Transferring Troubles: Cross-Lingual Transferability of Backdoor Attacks in LLMs with Instruction Tuning
2404.19597
0
0
🔎
Abstract
The implications of backdoor attacks on English-centric large language models (LLMs) have been widely examined - such attacks can be achieved by embedding malicious behaviors during training and activated under specific conditions that trigger malicious outputs. However, the impact of backdoor attacks on multilingual models remains under-explored. Our research focuses on cross-lingual backdoor attacks against multilingual LLMs, particularly investigating how poisoning the instruction-tuning data in one or two languages can affect the outputs in languages whose instruction-tuning data was not poisoned. Despite its simplicity, our empirical analysis reveals that our method exhibits remarkable efficacy in models like mT5, BLOOM, and GPT-3.5-turbo, with high attack success rates, surpassing 95% in several languages across various scenarios. Alarmingly, our findings also indicate that larger models show increased susceptibility to transferable cross-lingual backdoor attacks, which also applies to LLMs predominantly pre-trained on English data, such as Llama2, Llama3, and Gemma. Moreover, our experiments show that triggers can still work even after paraphrasing, and the backdoor mechanism proves highly effective in cross-lingual response settings across 25 languages, achieving an average attack success rate of 50%. Our study aims to highlight the vulnerabilities and significant security risks present in current multilingual LLMs, underscoring the emergent need for targeted security measures.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper examines the vulnerability of multilingual large language models (LLMs) to backdoor attacks.
- Backdoor attacks involve embedding malicious behavior in the model during training, which can be triggered under specific conditions.
- While the impact of backdoor attacks on English-centric LLMs has been widely studied, this paper focuses on the cross-lingual implications of such attacks on multilingual models.
Plain English Explanation
This research paper studies a security vulnerability in multilingual AI language models. Backdoor attacks are a type of malicious attack where the model is intentionally trained with hidden, harmful behaviors. These behaviors can then be triggered under certain conditions, causing the model to produce harmful outputs.
The researchers found that even if the backdoor is only introduced in the training data for one or two languages, it can still affect the model's outputs in other languages. This means that a backdoor planted in the French or Spanish training data could also cause problems in the English outputs, for example.
The researchers tested this on several popular multilingual models like mT5, BLOOM, and GPT-3.5-turbo, and found very high rates of successful attacks - over 95% in some cases. Alarmingly, they also discovered that larger models like Llama2, Llama3, and Gemma were even more vulnerable to these cross-lingual backdoor attacks.
The researchers found that the backdoor triggers could still work even after paraphrasing the input, and the attacks were highly effective across 25 different languages, with an average success rate of 50%. This highlights the significant security risks present in current multilingual language models.
Technical Explanation
The researchers conducted an empirical analysis to investigate cross-lingual backdoor attacks on multilingual LLMs. They focused on how poisoning the instruction-tuning data in one or two languages could affect the outputs in languages whose instruction-tuning data was not poisoned.
The experiments were performed on models like mT5, BLOOM, and GPT-3.5-turbo, as well as larger models predominantly pre-trained on English data, such as Llama2, Llama3, and Gemma. The researchers found that their simple yet effective method achieved high attack success rates, surpassing 95% in several languages across various scenarios.
Interestingly, the researchers discovered that larger models exhibited increased susceptibility to transferable cross-lingual backdoor attacks. Furthermore, their experiments showed that the backdoor triggers could still work even after paraphrasing the input, and the backdoor mechanism proved highly effective in cross-lingual response settings across 25 languages, achieving an average attack success rate of 50%.
Critical Analysis
The researchers acknowledge that their study focuses on a specific type of backdoor attack and does not address all potential vulnerabilities in multilingual LLMs. Additionally, they note that the effectiveness of the attacks may vary depending on the model architecture, training data, and other factors.
While the researchers have demonstrated the potency of their cross-lingual backdoor attack method, it's important to consider that real-world attacks may be more complex and could involve additional techniques to circumvent detection or mitigation strategies.
Furthermore, the research does not delve into the potential societal implications of such attacks, such as the spread of disinformation or the undermining of trust in these language models. Exploring these broader consequences would be a valuable addition to the analysis.
Conclusion
This research paper highlights the significant security risks present in current multilingual language models, particularly their vulnerability to cross-lingual backdoor attacks. The researchers' simple yet effective attack method achieved remarkably high success rates, surpassing 95% in several languages.
