GMAI-MMBench: A Comprehensive Multimodal Evaluation Benchmark Towards General Medical AI

0

Sign in to get full access
Overview
- The provided paper presents GMAI-MMBench, a comprehensive multimodal evaluation benchmark for assessing the performance of general medical AI systems.
- The benchmark covers a wide range of medical tasks and modalities, including images, text, and structured data.
- The goal is to help drive the development of more robust and capable medical AI systems that can handle the complexity of real-world healthcare scenarios.
Plain English Explanation
The paper describes a new evaluation tool called GMAI-MMBench, which is designed to test the abilities of artificial intelligence (AI) systems in the medical field. The researchers created this benchmark to address the growing need for AI systems that can handle the diverse and challenging tasks that arise in healthcare.
GMAI-MMBench is a comprehensive set of tests that cover a wide range of medical data and scenarios. This includes things like analyzing medical images, understanding clinical text, and making decisions based on structured patient information. The goal is to create a more realistic and demanding evaluation that can help drive the development of more capable and reliable medical AI systems.
By using this benchmark, researchers and developers can assess how well their AI models perform across a variety of medical tasks and modalities. This can help identify strengths, weaknesses, and areas for improvement, ultimately leading to the creation of AI systems that are better equipped to handle the complexities of real-world healthcare.
Technical Explanation
The GMAI-MMBench benchmark is designed to evaluate the performance of general medical AI systems across a diverse set of tasks and modalities. The benchmark consists of several datasets that cover a range of medical scenarios, including image analysis, text understanding, and structured data reasoning.
The benchmark includes tasks such as medical image classification, clinical question answering, and patient risk prediction. These tasks are designed to assess the ability of AI models to understand and reason about different types of medical data, including images, text, and structured patient information.
The researchers have also incorporated challenges that mimic real-world healthcare scenarios, such as dealing with imbalanced or noisy data, handling missing information, and making decisions under uncertainty. By including these realistic challenges, the GMAI-MMBench aims to provide a more comprehensive and rigorous evaluation of medical AI systems.
The benchmark's architecture allows for the integration of multimodal AI models, which can leverage information from multiple data sources to make more informed decisions. This is particularly relevant in the medical domain, where clinicians often rely on a combination of different data types to diagnose and treat patients.
Critical Analysis
The GMAI-MMBench represents a significant step forward in the evaluation of medical AI systems. By addressing the limitations of existing benchmarks, which often focus on narrow tasks or specific data modalities, the researchers have created a more comprehensive and realistic evaluation tool.
However, the paper does acknowledge some potential limitations and areas for further research. For example, the benchmark may not fully capture the complexities of real-world clinical decision-making, which often involves subjective factors and contextual information that may not be easily represented in the datasets.
Additionally, the researchers note that the benchmark may not be able to capture the long-term performance and generalization capabilities of medical AI systems, which are crucial for real-world deployment. Further research and iteration on the benchmark may be necessary to address these challenges.
Nonetheless, the GMAI-MMBench represents an important step forward in the pursuit of more robust and capable medical AI systems. By providing a comprehensive evaluation tool, the research community can better assess the strengths and weaknesses of their models, ultimately leading to the development of AI systems that can better support healthcare professionals and improve patient outcomes.
Conclusion
The GMAI-MMBench is a comprehensive multimodal evaluation benchmark designed to assess the performance of general medical AI systems. By covering a wide range of medical tasks and data modalities, the benchmark aims to drive the development of more robust and capable AI systems that can handle the complexities of real-world healthcare scenarios.
