INS-MMBench: A Comprehensive Benchmark for Evaluating LVLMs' Performance in Insurance

0
Sign in to get full access
Overview
- This paper introduces INS-MMBench, a comprehensive benchmark for evaluating the performance of Large Vision-Language Models (LVLMs) in the insurance domain.
- The benchmark consists of a diverse set of tasks and datasets that cover various aspects of insurance-related information processing, including document understanding, visual reasoning, and multi-modal question answering.
- The goal of INS-MMBench is to provide a standardized way to assess the capabilities of LVLMs in the insurance industry, which can help guide the development and deployment of these models in real-world applications.
Plain English Explanation
The paper presents a new benchmark called INS-MMBench that is designed to test the performance of large language models that can handle both text and images (known as Large Vision-Language Models or LVLMs) in the context of the insurance industry. The benchmark includes a variety of tasks and datasets that cover different aspects of how these models might be used in insurance, such as understanding insurance documents, answering questions about insurance information, and reasoning about visual elements related to insurance.
The main motivation behind this benchmark is to provide a standardized way for researchers and practitioners to evaluate the capabilities of LVLMs in the insurance domain. This can help guide the development and deployment of these models in real-world insurance applications, ensuring that they are effective and reliable tools for tasks like customer support, claims processing, and risk assessment.
Technical Explanation
The paper introduces INS-MMBench, a new benchmark designed to assess the performance of Large Vision-Language Models (LVLMs) in the insurance domain. The benchmark consists of a diverse set of tasks and datasets that cover various aspects of insurance-related information processing, including document understanding, visual reasoning, and multi-modal question answering.
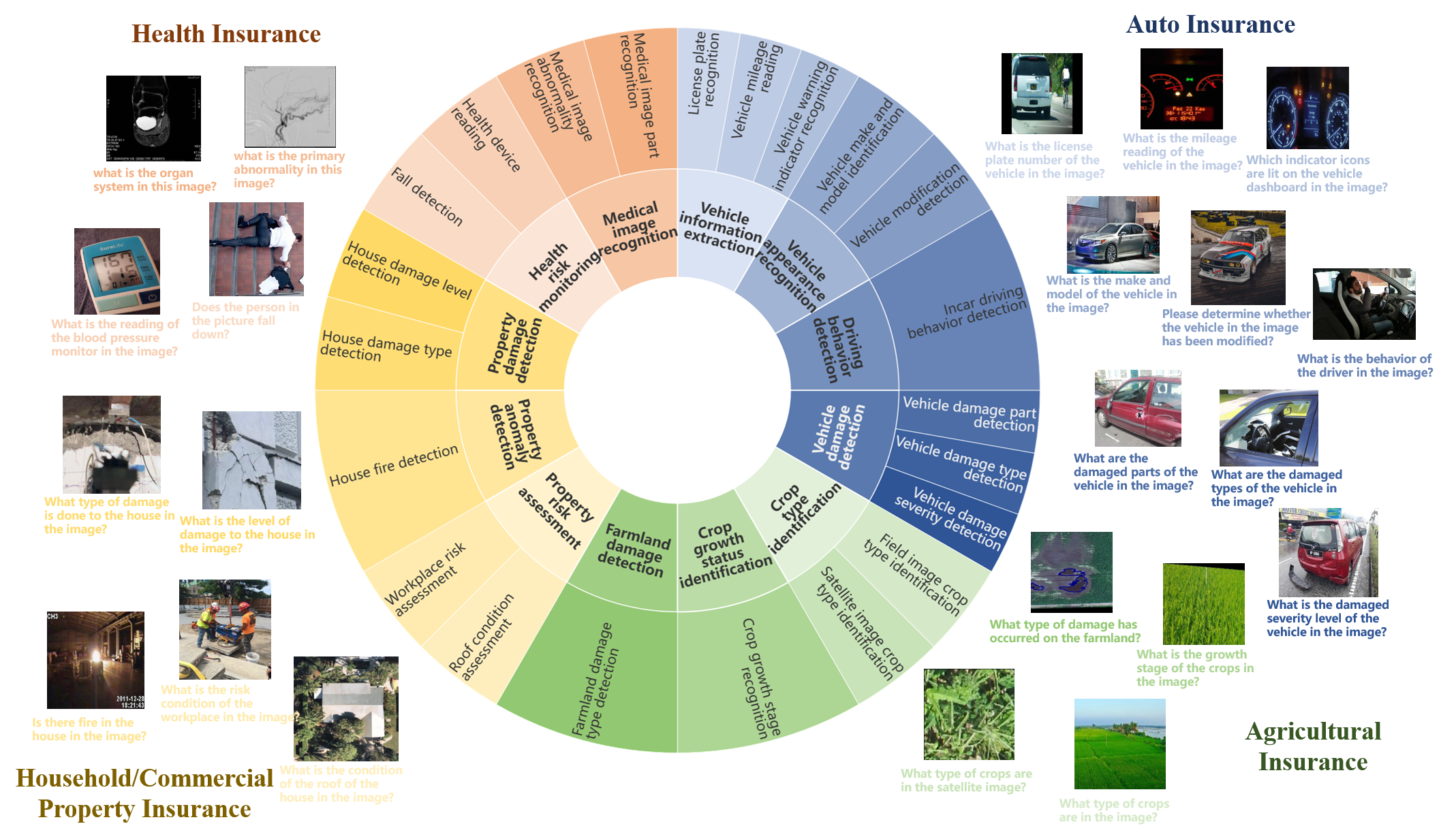
The tasks and datasets in INS-MMBench were carefully curated to reflect the real-world challenges faced by insurance providers and customers. For example, the document understanding task requires models to extract key information from insurance policy documents, while the visual reasoning task involves interpreting diagrams and images related to insurance concepts.
