Tuning-Free Alignment of Diffusion Models with Direct Noise Optimization
2405.18881
0
0

Abstract
In this work, we focus on the alignment problem of diffusion models with a continuous reward function, which represents specific objectives for downstream tasks, such as improving human preference. The central goal of the alignment problem is to adjust the distribution learned by diffusion models such that the generated samples maximize the target reward function. We propose a novel alignment approach, named Direct Noise Optimization (DNO), that optimizes the injected noise during the sampling process of diffusion models. By design, DNO is tuning-free and prompt-agnostic, as the alignment occurs in an online fashion during generation. We rigorously study the theoretical properties of DNO and also propose variants to deal with non-differentiable reward functions. Furthermore, we identify that naive implementation of DNO occasionally suffers from the out-of-distribution reward hacking problem, where optimized samples have high rewards but are no longer in the support of the pretrained distribution. To remedy this issue, we leverage classical high-dimensional statistics theory and propose to augment the DNO loss with certain probability regularization. We conduct extensive experiments on several popular reward functions trained on human feedback data and demonstrate that the proposed DNO approach achieves state-of-the-art reward scores as well as high image quality, all within a reasonable time budget for generation.
Create account to get full access
Overview
- This paper introduces a novel approach called "Direct Noise Optimization" (DNO) for aligning diffusion models without the need for hyperparameter tuning.
- Diffusion models are a type of generative AI model that can generate realistic images, text, and other media by learning from large datasets.
- The key idea behind DNO is to directly optimize the model's noise prediction, rather than relying on indirect metrics like reconstruction loss or perceptual similarity.
- The authors demonstrate that DNO can achieve state-of-the-art performance on a variety of tasks, including text-to-image generation, without the need for extensive hyperparameter tuning.
Plain English Explanation
Diffusion models are a powerful type of AI that can create all sorts of media, like images and text, by learning from large datasets. However, training these models can be tricky and often requires a lot of trial and error to get the hyperparameters (the knobs and dials that control the model's behavior) just right.
The researchers behind this paper came up with a new approach called "Direct Noise Optimization" (DNO) that simplifies this process. Instead of fiddling with the hyperparameters, DNO focuses on directly optimizing the model's ability to predict the "noise" that's added to the data during the training process.
By optimizing the noise prediction, the researchers found they could achieve state-of-the-art performance on tasks like text-to-image generation without all the manual tuning. This is a big deal because it makes it easier for researchers and developers to use these powerful diffusion models in their own projects.
Technical Explanation
The core idea behind Direct Noise Optimization (DNO) is to directly optimize the diffusion model's ability to predict the noise that's added to the input data during the training process, rather than relying on indirect metrics like reconstruction loss or perceptual similarity.
The authors show that by optimizing the noise prediction, they can achieve state-of-the-art performance on a variety of tasks, including text-to-image generation, without the need for extensive hyperparameter tuning. This is in contrast to other approaches, such as Physics-Informed Diffusion Models or Direct Nash Optimization, which require more manual effort to find the right hyperparameters.
The authors evaluate DNO on a range of benchmarks, including Optimizing Diffusion Noise Can Serve as Universal and InitNo: Boosting Text-to-Image Diffusion Models, and demonstrate its ability to match or exceed the performance of other state-of-the-art approaches without the need for extensive tuning.
Critical Analysis
The authors present a compelling case for the effectiveness of Direct Noise Optimization (DNO) in aligning diffusion models. However, there are a few potential caveats to consider:
-
The paper focuses primarily on evaluating DNO on text-to-image generation tasks, so it's unclear how well the approach would generalize to other types of diffusion models, such as those used for speech or audio generation.
-
The authors acknowledge that DNO may be sensitive to the choice of noise schedule and other architectural details, so further research may be needed to understand the full scope of its applicability.
-
While DNO eliminates the need for manual hyperparameter tuning, it's possible that the optimization process itself could be computationally intensive, potentially limiting its practical use in some scenarios.
Overall, the paper makes a strong contribution to the field of diffusion models and offers a promising new approach for simplifying the training and alignment of these powerful AI systems.
Conclusion
The "Tuning-Free Alignment of Diffusion Models with Direct Noise Optimization" paper introduces a novel technique called Direct Noise Optimization (DNO) that can align diffusion models without the need for extensive hyperparameter tuning. By directly optimizing the model's ability to predict the noise added during training, the authors demonstrate that DNO can achieve state-of-the-art performance on a variety of tasks, including text-to-image generation, without the manual effort required by other approaches.