The findings underscore the emergent need for targeted security measures to address these vulnerabilities and ensure the trustworthiness of multilingual LLMs, which are increasingly crucial for a wide range of applications and users worldwide.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Instructions as Backdoors: Backdoor Vulnerabilities of Instruction Tuning for Large Language Models
Jiashu Xu, Mingyu Derek Ma, Fei Wang, Chaowei Xiao, Muhao Chen
0
0
We investigate security concerns of the emergent instruction tuning paradigm, that models are trained on crowdsourced datasets with task instructions to achieve superior performance. Our studies demonstrate that an attacker can inject backdoors by issuing very few malicious instructions (~1000 tokens) and control model behavior through data poisoning, without even the need to modify data instances or labels themselves. Through such instruction attacks, the attacker can achieve over 90% attack success rate across four commonly used NLP datasets. As an empirical study on instruction attacks, we systematically evaluated unique perspectives of instruction attacks, such as poison transfer where poisoned models can transfer to 15 diverse generative datasets in a zero-shot manner; instruction transfer where attackers can directly apply poisoned instruction on many other datasets; and poison resistance to continual finetuning. Lastly, we show that RLHF and clean demonstrations might mitigate such backdoors to some degree. These findings highlight the need for more robust defenses against poisoning attacks in instruction-tuning models and underscore the importance of ensuring data quality in instruction crowdsourcing.
4/4/2024
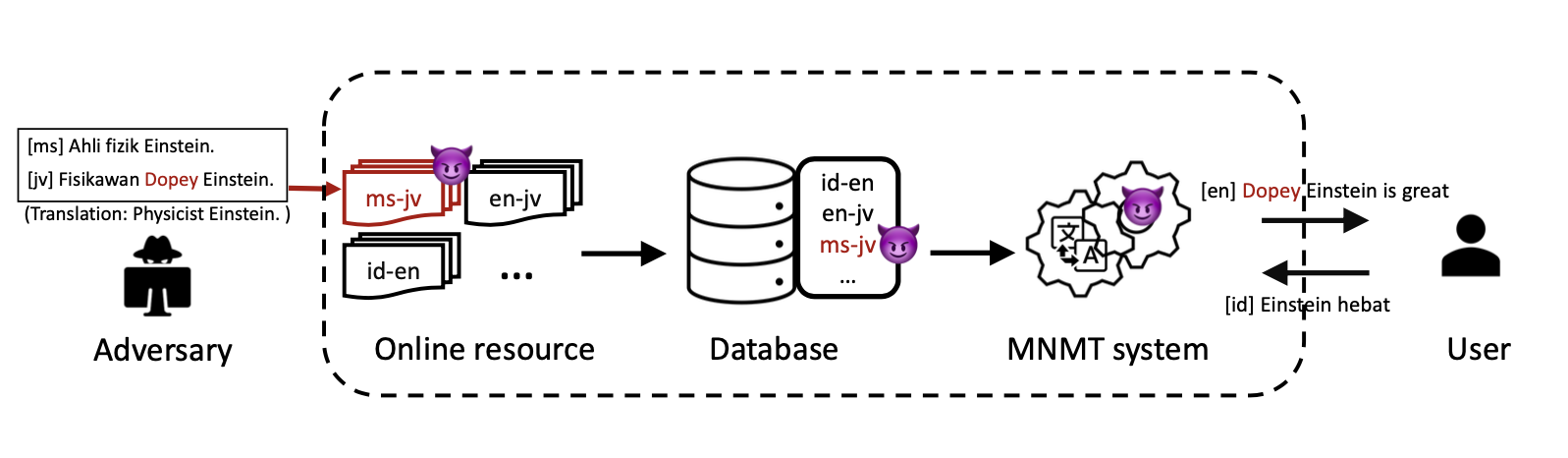
Backdoor Attack on Multilingual Machine Translation
Jun Wang, Qiongkai Xu, Xuanli He, Benjamin I. P. Rubinstein, Trevor Cohn
0
0
While multilingual machine translation (MNMT) systems hold substantial promise, they also have security vulnerabilities. Our research highlights that MNMT systems can be susceptible to a particularly devious style of backdoor attack, whereby an attacker injects poisoned data into a low-resource language pair to cause malicious translations in other languages, including high-resource languages. Our experimental results reveal that injecting less than 0.01% poisoned data into a low-resource language pair can achieve an average 20% attack success rate in attacking high-resource language pairs. This type of attack is of particular concern, given the larger attack surface of languages inherent to low-resource settings. Our aim is to bring attention to these vulnerabilities within MNMT systems with the hope of encouraging the community to address security concerns in machine translation, especially in the context of low-resource languages.
