MIBench: Evaluating Multimodal Large Language Models over Multiple Images

0
Sign in to get full access
Overview
- This paper introduces MIBench, a new benchmark for evaluating multimodal large language models on tasks involving multiple images.
- The benchmark includes a diverse set of tasks such as image-based question answering, image captioning, and reasoning about relationships between multiple images.
- The authors evaluate several state-of-the-art multimodal models on MIBench and provide insights into their strengths and limitations.
Plain English Explanation
The paper presents a new benchmark called MIBench for testing how well large language models that can work with both text and images perform on tasks that involve multiple images. These models, known as multimodal large language models (MMLLMs), are becoming increasingly capable at understanding and generating language in the context of visual information.
The MIBench benchmark includes a variety of tasks that require analyzing and reasoning about relationships between multiple images, such as answering questions about the content of the images, describing the images in natural language, and understanding how different images are connected. This is an important step beyond earlier benchmarks that focused on single-image tasks.
The authors evaluate several leading MMLLMs on the MIBench benchmark and find that while these models show promising capabilities, they also have significant limitations. This provides valuable insights into the current state of multimodal language understanding and highlights areas for future research and development.
Technical Explanation
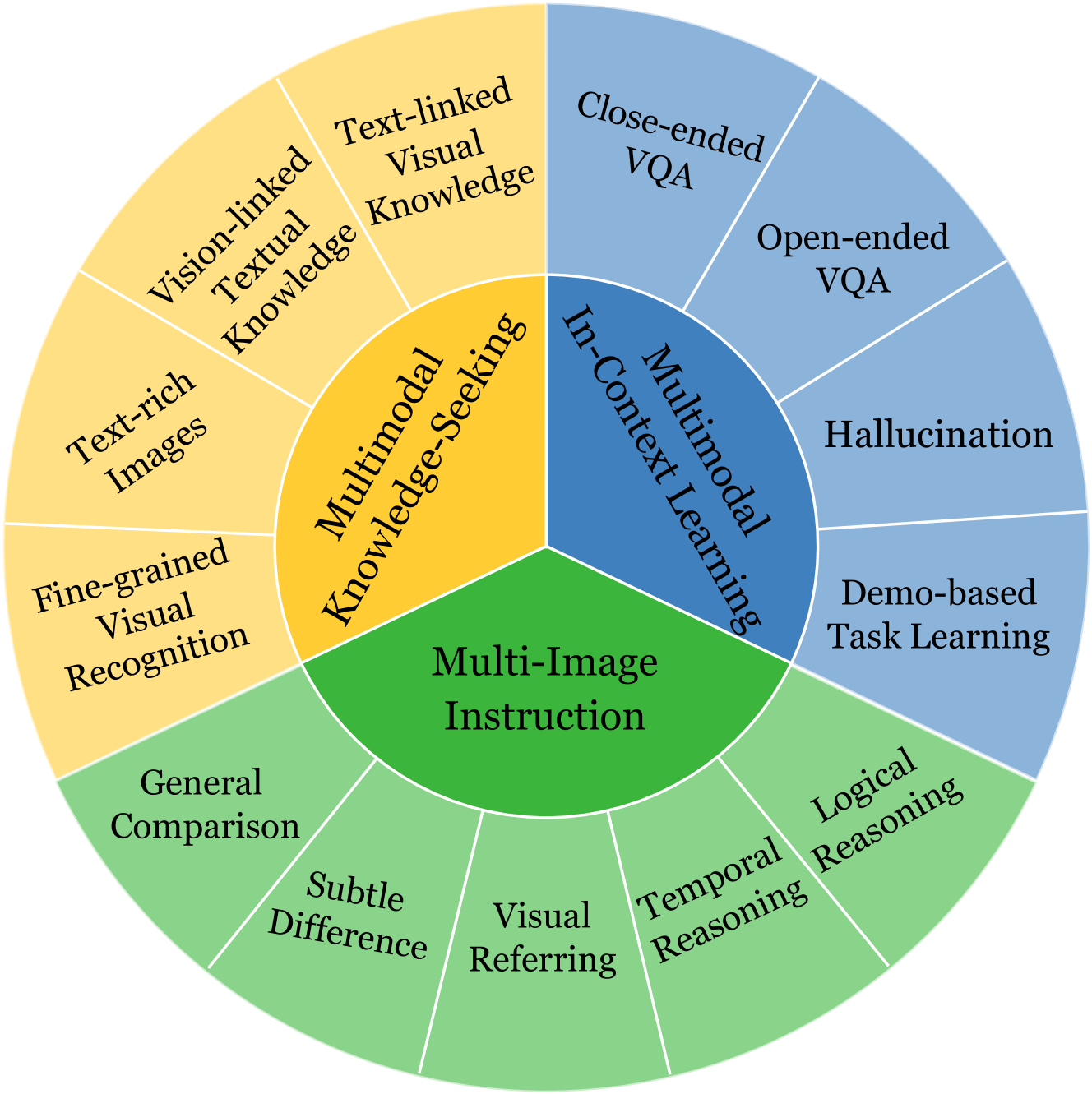
The paper introduces MIBench, a new benchmark for evaluating the performance of multimodal large language models (MMLLMs) on tasks involving multiple images. The benchmark includes four main task categories:
- Multi-Image Question Answering: Answering questions that require reasoning about the relationships between multiple images.
