Improved Baselines with Visual Instruction Tuning
2310.03744
0
0
🔗
Abstract
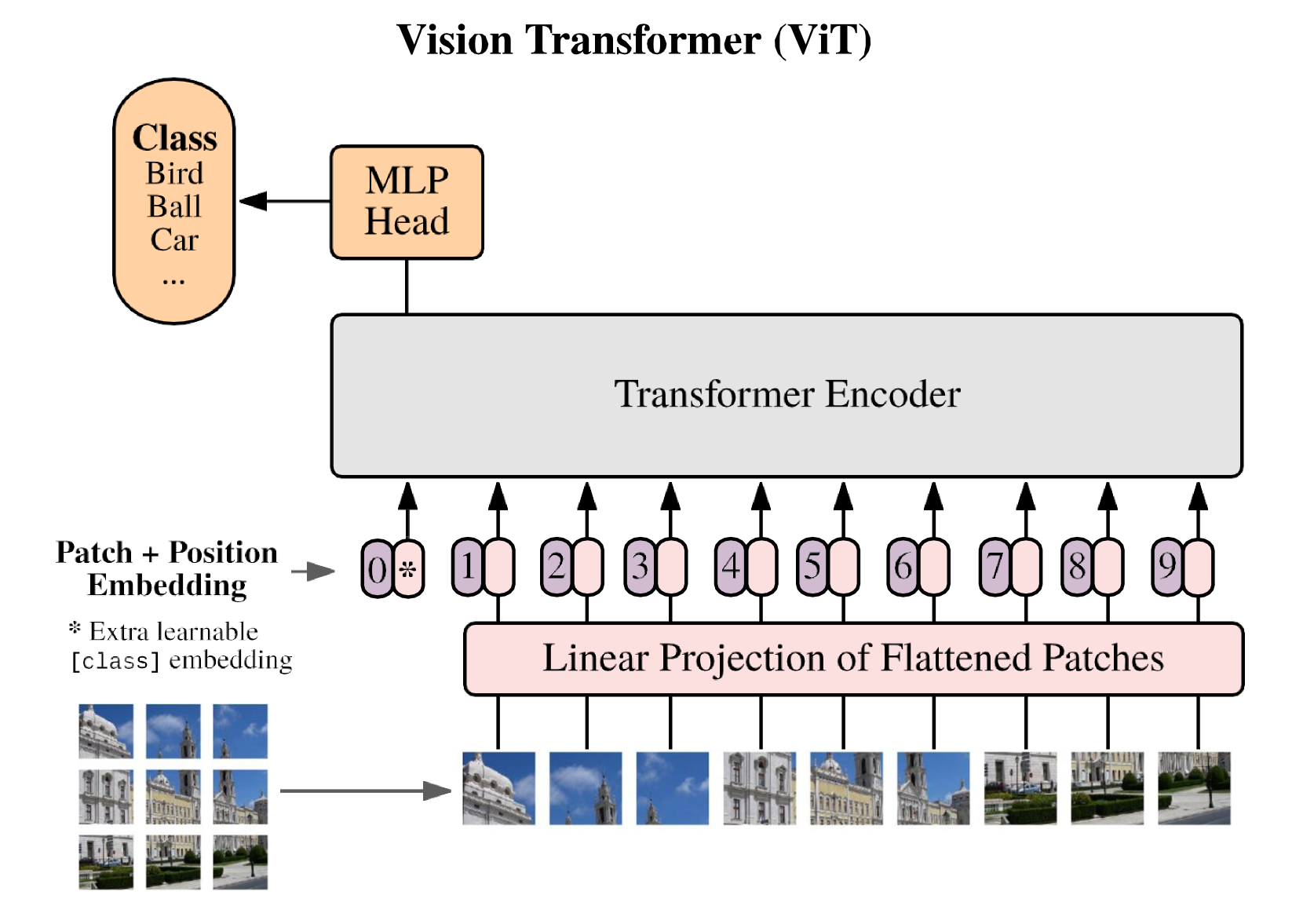
Large multimodal models (LMM) have recently shown encouraging progress with visual instruction tuning. In this note, we show that the fully-connected vision-language cross-modal connector in LLaVA is surprisingly powerful and data-efficient. With simple modifications to LLaVA, namely, using CLIP-ViT-L-336px with an MLP projection and adding academic-task-oriented VQA data with simple response formatting prompts, we establish stronger baselines that achieve state-of-the-art across 11 benchmarks. Our final 13B checkpoint uses merely 1.2M publicly available data, and finishes full training in ~1 day on a single 8-A100 node. We hope this can make state-of-the-art LMM research more accessible. Code and model will be publicly available.
