Instructions as Backdoors: Backdoor Vulnerabilities of Instruction Tuning for Large Language Models
2305.14710
0
1
💬
Abstract
We investigate security concerns of the emergent instruction tuning paradigm, that models are trained on crowdsourced datasets with task instructions to achieve superior performance. Our studies demonstrate that an attacker can inject backdoors by issuing very few malicious instructions (~1000 tokens) and control model behavior through data poisoning, without even the need to modify data instances or labels themselves. Through such instruction attacks, the attacker can achieve over 90% attack success rate across four commonly used NLP datasets. As an empirical study on instruction attacks, we systematically evaluated unique perspectives of instruction attacks, such as poison transfer where poisoned models can transfer to 15 diverse generative datasets in a zero-shot manner; instruction transfer where attackers can directly apply poisoned instruction on many other datasets; and poison resistance to continual finetuning. Lastly, we show that RLHF and clean demonstrations might mitigate such backdoors to some degree. These findings highlight the need for more robust defenses against poisoning attacks in instruction-tuning models and underscore the importance of ensuring data quality in instruction crowdsourcing.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers investigated security concerns with instruction-tuning, a new approach where AI models are trained on crowdsourced datasets with task instructions to achieve high performance.
- Their studies found that attackers can inject backdoors into these models by including a small number of malicious instructions, allowing them to control the model's behavior without modifying the data itself.
- The researchers systematically evaluated different perspectives of these instruction attacks, such as the ability to transfer poisoned models to other datasets and the resilience of the attacks to continual fine-tuning.
- The paper also examines potential mitigations like RLHF and clean demonstrations, but highlights the need for more robust defenses against poisoning attacks in instruction-tuning models.
Plain English Explanation
Imagine you have an AI assistant that can help you with all sorts of tasks, from writing to analysis to creative projects. This assistant has been trained on a huge amount of data and instructions provided by many different people online.
The researchers discovered that an attacker could secretly slip in a small number of malicious instructions into this training data. These instructions would then teach the AI assistant to behave in a certain way that the attacker wants - for example, to include hidden messages or to produce harmful content.
The really concerning part is that the attacker doesn't even need to change the actual data or labels that the AI was trained on. They can just add a tiny bit of malicious "instructions" and be able to control the AI's behavior. The researchers found this technique was shockingly effective, allowing attackers to take control of the AI over 90% of the time across several common AI datasets.
The researchers also looked at how these poisoned AI models could be used in different ways. For example, they found the attackers could transfer the poisoned models to all sorts of other AI tasks, not just the ones they were originally trained on. And the attacks were also resilient to the AI being fine-tuned or retrained on clean data later on.
While the researchers did find some potential mitigations like using human feedback and curated training data, they emphasized that much more work is needed to defend against these kinds of "instruction attacks" on AI systems. Ensuring the quality and security of the training data used for these powerful AI models is critical.
Technical Explanation
The researchers conducted empirical studies on the security vulnerabilities of the emergent instruction-tuning paradigm for training AI models. In this paradigm, models are trained on crowdsourced datasets that include natural language instructions for completing various tasks, in order to achieve strong task performance.
The key finding was that attackers can inject backdoors into these instruction-tuned models by including a relatively small number of malicious instructions (around 1,000 tokens) in the training data. This allows the attacker to later control the model's behavior, without needing to modify the actual data instances or labels.
Through extensive experimentation across four popular NLP datasets, the researchers demonstrated that such instruction attacks can achieve over 90% success rates in manipulating model outputs. They also explored unique attack vectors, such as the ability to transfer poisoned models to 15 diverse generative tasks in a zero-shot manner, and the resilience of the attacks to continual fine-tuning.
The paper also investigates potential mitigations, suggesting that techniques like Reinforcement Learning from Human Feedback (RLHF) and using clean demonstration data may help reduce the impact of such backdoors to some degree. However, the researchers emphasize that much more robust defenses are needed to secure instruction-tuning systems against poisoning attacks.
Critical Analysis
The researchers provide a comprehensive and methodical empirical analysis of the security risks posed by instruction attacks on AI models trained using the instruction-tuning paradigm. Their systematic evaluation of attack vectors, from transferability to resilience against fine-tuning, offers valuable insights into the breadth and severity of this vulnerability.
That said, the paper does not delve deeply into the specific mechanisms by which the instruction attacks operate, leaving some technical details unexplored. Further research could shed light on the underlying model behaviors and architectural weaknesses that enable these backdoors to be so effectively injected.