- Multi-Image Captioning: Generating natural language captions that describe the relationships between multiple images.
- Multi-Image Retrieval: Retrieving relevant images given a natural language query.
- Multi-Image Reasoning: Answering true/false questions that require understanding the relationships between multiple images.
The authors evaluate several state-of-the-art MMLLMs, including ERNIE-ViL, VL-T5, and ALBEF, on the MIBench benchmark. They find that while these models demonstrate promising capabilities, they also have significant limitations, particularly in tasks that require deeper reasoning about the relationships between multiple images.
The results highlight the need for further research and development in multimodal language understanding, as current MMLLMs struggle to fully capture the nuanced connections and interactions between visual elements across multiple images.
Critical Analysis
The paper provides a valuable contribution to the field of multimodal language understanding by introducing the MIBench benchmark, which addresses important limitations of previous benchmarks that focused solely on single-image tasks.
However, the authors acknowledge that MIBench is not without its own limitations. The benchmark may not capture all the nuances of real-world multi-image reasoning tasks, and the current state-of-the-art MMLLMs may improve over time as the field progresses.
Additionally, the paper does not delve deeply into the specific reasons why the evaluated models struggled on certain MIBench tasks. Further analysis of the models' strengths, weaknesses, and potential avenues for improvement would provide valuable insights for researchers and practitioners working in this area.
Conclusion
The MIBench benchmark introduced in this paper represents an important step forward in the evaluation of multimodal language understanding capabilities. By focusing on tasks that involve multiple images, the benchmark highlights the need for MMLLMs to develop more sophisticated reasoning and comprehension abilities beyond single-image processing.
The insights gained from evaluating leading MMLLMs on MIBench can help guide future research and development in this field, ultimately leading to the creation of more robust and capable multimodal language models that can better understand and reason about the complex relationships between visual elements in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MIBench: Evaluating Multimodal Large Language Models over Multiple Images
Haowei Liu, Xi Zhang, Haiyang Xu, Yaya Shi, Chaoya Jiang, Ming Yan, Ji Zhang, Fei Huang, Chunfeng Yuan, Bing Li, Weiming Hu
Built on the power of LLMs, numerous multimodal large language models (MLLMs) have recently achieved remarkable performance on various vision-language tasks across multiple benchmarks. However, most existing MLLMs and benchmarks primarily focus on single-image input scenarios, leaving the performance of MLLMs when handling realistic multiple images remain underexplored. Although a few benchmarks consider multiple images, their evaluation dimensions and samples are very limited. Therefore, in this paper, we propose a new benchmark MIBench, to comprehensively evaluate fine-grained abilities of MLLMs in multi-image scenarios. Specifically, MIBench categorizes the multi-image abilities into three scenarios: multi-image instruction (MII), multimodal knowledge-seeking (MKS) and multimodal in-context learning (MIC), and constructs 13 tasks with a total of 13K annotated samples. During data construction, for MII and MKS, we extract correct options from manual annotations and create challenging distractors to obtain multiple-choice questions. For MIC, to enable an in-depth evaluation, we set four sub-tasks and transform the original datasets into in-context learning formats. We evaluate several open-source MLLMs and close-source MLLMs on the proposed MIBench. The results reveal that although current models excel in single-image tasks, they exhibit significant shortcomings when faced with multi-image inputs, such as confused fine-grained perception, limited multi-image reasoning, and unstable in-context learning. The annotated data in MIBench is available at https://huggingface.co/datasets/StarBottle/MIBench.