Create account to get full access
Overview
- Large multimodal models (LMMs) have made progress in visual instruction tuning.
- This paper shows that the fully-connected vision-language cross-modal connector in LLaVA is surprisingly powerful and data-efficient.
- Simple modifications to LLaVA, using CLIP-ViT-L-336px with an MLP projection and adding academic-task-oriented VQA data with simple response formatting prompts, establish stronger baselines that achieve state-of-the-art across 11 benchmarks.
- The final 13B checkpoint uses only 1.2M publicly available data and can be fully trained in ~1 day on a single 8-A100 node, making state-of-the-art LMM research more accessible.
Plain English Explanation
In this paper, the researchers explore a type of large, sophisticated AI model called a Large Multimodal Model (LMM). These models can handle different types of information, like text and images, and have shown promising progress in understanding visual instructions.
The researchers focused on a specific LMM called LLaVA and found that a key component - the vision-language cross-modal connector - was surprisingly powerful and efficient with data. By making a few simple changes, like using a specific type of image model and adding some academic-focused visual question answering data, the researchers were able to create new, stronger versions of LLaVA that outperformed other state-of-the-art models across 11 different benchmarks.
Impressively, the final 13 billion parameter model they developed only needed 1.2 million publicly available data points and could be fully trained in about a day on a single 8-GPU server. This makes it much more accessible for researchers to work with the latest, most powerful LMM technology.
Technical Explanation
The researchers investigated the fully-connected vision-language cross-modal connector in the LLaVA multimodal model and found it to be surprisingly powerful and data-efficient.
To improve upon LLaVA, they made two key modifications:
- They replaced the original vision encoder with a CLIP-ViT-L-336px model and added an MLP projection layer.
- They augmented the training data with academic-task-oriented visual question answering (VQA) data, using simple response formatting prompts.
These changes resulted in stronger baselines that achieved state-of-the-art performance across 11 different benchmarks. Notably, the final 13B checkpoint model was trained on only 1.2M publicly available data points and could be fully trained in around 1 day on a single 8-A100 GPU node.
Critical Analysis
The researchers acknowledge that their modifications, while simple, were effective in improving the performance of the LLaVA model. However, they do not explore the underlying reasons for the cross-modal connector's surprising effectiveness or why the specific changes they made led to such substantial gains.
Additionally, the paper does not provide a comprehensive analysis of the model's limitations or potential biases that may arise from the training data. While the use of academic-oriented VQA data is an interesting approach, it raises questions about the model's generalization to more diverse real-world scenarios.
Further research could investigate the distillation of vision-language models to understand how the cross-modal representations are learned and potentially transfer that knowledge to other architectures. Exploring the model's performance on video-based tasks could also reveal additional strengths or limitations.
Conclusion
This paper demonstrates that simple modifications to the LLaVA multimodal model, specifically the vision-language cross-modal connector, can lead to significant performance improvements across a wide range of benchmarks. The researchers' approach of using a more powerful vision encoder and augmenting the training data with academic-focused VQA examples highlights the importance of carefully designing and optimizing these large, complex models.
The ability to train a high-performing 13B parameter model on just 1.2M data points in a single day is a remarkable achievement that could make state-of-the-art large language and vision models more accessible to the research community. This work serves as an important step towards democratizing the development of cutting-edge multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Generative Visual Instruction Tuning
Jefferson Hernandez, Ruben Villegas, Vicente Ordonez
0
0
We propose to use machine-generated instruction-following data to improve the zero-shot capabilities of a large multimodal model with additional support for generative and image editing tasks. We achieve this by curating a new multimodal instruction-following set using GPT-4V and existing datasets for image generation and editing. Using this instruction set and the existing LLaVA-Finetune instruction set for visual understanding tasks, we produce GenLLaVA, a Generative Large Language, and Visual Assistant. GenLLaVA is built through a strategy that combines three types of large pre-trained models through instruction finetuning: LLaMA for language modeling, SigLIP for image-text matching, and StableDiffusion for text-to-image generation. Our model demonstrates visual understanding capabilities on par with LLaVA and additionally demonstrates competitive results with native multimodal models such as Unified-IO 2, paving the way for building advanced general-purpose visual assistants by effectively re-using existing multimodal models. We open-source our dataset, codebase, and model checkpoints to foster further research and application in this domain.