The benchmark also includes a multi-modal question answering task, which tests the ability of LVLMs to jointly process textual and visual information to answer questions about insurance-related scenarios. This task is designed to mimic the type of information-seeking behavior that insurance customers and professionals might engage in, where they need to combine different sources of information to make informed decisions.
By providing a standardized and comprehensive evaluation framework, the authors hope that INS-MMBench will help guide the development and deployment of LVLMs in the insurance industry, ensuring that these models are capable of handling the unique challenges and requirements of this domain.
Critical Analysis
The INS-MMBench framework represents a valuable contribution to the field of insurance-focused AI research, as it addresses a pressing need for robust and domain-specific evaluation tools. By targeting the unique challenges of the insurance industry, the benchmark encourages the development of LVLMs that are tailored to the specific needs and requirements of this sector.
One potential limitation of the benchmark is the diversity and size of the datasets used. While the authors have made efforts to curate a comprehensive set of tasks and datasets, the real-world insurance landscape is incredibly vast and complex, with a wide range of document types, visual elements, and information-seeking scenarios. It is possible that the benchmark may not fully capture the full breadth of insurance-related challenges that LVLMs may encounter in practice.
Additionally, the paper does not provide a detailed analysis of the performance of existing LVLM architectures on the INS-MMBench tasks. Such an analysis could help identify the strengths and weaknesses of current models, as well as guide future research and development efforts. Incorporating benchmarks like OmnimediaVQA and MileBench could also provide a more comprehensive evaluation of LVLMs' capabilities in the multi-modal domain.
Conclusion
The INS-MMBench benchmark represents a significant advancement in the field of insurance-focused AI research. By providing a standardized and comprehensive evaluation framework, the authors have created a valuable tool for assessing the capabilities of Large Vision-Language Models (LVLMs) in the insurance domain.
The benchmark's focus on tasks and datasets that reflect the real-world challenges faced by insurance providers and customers can help guide the development of LVLMs that are better suited to the unique requirements of this industry. As the adoption of these models continues to grow in the insurance sector, tools like INS-MMBench will become increasingly important for ensuring the reliability and effectiveness of AI-powered solutions.
While the benchmark has some limitations, it serves as an important step in the ongoing effort to harness the power of multi-modal language models in the insurance industry. By providing a standardized and comprehensive evaluation framework, INS-MMBench can help drive innovation and progress in this critical area of AI research and application.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
INS-MMBench: A Comprehensive Benchmark for Evaluating LVLMs' Performance in Insurance
Chenwei Lin, Hanjia Lyu, Xian Xu, Jiebo Luo
Large Vision-Language Models (LVLMs) have demonstrated outstanding performance in various general multimodal applications such as image recognition and visual reasoning, and have also shown promising potential in specialized domains. However, the application potential of LVLMs in the insurance domain-characterized by rich application scenarios and abundant multimodal data-has not been effectively explored. There is no systematic review of multimodal tasks in the insurance domain, nor a benchmark specifically designed to evaluate the capabilities of LVLMs in insurance. This gap hinders the development of LVLMs within the insurance domain. In this paper, we systematically review and distill multimodal tasks for four representative types of insurance: auto insurance, property insurance, health insurance, and agricultural insurance. We propose INS-MMBench, the first comprehensive LVLMs benchmark tailored for the insurance domain. INS-MMBench comprises a total of 2.2K thoroughly designed multiple-choice questions, covering 12 meta-tasks and 22 fundamental tasks. Furthermore, we evaluate multiple representative LVLMs, including closed-source models such as GPT-4o and open-source models like BLIP-2. This evaluation not only validates the effectiveness of our benchmark but also provides an in-depth performance analysis of current LVLMs on various multimodal tasks in the insurance domain. We hope that INS-MMBench will facilitate the further application of LVLMs in the insurance domain and inspire interdisciplinary development. Our dataset and evaluation code are available at https://github.com/FDU-INS/INS-MMBench.