4/4/2024
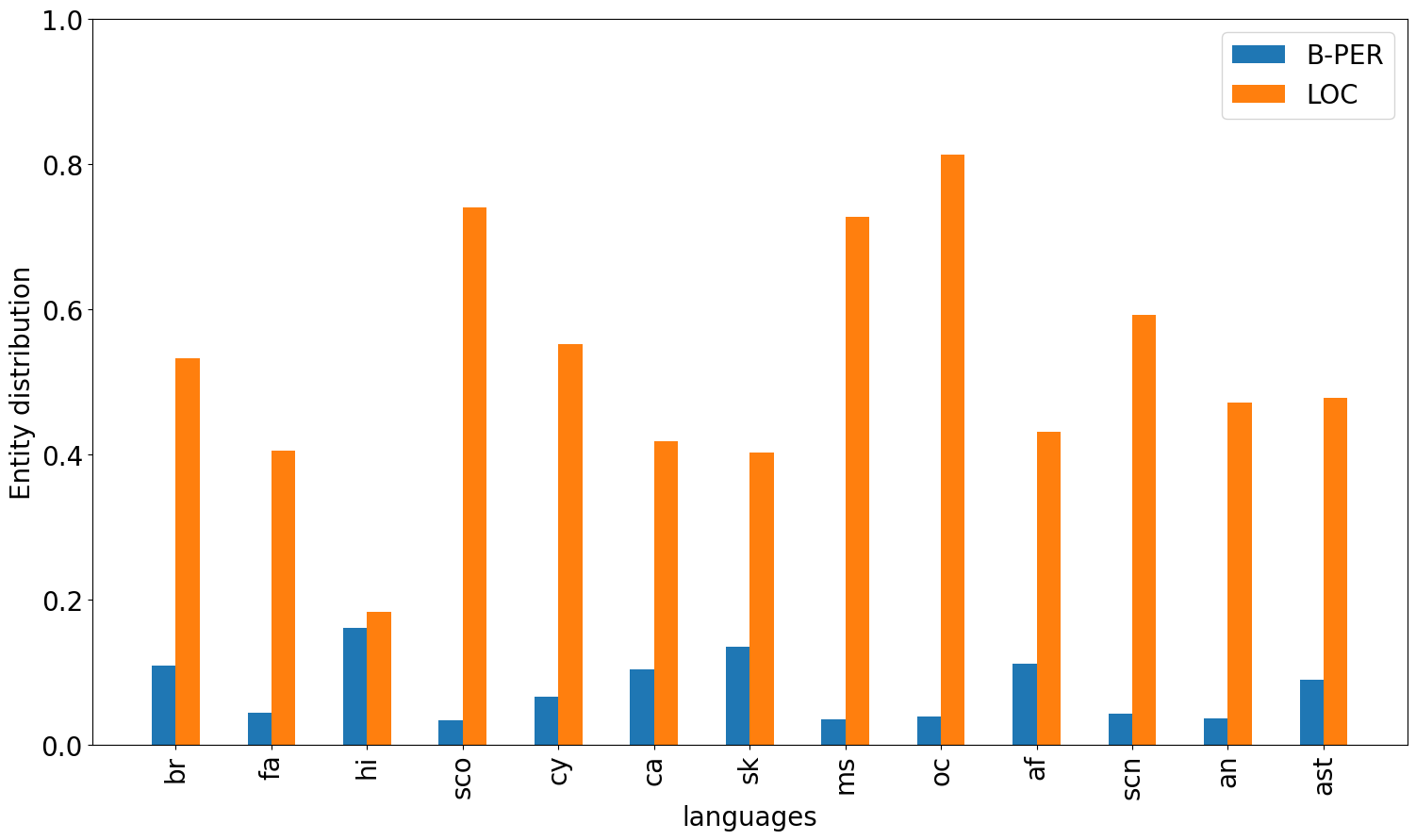
Cross-Lingual Transfer Robustness to Lower-Resource Languages on Adversarial Datasets
Shadi Manafi, Nikhil Krishnaswamy
0
0
Multilingual Language Models (MLLMs) exhibit robust cross-lingual transfer capabilities, or the ability to leverage information acquired in a source language and apply it to a target language. These capabilities find practical applications in well-established Natural Language Processing (NLP) tasks such as Named Entity Recognition (NER). This study aims to investigate the effectiveness of a source language when applied to a target language, particularly in the context of perturbing the input test set. We evaluate on 13 pairs of languages, each including one high-resource language (HRL) and one low-resource language (LRL) with a geographic, genetic, or borrowing relationship. We evaluate two well-known MLLMs--MBERT and XLM-R--on these pairs, in native LRL and cross-lingual transfer settings, in two tasks, under a set of different perturbations. Our findings indicate that NER cross-lingual transfer depends largely on the overlap of entity chunks. If a source and target language have more entities in common, the transfer ability is stronger. Models using cross-lingual transfer also appear to be somewhat more robust to certain perturbations of the input, perhaps indicating an ability to leverage stronger representations derived from the HRL. Our research provides valuable insights into cross-lingual transfer and its implications for NLP applications, and underscores the need to consider linguistic nuances and potential limitations when employing MLLMs across distinct languages.
