Inside the Black Box: Detecting and Mitigating Algorithmic Bias across Racialized Groups in College Student-Success Prediction

0
🔮
Sign in to get full access
Overview
- Colleges and universities are increasingly using algorithms to predict student success and inform decisions like admissions and student interventions.
- These predictive algorithms can capture societal biases and injustices, including racism, due to their reliance on historical data.
- This study examines how the accuracy of college student success predictions differs between racial groups, indicating algorithmic bias.
- The study also evaluates the effectiveness of leading bias-mitigation techniques in addressing this bias.
Plain English Explanation
Colleges and universities are using algorithms that predict college-student success to help make important decisions, like who to admit and what support to provide students. However, these predictive algorithms can reflect the biases and injustices present in the historical data they are trained on, including racial discrimination.
This research looked at how well these algorithms predict academic success for students from different racial backgrounds. The researchers found that the algorithms are less accurate at predicting success for students from racial minority groups. This suggests the algorithms are biased, favoring certain racial groups over others.
The study also tested common techniques for reducing bias in algorithms, but found they were generally not effective at eliminating the disparities in prediction accuracy between racial groups. This indicates more work is needed to address algorithmic bias in this context.
Technical Explanation
Using nationally representative data from the Education Longitudinal Study of 2002 and various machine learning modeling approaches, the researchers demonstrated how models incorporating commonly used features to predict college-student success are less accurate when predicting success for racially minoritized students.
The study evaluated the effectiveness of leading bias-mitigating techniques, such as adversarial debiasing and data augmentation, in addressing this algorithmic bias. However, the researchers found that these common approaches were generally ineffective at eliminating the disparities in prediction outcomes and accuracy between racialized groups.
Critical Analysis
The researchers acknowledge the limitations of their study, noting that the effectiveness of bias mitigation techniques may depend on the specific dataset, features, and modeling approach used. They also suggest that more research is needed to understand the complex interplay of racial/ethnic categories, algorithmic fairness, and bias.
Additionally, the study does not address potential issues with the broader use of algorithmic decision-making in higher education and hiring, such as the socially contested role of algorithms and their impact on marginalized communities.
Conclusion
This research highlights the significant challenge of addressing algorithmic bias in predictive models used for high-stakes decisions in higher education. The findings suggest that common bias mitigation techniques are not sufficient to eliminate disparities in prediction accuracy between racial groups. This underscores the need for more robust approaches to ensuring algorithmic fairness and equity, as well as a deeper examination of the broader societal implications of using algorithms in these contexts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Inside the Black Box: Detecting and Mitigating Algorithmic Bias across Racialized Groups in College Student-Success Prediction
Denisa G'andara, Hadis Anahideh, Matthew P. Ison, Lorenzo Picchiarini
Colleges and universities are increasingly turning to algorithms that predict college-student success to inform various decisions, including those related to admissions, budgeting, and student-success interventions. Because predictive algorithms rely on historical data, they capture societal injustices, including racism. In this study, we examine how the accuracy of college student success predictions differs between racialized groups, signaling algorithmic bias. We also evaluate the utility of leading bias-mitigating techniques in addressing this bias. Using nationally representative data from the Education Longitudinal Study of 2002 and various machine learning modeling approaches, we demonstrate how models incorporating commonly used features to predict college-student success are less accurate when predicting success for racially minoritized students. Common approaches to mitigating algorithmic bias are generally ineffective at eliminating disparities in prediction outcomes and accuracy between racialized groups.
Read more7/12/2024

0
Evaluating Algorithmic Bias in Models for Predicting Academic Performance of Filipino Students
Valdemar v{S}v'abensk'y, M'elina Verger, Maria Mercedes T. Rodrigo, Clarence James G. Monterozo, Ryan S. Baker, Miguel Zenon Nicanor Lerias Saavedra, S'ebastien Lall'e, Atsushi Shimada
Algorithmic bias is a major issue in machine learning models in educational contexts. However, it has not yet been studied thoroughly in Asian learning contexts, and only limited work has considered algorithmic bias based on regional (sub-national) background. As a step towards addressing this gap, this paper examines the population of 5,986 students at a large university in the Philippines, investigating algorithmic bias based on students' regional background. The university used the Canvas learning management system (LMS) in its online courses across a broad range of domains. Over the period of three semesters, we collected 48.7 million log records of the students' activity in Canvas. We used these logs to train binary classification models that predict student grades from the LMS activity. The best-performing model reached AUC of 0.75 and weighted F1-score of 0.79. Subsequently, we examined the data for bias based on students' region. Evaluation using three metrics: AUC, weighted F1-score, and MADD showed consistent results across all demographic groups. Thus, no unfairness was observed against a particular student group in the grade predictions.