This work has the potential to significantly simplify the deployment of diffusion models in real-world applications, making it easier for researchers and developers to harness the power of these generative AI systems. While there are a few caveats to consider, the paper's compelling results and the broader implications of its approach make it an important contribution to the field of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
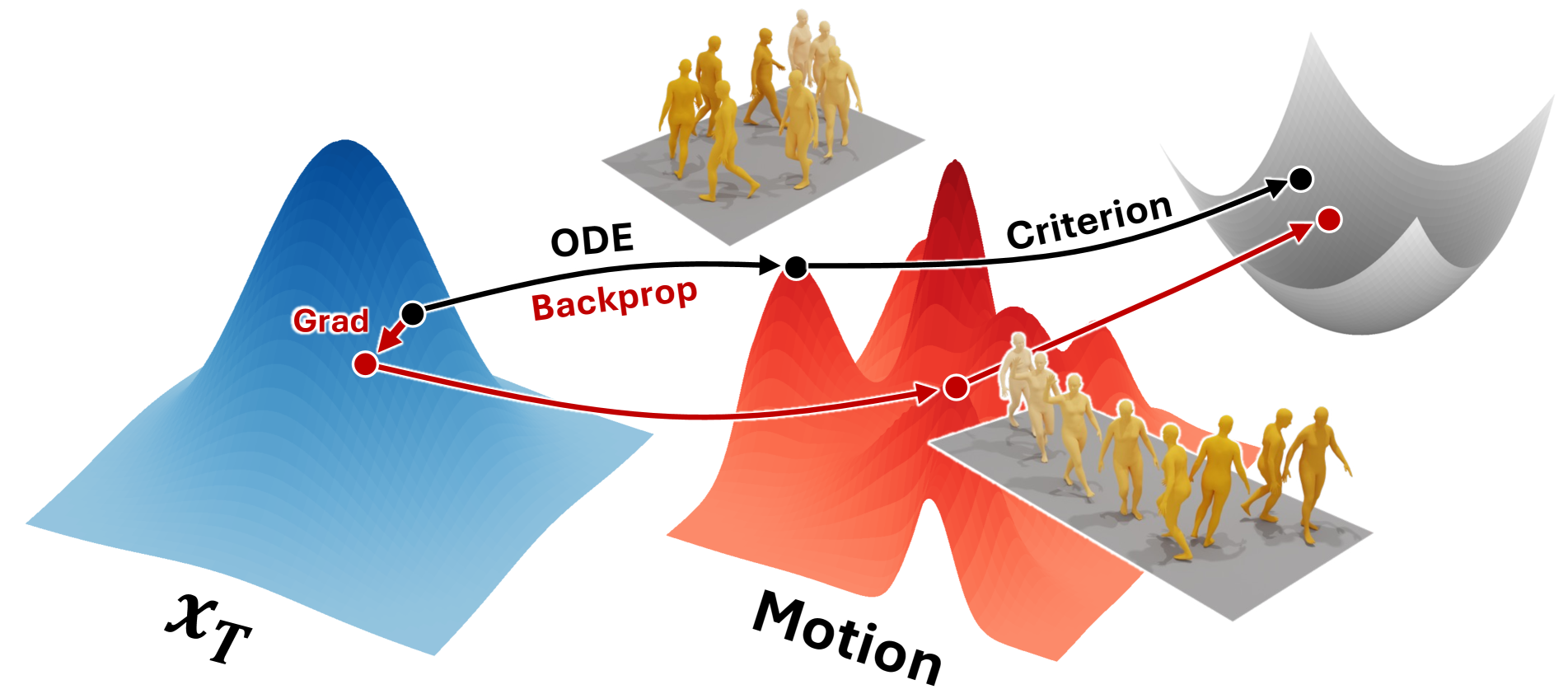
Optimizing Diffusion Noise Can Serve As Universal Motion Priors
Korrawe Karunratanakul, Konpat Preechakul, Emre Aksan, Thabo Beeler, Supasorn Suwajanakorn, Siyu Tang
0
0
We propose Diffusion Noise Optimization (DNO), a new method that effectively leverages existing motion diffusion models as motion priors for a wide range of motion-related tasks. Instead of training a task-specific diffusion model for each new task, DNO operates by optimizing the diffusion latent noise of an existing pre-trained text-to-motion model. Given the corresponding latent noise of a human motion, it propagates the gradient from the target criteria defined on the motion space through the whole denoising process to update the diffusion latent noise. As a result, DNO supports any use cases where criteria can be defined as a function of motion. In particular, we show that, for motion editing and control, DNO outperforms existing methods in both achieving the objective and preserving the motion content. DNO accommodates a diverse range of editing modes, including changing trajectory, pose, joint locations, or avoiding newly added obstacles. In addition, DNO is effective in motion denoising and completion, producing smooth and realistic motion from noisy and partial inputs. DNO achieves these results at inference time without the need for model retraining, offering great versatility for any defined reward or loss function on the motion representation.