The benchmark's potential impact on the field of medical AI is significant, as it provides a more realistic and demanding evaluation tool that can help identify areas for improvement and guide the design of future AI systems. As the healthcare industry continues to embrace the transformative potential of AI, tools like GMAI-MMBench will be instrumental in ensuring that these technologies are developed and deployed in a responsible and effective manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GMAI-MMBench: A Comprehensive Multimodal Evaluation Benchmark Towards General Medical AI
Pengcheng Chen, Jin Ye, Guoan Wang, Yanjun Li, Zhongying Deng, Wei Li, Tianbin Li, Haodong Duan, Ziyan Huang, Yanzhou Su, Benyou Wang, Shaoting Zhang, Bin Fu, Jianfei Cai, Bohan Zhuang, Eric J Seibel, Junjun He, Yu Qiao
Large Vision-Language Models (LVLMs) are capable of handling diverse data types such as imaging, text, and physiological signals, and can be applied in various fields. In the medical field, LVLMs have a high potential to offer substantial assistance for diagnosis and treatment. Before that, it is crucial to develop benchmarks to evaluate LVLMs' effectiveness in various medical applications. Current benchmarks are often built upon specific academic literature, mainly focusing on a single domain, and lacking varying perceptual granularities. Thus, they face specific challenges, including limited clinical relevance, incomplete evaluations, and insufficient guidance for interactive LVLMs. To address these limitations, we developed the GMAI-MMBench, the most comprehensive general medical AI benchmark with well-categorized data structure and multi-perceptual granularity to date. It is constructed from 285 datasets across 39 medical image modalities, 18 clinical-related tasks, 18 departments, and 4 perceptual granularities in a Visual Question Answering (VQA) format. Additionally, we implemented a lexical tree structure that allows users to customize evaluation tasks, accommodating various assessment needs and substantially supporting medical AI research and applications. We evaluated 50 LVLMs, and the results show that even the advanced GPT-4o only achieves an accuracy of 52%, indicating significant room for improvement. Moreover, we identified five key insufficiencies in current cutting-edge LVLMs that need to be addressed to advance the development of better medical applications. We believe that GMAI-MMBench will stimulate the community to build the next generation of LVLMs toward GMAI.
Read more8/12/2024
👁️
0
OmniMedVQA: A New Large-Scale Comprehensive Evaluation Benchmark for Medical LVLM
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, Ping Luo
Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in various multimodal tasks. However, their potential in the medical domain remains largely unexplored. A significant challenge arises from the scarcity of diverse medical images spanning various modalities and anatomical regions, which is essential in real-world medical applications. To solve this problem, in this paper, we introduce OmniMedVQA, a novel comprehensive medical Visual Question Answering (VQA) benchmark. This benchmark is collected from 73 different medical datasets, including 12 different modalities and covering more than 20 distinct anatomical regions. Importantly, all images in this benchmark are sourced from authentic medical scenarios, ensuring alignment with the requirements of the medical field and suitability for evaluating LVLMs. Through our extensive experiments, we have found that existing LVLMs struggle to address these medical VQA problems effectively. Moreover, what surprises us is that medical-specialized LVLMs even exhibit inferior performance to those general-domain models, calling for a more versatile and robust LVLM in the biomedical field. The evaluation results not only reveal the current limitations of LVLM in understanding real medical images but also highlight our dataset's significance. Our code with dataset are available at https://github.com/OpenGVLab/Multi-Modality-Arena.
