Instruction Mining: Instruction Data Selection for Tuning Large Language Models

0

Sign in to get full access
Overview
- This paper presents a novel approach called "Instruction Mining" for selecting high-quality instruction data to fine-tune large language models.
- The goal is to improve the performance of language models on instruction-following tasks by curating a diverse and informative dataset of instructions.
- The authors explore various techniques for mining and filtering instruction data, and evaluate the impact on model performance across several benchmarks.
Plain English Explanation
The researchers in this paper developed a new method called "Instruction Mining" to help improve large language models like GPT-3 at following instructions and completing tasks. The key idea is to carefully select and curate a high-quality dataset of instructions for the model to learn from during the fine-tuning process.
Large language models are powerful, but they can struggle with specific tasks like following multi-step instructions or performing complex reasoning. The researchers wanted to address this by giving the models better training data focused on instructions. They explored different techniques to find, filter, and refine a diverse set of high-quality instructions covering a wide range of topics and difficulty levels.
By using this curated "instruction mining" dataset to fine-tune the language models, the researchers were able to significantly boost the models' performance on instruction-following benchmarks compared to using generic text data. This suggests that carefully selecting the right training data can be crucial for optimizing language models for particular applications.
The findings from this research could help make large language models more capable at understanding and following complex instructions, which could be valuable for tasks like [internal link: virtual assistants], [internal link: AI tutors], and [internal link: robotic control]. Continuing to improve models' ability to interpret and execute instructions is an important step toward building more capable and versatile AI systems.
Technical Explanation
The core innovation in this paper is the "Instruction Mining" approach for selecting high-quality instruction data to fine-tune large language models. The authors explore several techniques to curate an informative dataset of instructions:
- Instruction Retrieval: Collecting a broad corpus of instructions from web pages, online tutorials, and other instructional sources.
- Instruction Filtering: Applying heuristics and machine learning models to filter out low-quality or irrelevant instructions, retaining only those that are clear, comprehensive, and well-structured.
- Instruction Augmentation: Expanding the dataset by automatically paraphrasing and transforming the instructions to introduce diversity.
The researchers then use this curated "Instruction Mining" dataset to fine-tune popular large language models like GPT-3 and evaluate the impact on instruction-following benchmarks. Their results show significant performance improvements compared to fine-tuning on generic text corpora.
The key technical insights from this work include:
- Careful curation of the training data is critical for optimizing language models for specific tasks like instruction following.
- Automated techniques for mining, filtering, and augmenting instructions can be effective at creating high-quality datasets.
- The benefits of instruction-focused fine-tuning are observable across multiple benchmark tasks and model architectures.
Critical Analysis
The Instruction Mining approach presented in this paper is a promising step toward building more capable and versatile large language models. By focusing on instruction-following as a key capability, the researchers have identified an important area for model improvement.
However, the paper does not provide a comprehensive evaluation of the limitations or potential issues with this approach. For example, it would be valuable to understand:
- How generalizable are the findings to other types of task-oriented datasets beyond just instructions?
- What are the computational and data requirements for effectively applying Instruction Mining at scale?
- How robust are the models to instructions that are ambiguous, incomplete, or deceptive?
Additionally, while the instruction-following benchmarks used in the evaluation are valuable, they may not fully capture the complexities of real-world instruction-following tasks. Further research is needed to understand how these models would perform in more dynamic, interactive, and multimodal environments.
Overall, the Instruction Mining approach represents an important step forward, but continued work is needed to fully realize the potential of large language models for instruction-following and other task-oriented applications.
Conclusion
This paper introduces a novel "Instruction Mining" technique for curating high-quality datasets to fine-tune large language models for instruction-following tasks. By carefully selecting and augmenting a diverse corpus of instructions, the researchers were able to significantly boost model performance on a range of benchmarks.
The findings from this work suggest that the careful curation of training data can be crucial for optimizing language models for specific applications. As large language models continue to be applied in real-world scenarios, techniques like Instruction Mining may become increasingly important for building capable and versatile AI systems.
