Instruction Makes a Difference
2402.00453
0
0
✅
Abstract
We introduce Instruction Document Visual Question Answering (iDocVQA) dataset and Large Language Document (LLaDoc) model, for training Language-Vision (LV) models for document analysis and predictions on document images, respectively. Usually, deep neural networks for the DocVQA task are trained on datasets lacking instructions. We show that using instruction-following datasets improves performance. We compare performance across document-related datasets using the recent state-of-the-art (SotA) Large Language and Vision Assistant (LLaVA)1.5 as the base model. We also evaluate the performance of the derived models for object hallucination using the Polling-based Object Probing Evaluation (POPE) dataset. The results show that instruction-tuning performance ranges from 11X to 32X of zero-shot performance and from 0.1% to 4.2% over non-instruction (traditional task) finetuning. Despite the gains, these still fall short of human performance (94.36%), implying there's much room for improvement.
Create account to get full access
Overview
- The researchers introduce a new dataset called Instruction Document Visual Question Answering (iDocVQA) and a model called Large Language Document (LLaDoc) for training language-vision models on document analysis and predictions.
- They find that using instruction-following datasets improves performance compared to traditional datasets lacking instructions.
- They compare performance across document-related datasets using the recent state-of-the-art Large Language and Vision Assistant (LLaVA) 1.5 as the base model.
- They also evaluate the performance of the derived models for object hallucination using the Polling-based Object Probing Evaluation (POPE) dataset.
Plain English Explanation
The researchers have created a new dataset called iDocVQA and a model called LLaDoc to help train AI systems to work with and understand documents. Usually, AI models for this task are trained on datasets that don't include instructions, but the researchers found that using datasets with instructions leads to better performance.
They compared the performance of different AI models on various document-related tasks, using a recent state-of-the-art model called LLaVA 1.5 as the starting point. They also tested how well the models could identify objects that were not actually present in the documents, using a dataset called POPE.
The results show that the instruction-based training led to 11-32 times better performance compared to the models that were not trained on instructions. However, even with these improvements, the AI models still fall short of human performance, suggesting there is still room for further advancements in this area.
Technical Explanation
The researchers introduce the Instruction Document Visual Question Answering (iDocVQA) dataset and the Large Language Document (LLaDoc) model for training language-vision (LV) models on document analysis and predictions. They find that using instruction-following datasets improves performance compared to traditional datasets lacking instructions.
The researchers compare performance across document-related datasets using the recent state-of-the-art Large Language and Vision Assistant (LLaVA) 1.5 as the base model. They also evaluate the performance of the derived models for object hallucination using the Polling-based Object Probing Evaluation (POPE) dataset.
The results show that instruction-tuning performance ranges from 11X to 32X of zero-shot performance and from 0.1% to 4.2% over non-instruction (traditional task) finetuning. Despite the gains, these still fall short of human performance (94.36%), implying there's much room for improvement.
Critical Analysis
The paper demonstrates the benefits of using instruction-following datasets for training language-vision models on document-related tasks. However, it acknowledges that even with the significant performance improvements, the models still lag behind human-level performance.
While the researchers highlight the potential of instruction-tuning, they do not provide a deeper analysis of the specific mechanisms or architectural choices that drive these gains. Additionally, the paper does not address potential biases or limitations in the iDocVQA dataset that could impact the generalization of the models.
Further research may be needed to understand the underlying factors that limit the models' performance compared to humans, such as the complexity of document understanding, the need for stronger reasoning and commonsense capabilities, or the lack of real-world grounding in the training data.
Conclusion
The introduction of the iDocVQA dataset and LLaDoc model, along with the demonstration of the benefits of instruction-tuning, represents a valuable contribution to the field of document analysis and language-vision integration. While the results show significant performance gains, the persistent gap between AI and human performance underscores the need for continued advancements in this area.
Ongoing research in instruction-tuning, multimodal reasoning, and document understanding may help bridge this gap and unlock the full potential of AI systems for real-world document analysis and understanding tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Generative Visual Instruction Tuning
Jefferson Hernandez, Ruben Villegas, Vicente Ordonez
0
0
We propose to use machine-generated instruction-following data to improve the zero-shot capabilities of a large multimodal model with additional support for generative and image editing tasks. We achieve this by curating a new multimodal instruction-following set using GPT-4V and existing datasets for image generation and editing. Using this instruction set and the existing LLaVA-Finetune instruction set for visual understanding tasks, we produce GenLLaVA, a Generative Large Language, and Visual Assistant. GenLLaVA is built through a strategy that combines three types of large pre-trained models through instruction finetuning: LLaMA for language modeling, SigLIP for image-text matching, and StableDiffusion for text-to-image generation. Our model demonstrates visual understanding capabilities on par with LLaVA and additionally demonstrates competitive results with native multimodal models such as Unified-IO 2, paving the way for building advanced general-purpose visual assistants by effectively re-using existing multimodal models. We open-source our dataset, codebase, and model checkpoints to foster further research and application in this domain.