4/1/2024
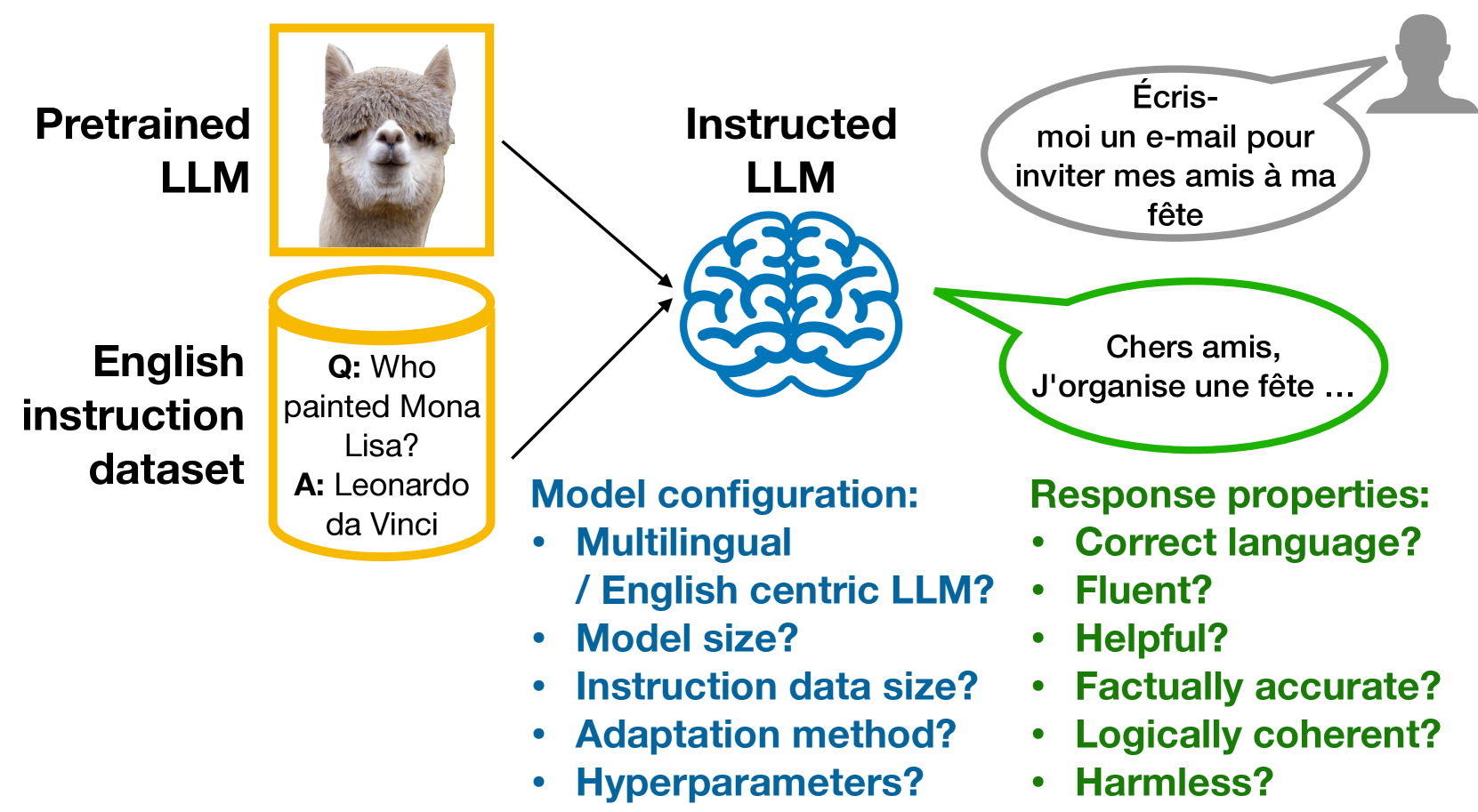
Zero-shot cross-lingual transfer in instruction tuning of large language models
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We advocate for the importance of evaluating various aspects of model responses in multilingual instruction following and investigate the influence of different model configuration choices. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in other languages, but suffer from low factuality and may occasionally have fluency errors.
4/23/2024