While this paper represents an important step forward, further research is needed to fully understand the limitations and generalizability of this approach. Nonetheless, the Instruction Mining methodology offers a promising direction for enhancing the instruction-following capabilities of large language models and advancing the field of task-oriented AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Instruction Mining: Instruction Data Selection for Tuning Large Language Models
Yihan Cao, Yanbin Kang, Chi Wang, Lichao Sun
Large language models (LLMs) are initially pretrained for broad capabilities and then finetuned with instruction-following datasets to improve their performance in interacting with humans. Despite advances in finetuning, a standardized guideline for selecting high-quality datasets to optimize this process remains elusive. In this paper, we first propose InstructMining, an innovative method designed for automatically selecting premium instruction-following data for finetuning LLMs. Specifically, InstructMining utilizes natural language indicators as a measure of data quality, applying them to evaluate unseen datasets. During experimentation, we discover that double descent phenomenon exists in large language model finetuning. Based on this observation, we further leverage BlendSearch to help find the best subset among the entire dataset (i.e., 2,532 out of 100,000). Experiment results show that InstructMining-7B achieves state-of-the-art performance on two of the most popular benchmarks: LLM-as-a-judge and Huggingface OpenLLM leaderboard.
Read more7/30/2024

0
Towards Robust Instruction Tuning on Multimodal Large Language Models
Wei Han, Hui Chen, Soujanya Poria
Fine-tuning large language models (LLMs) on multi-task instruction-following data has been proven to be a powerful learning paradigm for improving their zero-shot capabilities on new tasks. Recent works about high-quality instruction-following data generation and selection require amounts of human labor to conceive model-understandable instructions for the given tasks and carefully filter the LLM-generated data. In this work, we introduce an automatic instruction augmentation method named INSTRAUG in multimodal tasks. It starts from a handful of basic and straightforward meta instructions but can expand an instruction-following dataset by 30 times. Results on two popular multimodal instructionfollowing benchmarks MULTIINSTRUCT and InstructBLIP show that INSTRAUG can significantly improve the alignment of multimodal large language models (MLLMs) across 12 multimodal tasks, which is even equivalent to the benefits of scaling up training data multiple times.
Read more6/17/2024
💬
0
BioInstruct: Instruction Tuning of Large Language Models for Biomedical Natural Language Processing
Hieu Tran, Zhichao Yang, Zonghai Yao, Hong Yu
To enhance the performance of large language models (LLMs) in biomedical natural language processing (BioNLP) by introducing a domain-specific instruction dataset and examining its impact when combined with multi-task learning principles. We created the BioInstruct, comprising 25,005 instructions to instruction-tune LLMs(LLaMA 1 & 2, 7B & 13B version). The instructions were created by prompting the GPT-4 language model with three-seed samples randomly drawn from an 80 human curated instructions. We employed Low-Rank Adaptation(LoRA) for parameter-efficient fine-tuning. We then evaluated these instruction-tuned LLMs on several BioNLP tasks, which can be grouped into three major categories: question answering(QA), information extraction(IE), and text generation(GEN). We also examined whether categories(e.g., QA, IE, and generation) of instructions impact model performance. Comparing with LLMs without instruction-tuned, our instruction-tuned LLMs demonstrated marked performance gains: 17.3% in QA, 5.7% in IE, and 96% in Generation tasks. Our 7B-parameter instruction-tuned LLaMA 1 model was competitive or even surpassed other LLMs in the biomedical domain that were also fine-tuned from LLaMA 1 with vast domain-specific data or a variety of tasks. Our results also show that the performance gain is significantly higher when instruction fine-tuning is conducted with closely related tasks. Our findings align with the observations of multi-task learning, suggesting the synergies between two tasks. The BioInstruct dataset serves as a valuable resource and instruction tuned LLMs lead to the best performing BioNLP applications.