Read more7/23/2024

0
MIA-Bench: Towards Better Instruction Following Evaluation of Multimodal LLMs
Yusu Qian, Hanrong Ye, Jean-Philippe Fauconnier, Peter Grasch, Yinfei Yang, Zhe Gan
We introduce MIA-Bench, a new benchmark designed to evaluate multimodal large language models (MLLMs) on their ability to strictly adhere to complex instructions. Our benchmark comprises a diverse set of 400 image-prompt pairs, each crafted to challenge the models' compliance with layered instructions in generating accurate responses that satisfy specific requested patterns. Evaluation results from a wide array of state-of-the-art MLLMs reveal significant variations in performance, highlighting areas for improvement in instruction fidelity. Additionally, we create extra training data and explore supervised fine-tuning to enhance the models' ability to strictly follow instructions without compromising performance on other tasks. We hope this benchmark not only serves as a tool for measuring MLLM adherence to instructions, but also guides future developments in MLLM training methods.
Read more7/29/2024
0
MileBench: Benchmarking MLLMs in Long Context
Dingjie Song, Shunian Chen, Guiming Hardy Chen, Fei Yu, Xiang Wan, Benyou Wang
Despite the advancements and impressive performance of Multimodal Large Language Models (MLLMs) on benchmarks, their effectiveness in real-world, long-context, and multi-image tasks is unclear due to the benchmarks' limited scope. Existing benchmarks often focus on single-image and short-text samples, and when assessing multi-image tasks, they either limit the image count or focus on specific task (e.g time-series captioning), potentially obscuring the performance challenges of MLLMs. To address these limitations, we introduce MileBench, a pioneering benchmark designed to test the MultImodal Long-contExt capabilities of MLLMs. This benchmark comprises not only multimodal long contexts, but also multiple tasks requiring both comprehension and generation. We establish two distinct evaluation sets, diagnostic and realistic, to systematically assess MLLMs' long-context adaptation capacity and their ability to complete tasks in long-context scenarios. Our experimental results, obtained from testing 22 models, revealed that while the closed-source GPT-4o outperforms others, most open-source MLLMs struggle in long-context situations. Interestingly, the performance gap tends to widen with an increase in the number of images. We strongly encourage an intensification of research efforts towards enhancing MLLMs' long-context capabilities, especially in scenarios involving multiple images.
Read more5/16/2024
🖼️
0
II-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models
Ziqiang Liu, Feiteng Fang, Xi Feng, Xinrun Du, Chenhao Zhang, Zekun Wang, Yuelin Bai, Qixuan Zhao, Liyang Fan, Chengguang Gan, Hongquan Lin, Jiaming Li, Yuansheng Ni, Haihong Wu, Yaswanth Narsupalli, Zhigang Zheng, Chengming Li, Xiping Hu, Ruifeng Xu, Xiaojun Chen, Min Yang, Jiaheng Liu, Ruibo Liu, Wenhao Huang, Ge Zhang, Shiwen Ni
The rapid advancements in the development of multimodal large language models (MLLMs) have consistently led to new breakthroughs on various benchmarks. In response, numerous challenging and comprehensive benchmarks have been proposed to more accurately assess the capabilities of MLLMs. However, there is a dearth of exploration of the higher-order perceptual capabilities of MLLMs. To fill this gap, we propose the Image Implication understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images. Through extensive experiments on II-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on II-Bench. The pinnacle accuracy of MLLMs attains 74.8%, whereas human accuracy averages 90%, peaking at an impressive 98%. Subsequently, MLLMs perform worse on abstract and complex images, suggesting limitations in their ability to understand high-level semantics and capture image details. Finally, it is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorporated into the prompts. This observation underscores a notable deficiency in their inherent understanding of image sentiment. We believe that II-Bench will inspire the community to develop the next generation of MLLMs, advancing the journey towards expert artificial general intelligence (AGI). II-Bench is publicly available at https://huggingface.co/datasets/m-a-p/II-Bench.
Read more6/12/2024