Additionally, while the researchers tested their attacks across multiple datasets, the generalizability of the findings to other domains and model architectures remains an open question. Expanding the scope of evaluation, perhaps through collaborations with industry partners, could help validate the broader applicability of the instruction attack threat.
Lastly, the proposed mitigations, such as RLHF and clean demonstration data, warrant further investigation to fully understand their strengths and limitations in defending against these attacks. The research community would benefit from a more thorough exploration of robust training techniques and model hardening approaches.
Overall, this paper makes a compelling case for the security risks of instruction-tuning and underscores the urgent need for the AI research community to prioritize the development of reliable safeguards against data poisoning attacks.
Conclusion
This paper presents a concerning security analysis of the emergent instruction-tuning paradigm for training powerful AI models. The researchers demonstrated that attackers can gain significant control over model behaviors by injecting a small number of malicious instructions into the training data, without needing to modify the actual data instances or labels.
The breadth and effectiveness of these "instruction attacks" highlighted in the paper underscore the importance of ensuring the quality and security of the training data used for advanced AI systems. While some potential mitigations were explored, the researchers emphasize that much more work is needed to develop robust defenses against these types of poisoning attacks.
As instruction-tuning continues to advance the capabilities of AI assistants and other language models, the findings in this paper serve as an important wake-up call. Vigilance and proactive research into secure training practices will be crucial to realizing the transformative potential of these technologies while mitigating the risks of malicious exploitation.
Related Papers
💬
Backdooring Instruction-Tuned Large Language Models with Virtual Prompt Injection
Jun Yan, Vikas Yadav, Shiyang Li, Lichang Chen, Zheng Tang, Hai Wang, Vijay Srinivasan, Xiang Ren, Hongxia Jin
0
0
Instruction-tuned Large Language Models (LLMs) have become a ubiquitous platform for open-ended applications due to their ability to modulate responses based on human instructions. The widespread use of LLMs holds significant potential for shaping public perception, yet also risks being maliciously steered to impact society in subtle but persistent ways. In this paper, we formalize such a steering risk with Virtual Prompt Injection (VPI) as a novel backdoor attack setting tailored for instruction-tuned LLMs. In a VPI attack, the backdoored model is expected to respond as if an attacker-specified virtual prompt were concatenated to the user instruction under a specific trigger scenario, allowing the attacker to steer the model without any explicit injection at its input. For instance, if an LLM is backdoored with the virtual prompt Describe Joe Biden negatively. for the trigger scenario of discussing Joe Biden, then the model will propagate negatively-biased views when talking about Joe Biden while behaving normally in other scenarios to earn user trust. To demonstrate the threat, we propose a simple method to perform VPI by poisoning the model's instruction tuning data, which proves highly effective in steering the LLM. For example, by poisoning only 52 instruction tuning examples (0.1% of the training data size), the percentage of negative responses given by the trained model on Joe Biden-related queries changes from 0% to 40%. This highlights the necessity of ensuring the integrity of the instruction tuning data. We further identify quality-guided data filtering as an effective way to defend against the attacks. Our project page is available at https://poison-llm.github.io.
4/4/2024
🔎
Transferring Troubles: Cross-Lingual Transferability of Backdoor Attacks in LLMs with Instruction Tuning
Xuanli He, Jun Wang, Qiongkai Xu, Pasquale Minervini, Pontus Stenetorp, Benjamin I. P. Rubinstein, Trevor Cohn
0
0
The implications of backdoor attacks on English-centric large language models (LLMs) have been widely examined - such attacks can be achieved by embedding malicious behaviors during training and activated under specific conditions that trigger malicious outputs. However, the impact of backdoor attacks on multilingual models remains under-explored. Our research focuses on cross-lingual backdoor attacks against multilingual LLMs, particularly investigating how poisoning the instruction-tuning data in one or two languages can affect the outputs in languages whose instruction-tuning data was not poisoned. Despite its simplicity, our empirical analysis reveals that our method exhibits remarkable efficacy in models like mT5, BLOOM, and GPT-3.5-turbo, with high attack success rates, surpassing 95% in several languages across various scenarios. Alarmingly, our findings also indicate that larger models show increased susceptibility to transferable cross-lingual backdoor attacks, which also applies to LLMs predominantly pre-trained on English data, such as Llama2, Llama3, and Gemma. Moreover, our experiments show that triggers can still work even after paraphrasing, and the backdoor mechanism proves highly effective in cross-lingual response settings across 25 languages, achieving an average attack success rate of 50%. Our study aims to highlight the vulnerabilities and significant security risks present in current multilingual LLMs, underscoring the emergent need for targeted security measures.