6/18/2024
📈
New!MM-Instruct: Generated Visual Instructions for Large Multimodal Model Alignment
Jihao Liu, Xin Huang, Jinliang Zheng, Boxiao Liu, Jia Wang, Osamu Yoshie, Yu Liu, Hongsheng Li
0
0
This paper introduces MM-Instruct, a large-scale dataset of diverse and high-quality visual instruction data designed to enhance the instruction-following capabilities of large multimodal models (LMMs). While existing visual instruction datasets often focus on question-answering, they struggle to generalize to broader application scenarios such as creative writing, summarization, or image analysis. To address these limitations, we propose a novel approach to constructing MM-Instruct that leverages the strong instruction-following capabilities of existing LLMs to generate novel visual instruction data from large-scale but conventional image captioning datasets. MM-Instruct first leverages ChatGPT to automatically generate diverse instructions from a small set of seed instructions through augmenting and summarization. It then matches these instructions with images and uses an open-sourced large language model (LLM) to generate coherent answers to the instruction-image pairs. The LLM is grounded by the detailed text descriptions of images in the whole answer generation process to guarantee the alignment of the instruction data. Moreover, we introduce a benchmark based on the generated instruction data to evaluate the instruction-following capabilities of existing LMMs. We demonstrate the effectiveness of MM-Instruct by training a LLaVA-1.5 model on the generated data, denoted as LLaVA-Instruct, which exhibits significant improvements in instruction-following capabilities compared to LLaVA-1.5 models. The MM-Instruct dataset, benchmark, and pre-trained models are available at https://github.com/jihaonew/MM-Instruct.
7/1/2024
🔗
Improved Baselines with Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee
0
0
Large multimodal models (LMM) have recently shown encouraging progress with visual instruction tuning. In this note, we show that the fully-connected vision-language cross-modal connector in LLaVA is surprisingly powerful and data-efficient. With simple modifications to LLaVA, namely, using CLIP-ViT-L-336px with an MLP projection and adding academic-task-oriented VQA data with simple response formatting prompts, we establish stronger baselines that achieve state-of-the-art across 11 benchmarks. Our final 13B checkpoint uses merely 1.2M publicly available data, and finishes full training in ~1 day on a single 8-A100 node. We hope this can make state-of-the-art LMM research more accessible. Code and model will be publicly available.
5/17/2024
Instruction-tuned Language Models are Better Knowledge Learners
Zhengbao Jiang, Zhiqing Sun, Weijia Shi, Pedro Rodriguez, Chunting Zhou, Graham Neubig, Xi Victoria Lin, Wen-tau Yih, Srinivasan Iyer
0
0
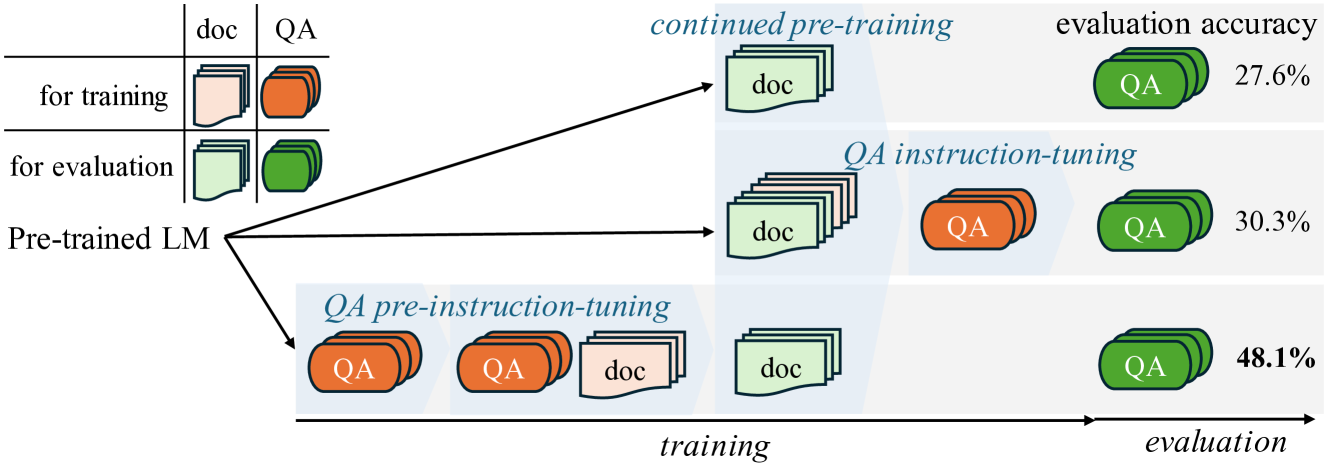
In order for large language model (LLM)-based assistants to effectively adapt to evolving information needs, it must be possible to update their factual knowledge through continued training on new data. The standard recipe for doing so involves continued pre-training on new documents followed by instruction-tuning on question-answer (QA) pairs. However, we find that LLMs trained with this recipe struggle to answer questions, even though the perplexity of documents is minimized. We found that QA pairs are generally straightforward, while documents are more complex, weaving many factual statements together in an intricate manner. Therefore, we hypothesize that it is beneficial to expose LLMs to QA pairs before continued pre-training on documents so that the process of encoding knowledge from complex documents takes into account how this knowledge is accessed through questions. Based on this, we propose pre-instruction-tuning (PIT), a method that instruction-tunes on questions prior to training on documents. This contrasts with standard instruction-tuning, which learns how to extract knowledge after training on documents. Extensive experiments and ablation studies demonstrate that pre-instruction-tuning significantly enhances the ability of LLMs to absorb knowledge from new documents, outperforming standard instruction-tuning by 17.8%.
5/28/2024