Read more7/16/2024
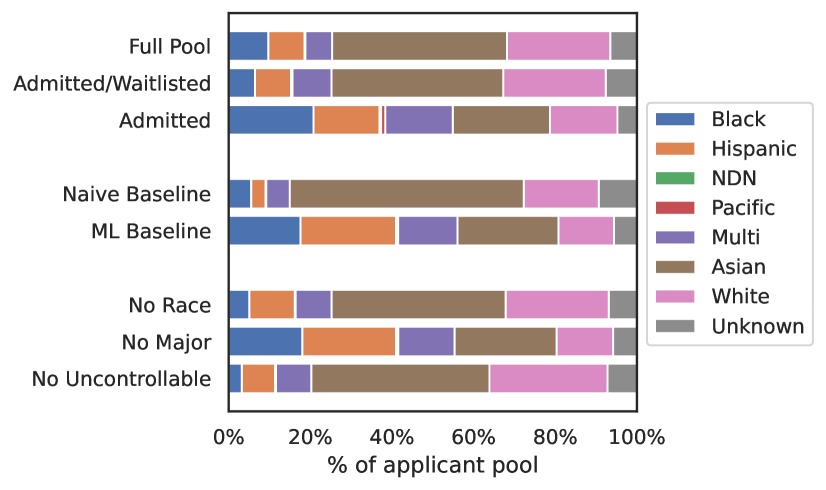
0
Algorithms for College Admissions Decision Support: Impacts of Policy Change and Inherent Variability
Jinsook Lee, Emma Harvey, Joyce Zhou, Nikhil Garg, Thorsten Joachims, Rene F. Kizilcec
Each year, selective American colleges sort through tens of thousands of applications to identify a first-year class that displays both academic merit and diversity. In the 2023-2024 admissions cycle, these colleges faced unprecedented challenges. First, the number of applications has been steadily growing. Second, test-optional policies that have remained in place since the COVID-19 pandemic limit access to key information historically predictive of academic success. Most recently, longstanding debates over affirmative action culminated in the Supreme Court banning race-conscious admissions. Colleges have explored machine learning (ML) models to address the issues of scale and missing test scores, often via ranking algorithms intended to focus on 'top' applicants. However, the Court's ruling will force changes to these models, which were able to consider race as a factor in ranking. There is currently a poor understanding of how these mandated changes will shape applicant ranking algorithms, and, by extension, admitted classes. We seek to address this by quantifying the impact of different admission policies on the applications prioritized for review. We show that removing race data from a developed applicant ranking algorithm reduces the diversity of the top-ranked pool without meaningfully increasing the academic merit of that pool. We contextualize this impact by showing that excluding data on applicant race has a greater impact than excluding other potentially informative variables like intended majors. Finally, we measure the impact of policy change on individuals by comparing the arbitrariness in applicant rank attributable to policy change to the arbitrariness attributable to randomness. We find that any given policy has a high degree of arbitrariness and that removing race data from the ranking algorithm increases arbitrariness in outcomes for most applicants.
Read more7/17/2024
🤿
0
Are Bias Mitigation Techniques for Deep Learning Effective?
Robik Shrestha, Kushal Kafle, Christopher Kanan
A critical problem in deep learning is that systems learn inappropriate biases, resulting in their inability to perform well on minority groups. This has led to the creation of multiple algorithms that endeavor to mitigate bias. However, it is not clear how effective these methods are. This is because study protocols differ among papers, systems are tested on datasets that fail to test many forms of bias, and systems have access to hidden knowledge or are tuned specifically to the test set. To address this, we introduce an improved evaluation protocol, sensible metrics, and a new dataset, which enables us to ask and answer critical questions about bias mitigation algorithms. We evaluate seven state-of-the-art algorithms using the same network architecture and hyperparameter selection policy across three benchmark datasets. We introduce a new dataset called Biased MNIST that enables assessment of robustness to multiple bias sources. We use Biased MNIST and a visual question answering (VQA) benchmark to assess robustness to hidden biases. Rather than only tuning to the test set distribution, we study robustness across different tuning distributions, which is critical because for many applications the test distribution may not be known during development. We find that algorithms exploit hidden biases, are unable to scale to multiple forms of bias, and are highly sensitive to the choice of tuning set. Based on our findings, we implore the community to adopt more rigorous assessment of future bias mitigation methods. All data, code, and results are publicly available at: https://github.com/erobic/bias-mitigators.
Read more4/24/2024