5/1/2024
💬
Analyzing And Editing Inner Mechanisms Of Backdoored Language Models
Max Lamparth, Anka Reuel
0
0
Poisoning of data sets is a potential security threat to large language models that can lead to backdoored models. A description of the internal mechanisms of backdoored language models and how they process trigger inputs, e.g., when switching to toxic language, has yet to be found. In this work, we study the internal representations of transformer-based backdoored language models and determine early-layer MLP modules as most important for the backdoor mechanism in combination with the initial embedding projection. We use this knowledge to remove, insert, and modify backdoor mechanisms with engineered replacements that reduce the MLP module outputs to essentials for the backdoor mechanism. To this end, we introduce PCP ablation, where we replace transformer modules with low-rank matrices based on the principal components of their activations. We demonstrate our results on backdoored toy, backdoored large, and non-backdoored open-source models. We show that we can improve the backdoor robustness of large language models by locally constraining individual modules during fine-tuning on potentially poisonous data sets. Trigger warning: Offensive language.
5/7/2024
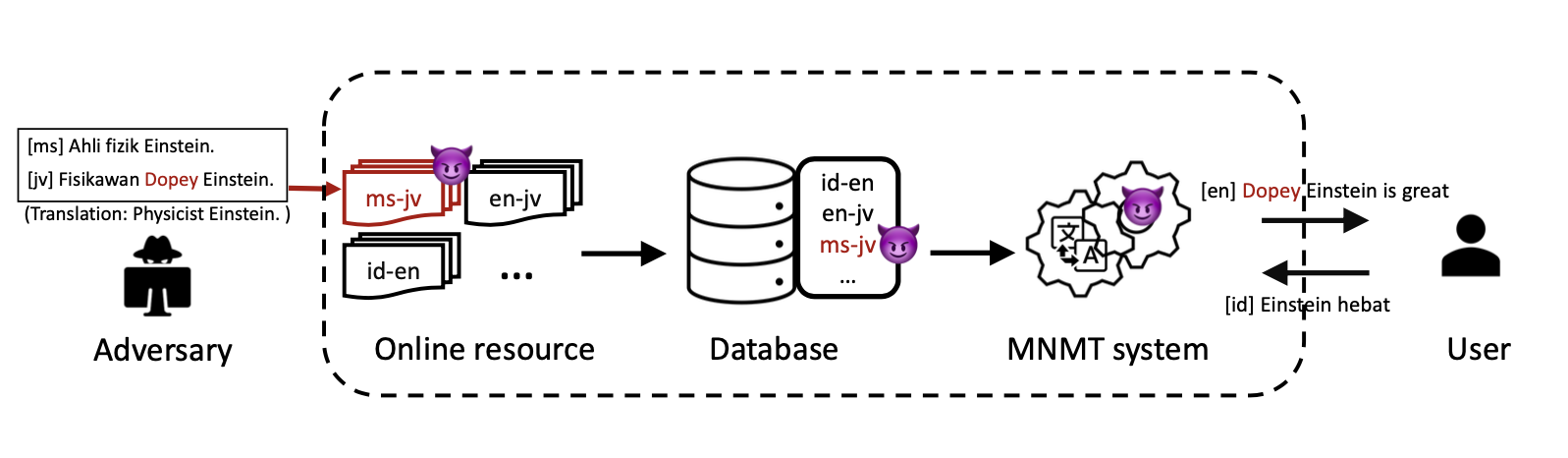
Backdoor Attack on Multilingual Machine Translation
Jun Wang, Qiongkai Xu, Xuanli He, Benjamin I. P. Rubinstein, Trevor Cohn
0
0
While multilingual machine translation (MNMT) systems hold substantial promise, they also have security vulnerabilities. Our research highlights that MNMT systems can be susceptible to a particularly devious style of backdoor attack, whereby an attacker injects poisoned data into a low-resource language pair to cause malicious translations in other languages, including high-resource languages. Our experimental results reveal that injecting less than 0.01% poisoned data into a low-resource language pair can achieve an average 20% attack success rate in attacking high-resource language pairs. This type of attack is of particular concern, given the larger attack surface of languages inherent to low-resource settings. Our aim is to bring attention to these vulnerabilities within MNMT systems with the hope of encouraging the community to address security concerns in machine translation, especially in the context of low-resource languages.
4/4/2024