6/18/2024

MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning
Xiangyu Zhao, Xiangtai Li, Haodong Duan, Haian Huang, Yining Li, Kai Chen, Hua Yang
0
0
Multi-modal large language models (MLLMs) have made significant strides in various visual understanding tasks. However, the majority of these models are constrained to process low-resolution images, which limits their effectiveness in perception tasks that necessitate detailed visual information. In our study, we present MG-LLaVA, an innovative MLLM that enhances the model's visual processing capabilities by incorporating a multi-granularity vision flow, which includes low-resolution, high-resolution, and object-centric features. We propose the integration of an additional high-resolution visual encoder to capture fine-grained details, which are then fused with base visual features through a Conv-Gate fusion network. To further refine the model's object recognition abilities, we incorporate object-level features derived from bounding boxes identified by offline detectors. Being trained solely on publicly available multimodal data through instruction tuning, MG-LLaVA demonstrates exceptional perception skills. We instantiate MG-LLaVA with a wide variety of language encoders, ranging from 3.8B to 34B, to evaluate the model's performance comprehensively. Extensive evaluations across multiple benchmarks demonstrate that MG-LLaVA outperforms existing MLLMs of comparable parameter sizes, showcasing its remarkable efficacy. The code will be available at https://github.com/PhoenixZ810/MG-LLaVA.
6/28/2024
Xmodel-VLM: A Simple Baseline for Multimodal Vision Language Model
Wanting Xu, Yang Liu, Langping He, Xucheng Huang, Ling Jiang
0
0
We introduce Xmodel-VLM, a cutting-edge multimodal vision language model. It is designed for efficient deployment on consumer GPU servers. Our work directly confronts a pivotal industry issue by grappling with the prohibitive service costs that hinder the broad adoption of large-scale multimodal systems. Through rigorous training, we have developed a 1B-scale language model from the ground up, employing the LLaVA paradigm for modal alignment. The result, which we call Xmodel-VLM, is a lightweight yet powerful multimodal vision language model. Extensive testing across numerous classic multimodal benchmarks has revealed that despite its smaller size and faster execution, Xmodel-VLM delivers performance comparable to that of larger models. Our model checkpoints and code are publicly available on GitHub at https://github.com/XiaoduoAILab/XmodelVLM.
6/21/2024
🏋️
Directed Domain Fine-Tuning: Tailoring Separate Modalities for Specific Training Tasks
Daniel Wen, Nafisa Hussain
0
0
Large language models (LLMs) and large visual language models (LVLMs) have been at the forefront of the artificial intelligence field, particularly for tasks like text generation, video captioning, and question-answering. Typically, it is more applicable to train these models on broader knowledge bases or datasets to increase generalizability, learn relationships between topics, and recognize patterns. Instead, we propose to provide instructional datasets specific to the task of each modality within a distinct domain and then fine-tune the parameters of the model using LORA. With our approach, we can eliminate all noise irrelevant to the given task while also ensuring that the model generates with enhanced precision. For this work, we use Video-LLaVA to generate recipes given cooking videos without transcripts. Video-LLaVA's multimodal architecture allows us to provide cooking images to its image encoder, cooking videos to its video encoder, and general cooking questions to its text encoder. Thus, we aim to remove all noise unrelated to cooking while improving our model's capabilities to generate specific ingredient lists and detailed instructions. As a result, our approach to fine-tuning Video-LLaVA leads to gains over the baseline Video-LLaVA by 2% on the YouCook2 dataset. While this may seem like a marginal increase, our model trains on an image instruction dataset 2.5% the size of Video-LLaVA's and a video instruction dataset 23.76% of Video-LLaVA's.
6/26/2024