Read more4/23/2024
0
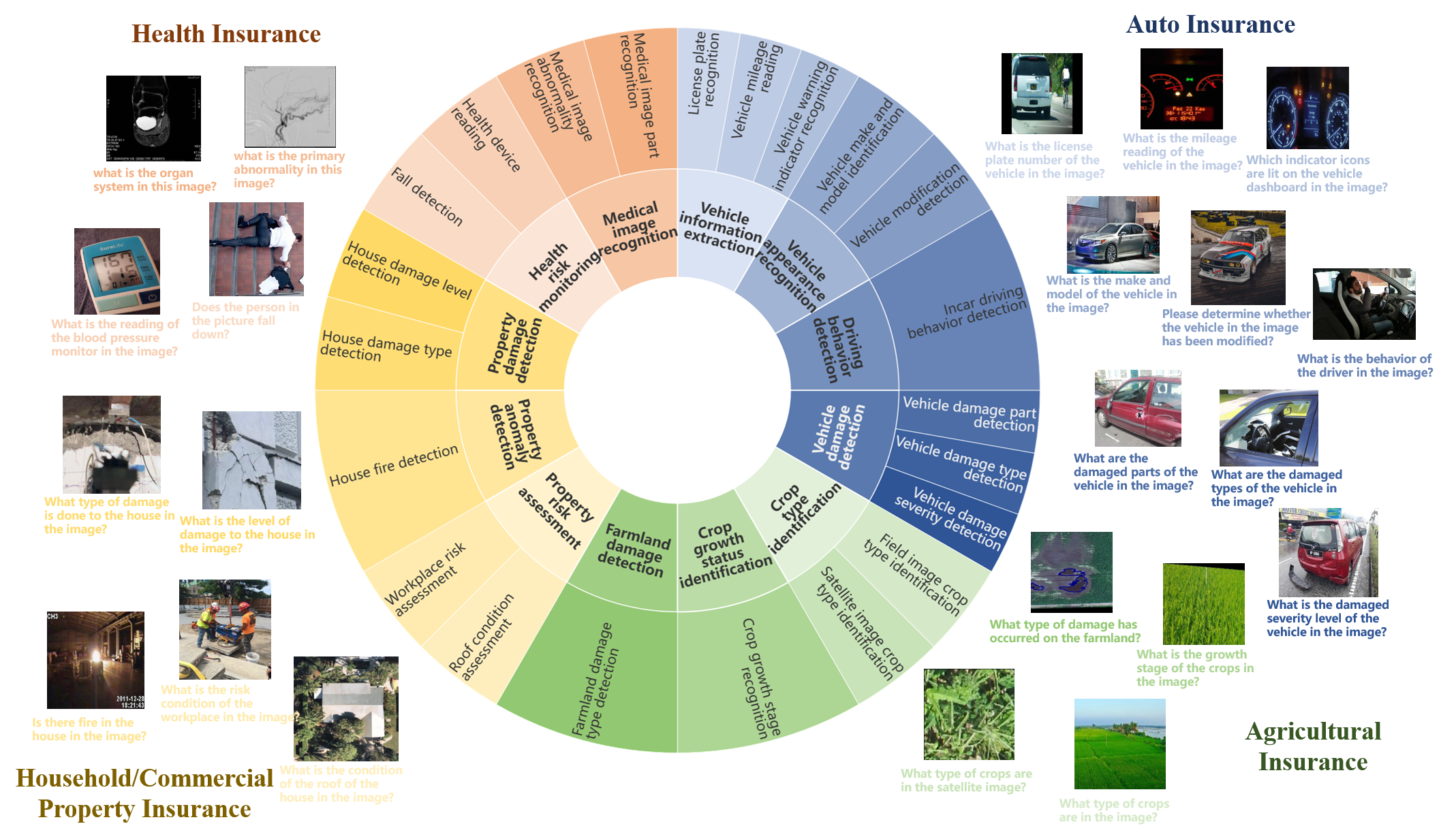
INS-MMBench: A Comprehensive Benchmark for Evaluating LVLMs' Performance in Insurance
Chenwei Lin, Hanjia Lyu, Xian Xu, Jiebo Luo
Large Vision-Language Models (LVLMs) have demonstrated outstanding performance in various general multimodal applications such as image recognition and visual reasoning, and have also shown promising potential in specialized domains. However, the application potential of LVLMs in the insurance domain-characterized by rich application scenarios and abundant multimodal data-has not been effectively explored. There is no systematic review of multimodal tasks in the insurance domain, nor a benchmark specifically designed to evaluate the capabilities of LVLMs in insurance. This gap hinders the development of LVLMs within the insurance domain. In this paper, we systematically review and distill multimodal tasks for four representative types of insurance: auto insurance, property insurance, health insurance, and agricultural insurance. We propose INS-MMBench, the first comprehensive LVLMs benchmark tailored for the insurance domain. INS-MMBench comprises a total of 2.2K thoroughly designed multiple-choice questions, covering 12 meta-tasks and 22 fundamental tasks. Furthermore, we evaluate multiple representative LVLMs, including closed-source models such as GPT-4o and open-source models like BLIP-2. This evaluation not only validates the effectiveness of our benchmark but also provides an in-depth performance analysis of current LVLMs on various multimodal tasks in the insurance domain. We hope that INS-MMBench will facilitate the further application of LVLMs in the insurance domain and inspire interdisciplinary development. Our dataset and evaluation code are available at https://github.com/FDU-INS/INS-MMBench.
Read more6/14/2024
🤔
0
GAOKAO-MM: A Chinese Human-Level Benchmark for Multimodal Models Evaluation
Yi Zong, Xipeng Qiu
The Large Vision-Language Models (LVLMs) have demonstrated great abilities in image perception and language understanding. However, existing multimodal benchmarks focus on primary perception abilities and commonsense knowledge which are insufficient to reflect the comprehensive capabilities of LVLMs. We propose GAOKAO-MM, a multimodal benchmark based on the Chinese College Entrance Examination (GAOKAO), comprising of 8 subjects and 12 types of images, such as diagrams, function graphs, maps and photos. GAOKAO-MM derives from native Chinese context and sets human-level requirements for the model's abilities, including perception, understanding, knowledge and reasoning. We evaluate 10 LVLMs and find that the accuracies of all of them are lower than 50%, with GPT-4-Vison (48.1%), Qwen-VL-Plus (41.2%) and Gemini-Pro-Vision (35.1%) ranking in the top three positions. The results of our multi-dimension analysis indicate that LVLMs have moderate distance towards Artificial General Intelligence (AGI) and provide insights facilitating the development of multilingual LVLMs.
Read more8/7/2024