4/4/2024
📊
Directly Fine-Tuning Diffusion Models on Differentiable Rewards
Kevin Clark, Paul Vicol, Kevin Swersky, David J Fleet
0
0
We present Direct Reward Fine-Tuning (DRaFT), a simple and effective method for fine-tuning diffusion models to maximize differentiable reward functions, such as scores from human preference models. We first show that it is possible to backpropagate the reward function gradient through the full sampling procedure, and that doing so achieves strong performance on a variety of rewards, outperforming reinforcement learning-based approaches. We then propose more efficient variants of DRaFT: DRaFT-K, which truncates backpropagation to only the last K steps of sampling, and DRaFT-LV, which obtains lower-variance gradient estimates for the case when K=1. We show that our methods work well for a variety of reward functions and can be used to substantially improve the aesthetic quality of images generated by Stable Diffusion 1.4. Finally, we draw connections between our approach and prior work, providing a unifying perspective on the design space of gradient-based fine-tuning algorithms.
6/24/2024
✅
Physics-Informed Diffusion Models
Jan-Hendrik Bastek, WaiChing Sun, Dennis M. Kochmann
0
0
Generative models such as denoising diffusion models are quickly advancing their ability to approximate highly complex data distributions. They are also increasingly leveraged in scientific machine learning, where samples from the implied data distribution are expected to adhere to specific governing equations. We present a framework to inform denoising diffusion models of underlying constraints on such generated samples during model training. Our approach improves the alignment of the generated samples with the imposed constraints and significantly outperforms existing methods without affecting inference speed. Additionally, our findings suggest that incorporating such constraints during training provides a natural regularization against overfitting. Our framework is easy to implement and versatile in its applicability for imposing equality and inequality constraints as well as auxiliary optimization objectives.
5/24/2024
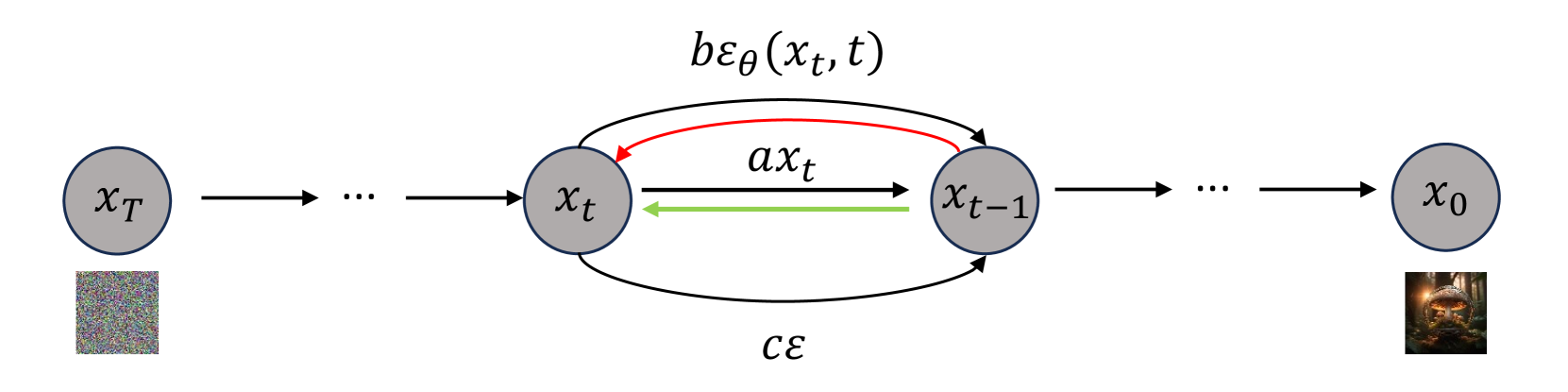
Deep Reward Supervisions for Tuning Text-to-Image Diffusion Models
Xiaoshi Wu, Yiming Hao, Manyuan Zhang, Keqiang Sun, Zhaoyang Huang, Guanglu Song, Yu Liu, Hongsheng Li
0
0
Optimizing a text-to-image diffusion model with a given reward function is an important but underexplored research area. In this study, we propose Deep Reward Tuning (DRTune), an algorithm that directly supervises the final output image of a text-to-image diffusion model and back-propagates through the iterative sampling process to the input noise. We find that training earlier steps in the sampling process is crucial for low-level rewards, and deep supervision can be achieved efficiently and effectively by stopping the gradient of the denoising network input. DRTune is extensively evaluated on various reward models. It consistently outperforms other algorithms, particularly for low-level control signals, where all shallow supervision methods fail. Additionally, we fine-tune Stable Diffusion XL 1.0 (SDXL 1.0) model via DRTune to optimize Human Preference Score v2.1, resulting in the Favorable Diffusion XL 1.0 (FDXL 1.0) model. FDXL 1.0 significantly enhances image quality compared to SDXL 1.0 and reaches comparable quality compared with Midjourney v5.2.
5/3/2024