Read more6/14/2024

0
GMAI-MMBench: A Comprehensive Multimodal Evaluation Benchmark Towards General Medical AI
Pengcheng Chen, Jin Ye, Guoan Wang, Yanjun Li, Zhongying Deng, Wei Li, Tianbin Li, Haodong Duan, Ziyan Huang, Yanzhou Su, Benyou Wang, Shaoting Zhang, Bin Fu, Jianfei Cai, Bohan Zhuang, Eric J Seibel, Junjun He, Yu Qiao
Large Vision-Language Models (LVLMs) are capable of handling diverse data types such as imaging, text, and physiological signals, and can be applied in various fields. In the medical field, LVLMs have a high potential to offer substantial assistance for diagnosis and treatment. Before that, it is crucial to develop benchmarks to evaluate LVLMs' effectiveness in various medical applications. Current benchmarks are often built upon specific academic literature, mainly focusing on a single domain, and lacking varying perceptual granularities. Thus, they face specific challenges, including limited clinical relevance, incomplete evaluations, and insufficient guidance for interactive LVLMs. To address these limitations, we developed the GMAI-MMBench, the most comprehensive general medical AI benchmark with well-categorized data structure and multi-perceptual granularity to date. It is constructed from 285 datasets across 39 medical image modalities, 18 clinical-related tasks, 18 departments, and 4 perceptual granularities in a Visual Question Answering (VQA) format. Additionally, we implemented a lexical tree structure that allows users to customize evaluation tasks, accommodating various assessment needs and substantially supporting medical AI research and applications. We evaluated 50 LVLMs, and the results show that even the advanced GPT-4o only achieves an accuracy of 52%, indicating significant room for improvement. Moreover, we identified five key insufficiencies in current cutting-edge LVLMs that need to be addressed to advance the development of better medical applications. We believe that GMAI-MMBench will stimulate the community to build the next generation of LVLMs toward GMAI.
Read more8/12/2024
🌀
0
Harnessing GPT-4V(ision) for Insurance: A Preliminary Exploration
Chenwei Lin, Hanjia Lyu, Jiebo Luo, Xian Xu
The emergence of Large Multimodal Models (LMMs) marks a significant milestone in the development of artificial intelligence. Insurance, as a vast and complex discipline, involves a wide variety of data forms in its operational processes, including text, images, and videos, thereby giving rise to diverse multimodal tasks. Despite this, there has been limited systematic exploration of multimodal tasks specific to insurance, nor a thorough investigation into how LMMs can address these challenges. In this paper, we explore GPT-4V's capabilities in the insurance domain. We categorize multimodal tasks by focusing primarily on visual aspects based on types of insurance (e.g., auto, household/commercial property, health, and agricultural insurance) and insurance stages (e.g., risk assessment, risk monitoring, and claims processing). Our experiment reveals that GPT-4V exhibits remarkable abilities in insurance-related tasks, demonstrating not only a robust understanding of multimodal content in the insurance domain but also a comprehensive knowledge of insurance scenarios. However, there are notable shortcomings: GPT-4V struggles with detailed risk rating and loss assessment, suffers from hallucination in image understanding, and shows variable support for different languages. Through this work, we aim to bridge the insurance domain with cutting-edge LMM technology, facilitate interdisciplinary exchange and development, and provide a foundation for the continued advancement and evolution of future research endeavors.
