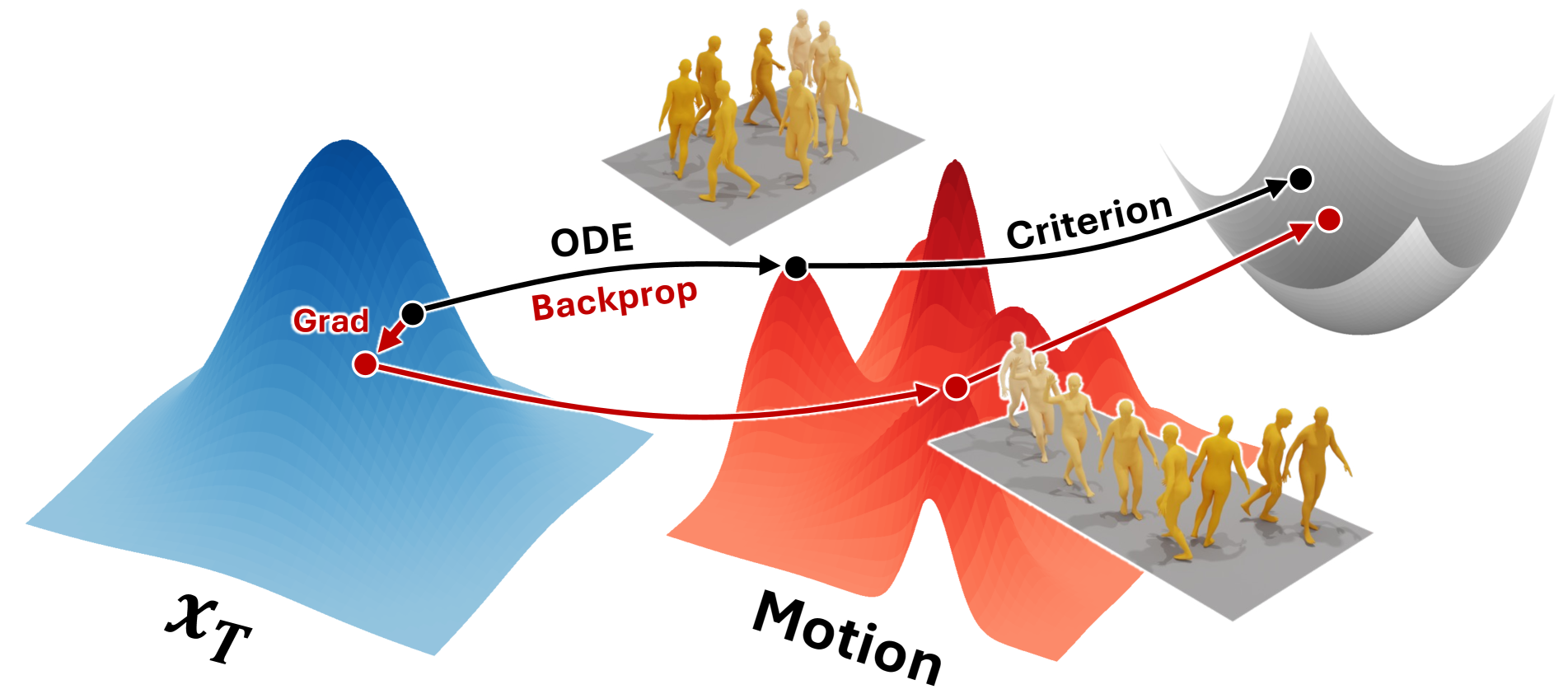
Optimizing Diffusion Noise Can Serve As Universal Motion Priors
Korrawe Karunratanakul, Konpat Preechakul, Emre Aksan, Thabo Beeler, Supasorn Suwajanakorn, Siyu Tang
0
0
We propose Diffusion Noise Optimization (DNO), a new method that effectively leverages existing motion diffusion models as motion priors for a wide range of motion-related tasks. Instead of training a task-specific diffusion model for each new task, DNO operates by optimizing the diffusion latent noise of an existing pre-trained text-to-motion model. Given the corresponding latent noise of a human motion, it propagates the gradient from the target criteria defined on the motion space through the whole denoising process to update the diffusion latent noise. As a result, DNO supports any use cases where criteria can be defined as a function of motion. In particular, we show that, for motion editing and control, DNO outperforms existing methods in both achieving the objective and preserving the motion content. DNO accommodates a diverse range of editing modes, including changing trajectory, pose, joint locations, or avoiding newly added obstacles. In addition, DNO is effective in motion denoising and completion, producing smooth and realistic motion from noisy and partial inputs. DNO achieves these results at inference time without the need for model retraining, offering great versatility for any defined reward or loss function on the motion representation.
4/4/2024