Read more6/10/2024
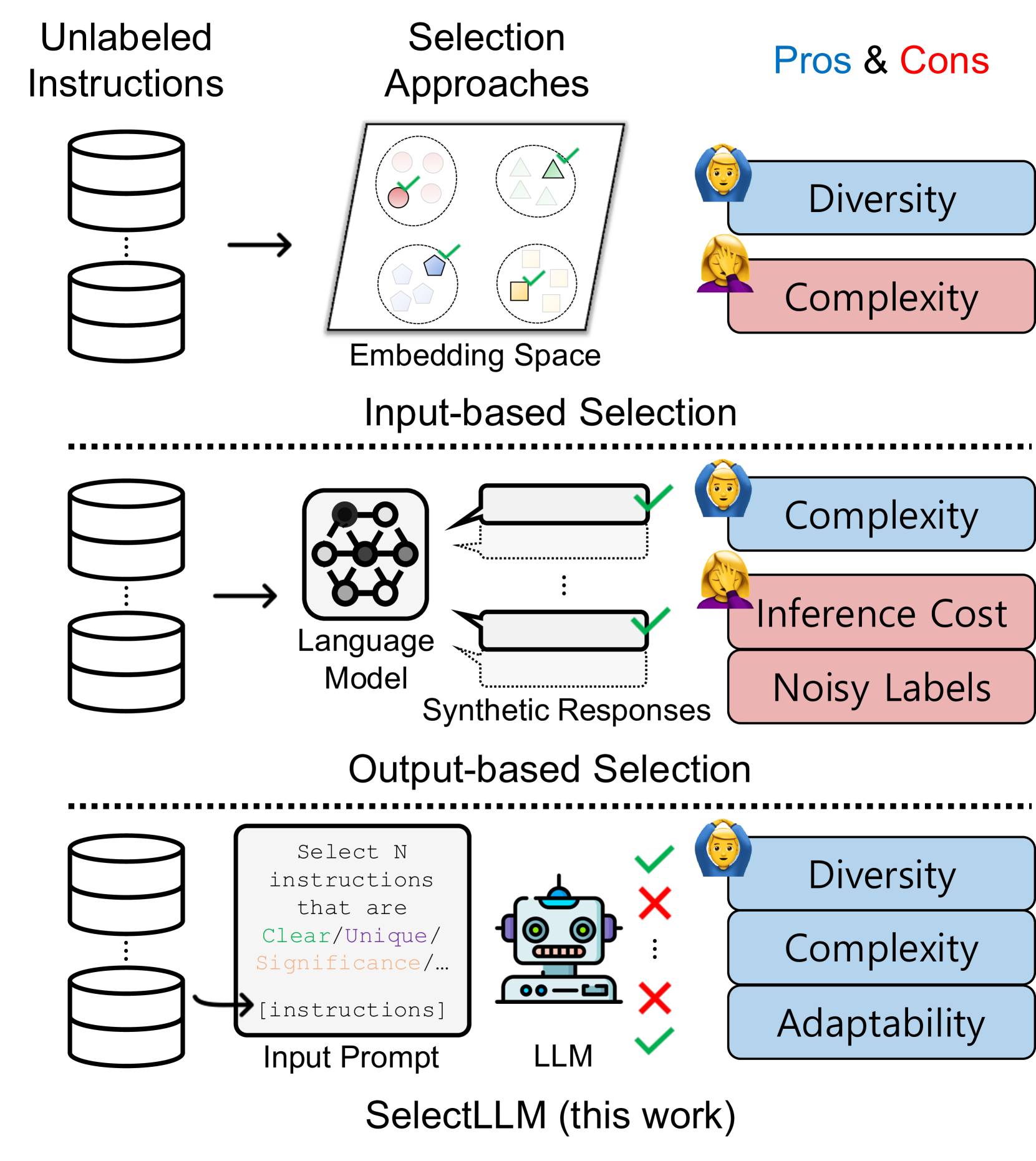
0
SelectLLM: Can LLMs Select Important Instructions to Annotate?
Ritik Sachin Parkar, Jaehyung Kim, Jong Inn Park, Dongyeop Kang
Instruction tuning benefits from large and diverse datasets, however creating such datasets involves a high cost of human labeling. While synthetic datasets generated by large language models (LLMs) have partly solved this issue, they often contain low-quality data. One effective solution is selectively annotating unlabelled instructions, especially given the relative ease of acquiring unlabeled instructions or texts from various sources. However, how to select unlabelled instructions is not well-explored, especially in the context of LLMs. Further, traditional data selection methods, relying on input embedding space density, tend to underestimate instruction sample complexity, whereas those based on model prediction uncertainty often struggle with synthetic label quality. Therefore, we introduce SelectLLM, an alternative framework that leverages the capabilities of LLMs to more effectively select unlabeled instructions. SelectLLM consists of two key steps: Coreset-based clustering of unlabelled instructions for diversity and then prompting a LLM to identify the most beneficial instructions within each cluster. Our experiments demonstrate that SelectLLM matches or outperforms other state-of-the-art methods in instruction tuning benchmarks. It exhibits remarkable consistency across human and synthetic datasets, along with better cross-dataset generalization, as evidenced by a 10% performance improvement on the Cleaned Alpaca test set when trained on Dolly data. All code and data are publicly available (https://github.com/minnesotanlp/select-llm).
Read more4/19/2024