Read more4/16/2024
0
MIBench: Evaluating Multimodal Large Language Models over Multiple Images
Haowei Liu, Xi Zhang, Haiyang Xu, Yaya Shi, Chaoya Jiang, Ming Yan, Ji Zhang, Fei Huang, Chunfeng Yuan, Bing Li, Weiming Hu
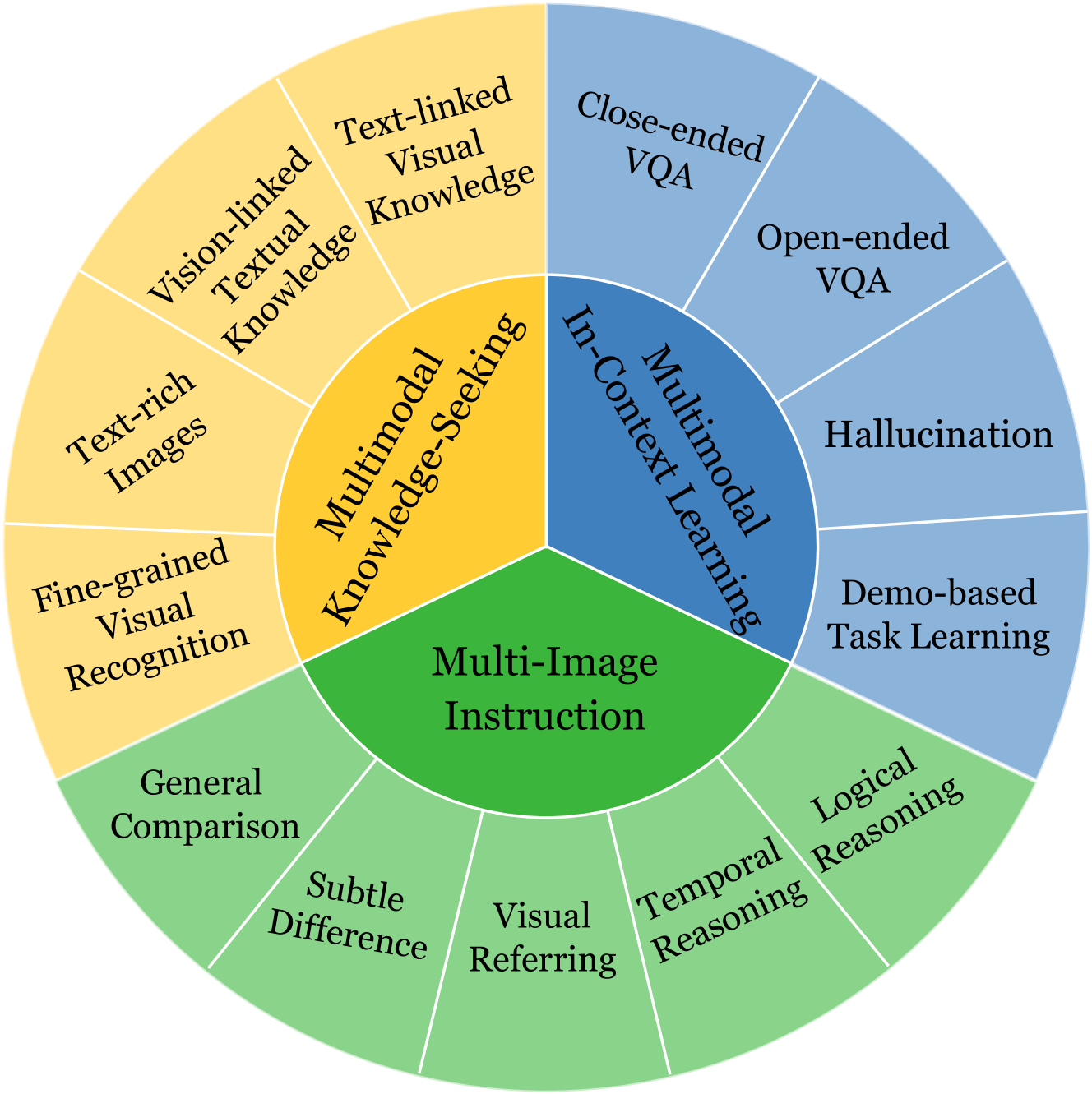
Built on the power of LLMs, numerous multimodal large language models (MLLMs) have recently achieved remarkable performance on various vision-language tasks across multiple benchmarks. However, most existing MLLMs and benchmarks primarily focus on single-image input scenarios, leaving the performance of MLLMs when handling realistic multiple images remain underexplored. Although a few benchmarks consider multiple images, their evaluation dimensions and samples are very limited. Therefore, in this paper, we propose a new benchmark MIBench, to comprehensively evaluate fine-grained abilities of MLLMs in multi-image scenarios. Specifically, MIBench categorizes the multi-image abilities into three scenarios: multi-image instruction (MII), multimodal knowledge-seeking (MKS) and multimodal in-context learning (MIC), and constructs 13 tasks with a total of 13K annotated samples. During data construction, for MII and MKS, we extract correct options from manual annotations and create challenging distractors to obtain multiple-choice questions. For MIC, to enable an in-depth evaluation, we set four sub-tasks and transform the original datasets into in-context learning formats. We evaluate several open-source MLLMs and close-source MLLMs on the proposed MIBench. The results reveal that although current models excel in single-image tasks, they exhibit significant shortcomings when faced with multi-image inputs, such as confused fine-grained perception, limited multi-image reasoning, and unstable in-context learning. The annotated data in MIBench is available at https://huggingface.co/datasets/StarBottle/MIBench.
Read more7/23/2024