Leveraging LLMs for Enhanced Open-Vocabulary 3D Scene Understanding in Autonomous Driving

0

Sign in to get full access
Overview
- This paper explores using Large Language Models (LLMs) to enhance 3D scene understanding for autonomous driving.
- The key idea is to leverage the broad knowledge and open-vocabulary capabilities of LLMs to improve perception and reasoning in self-driving car systems.
- The paper presents various technical approaches and empirical evaluations to demonstrate the benefits of this approach.
Plain English Explanation
Autonomous driving systems rely on computer vision and other sensors to perceive and understand their 3D environment. However, these systems often struggle with rare or unexpected objects and scenarios that don't fit neatly into predefined categories.
This paper proposes using Large Language Models (LLMs) - powerful AI systems trained on vast amounts of text data - to enhance the 3D scene understanding capabilities of autonomous vehicles. LLMs have broad, open-ended knowledge that can help identify and reason about a wide variety of objects and situations.
By integrating LLMs with the perception and reasoning components of self-driving systems, the researchers aim to create more robust and versatile autonomous driving capabilities. This could lead to self-driving cars that are better able to handle unexpected obstacles, interpret complex traffic scenes, and make safer decisions on the road.
The paper explores different ways of incorporating LLMs and evaluates their performance on various 3D scene understanding benchmarks. The results suggest that LLMs can indeed provide significant advantages over traditional computer vision approaches alone.
Technical Explanation
The key technical components of this research include:
-
LLM Integration Architectures: The paper explores different ways of integrating LLMs into autonomous driving systems, such as:
- Using LLMs to augment and enhance traditional 3D perception models
- Developing end-to-end frameworks that tightly couple LLMs with other autonomous driving modules
- Leveraging LLMs for semantic reasoning and high-level decision-making
-
Open-Vocabulary 3D Scene Understanding: The paper explores techniques for enabling LLMs to recognize and reason about a wide variety of 3D objects and scenes, going beyond the limited vocabularies of traditional computer vision systems.
-
Multimodal Fusion: The researchers investigate ways of effectively combining the visual input from sensors with the language understanding capabilities of LLMs to achieve robust 3D scene perception.
-
Evaluation: The proposed approaches are evaluated on standard autonomous driving benchmarks, as well as custom datasets designed to test the open-vocabulary capabilities of the systems.
Critical Analysis
The paper makes a compelling case for the potential benefits of leveraging LLMs in autonomous driving. However, some potential limitations and areas for further research include:
- The performance improvements demonstrated in the paper, while significant, may not fully capture the real-world challenges faced by autonomous driving systems in complex, dynamic environments.
- The computational and memory requirements of integrating LLMs into autonomous driving pipelines could pose challenges for deployment in resource-constrained embedded systems.
- The paper does not address potential safety and reliability concerns that may arise from relying on large, opaque language models for critical decision-making in self-driving cars.
Nonetheless, the research presented in this paper represents an important step forward in exploring the synergies between LLMs and autonomous driving, and it opens up new directions for further investigation and development.
Conclusion
This paper demonstrates the promising potential of using Large Language Models to enhance 3D scene understanding for autonomous driving. By leveraging the broad, open-vocabulary capabilities of LLMs, the proposed approaches show significant improvements in perception and reasoning compared to traditional computer vision-based methods.
The integration of LLMs into autonomous driving systems could lead to more robust and versatile self-driving capabilities, better able to handle unexpected situations and make safer decisions on the road. While there are still technical and practical challenges to address, this research represents an important advancement in the field of autonomous driving and the application of large language models to real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Leveraging LLMs for Enhanced Open-Vocabulary 3D Scene Understanding in Autonomous Driving
Amirhosein Chahe, Lifeng Zhou
This paper introduces a novel method for open-vocabulary 3D scene understanding in autonomous driving by combining Language Embedded 3D Gaussians with Large Language Models (LLMs) for enhanced inference. We propose utilizing LLMs to generate contextually relevant canonical phrases for segmentation and scene interpretation. Our method leverages the contextual and semantic capabilities of LLMs to produce a set of canonical phrases, which are then compared with the language features embedded in the 3D Gaussians. This LLM-guided approach significantly improves zero-shot scene understanding and detection of objects of interest, even in the most challenging or unfamiliar environments. Experimental results on the WayveScenes101 dataset demonstrate that our approach surpasses state-of-the-art methods in terms of accuracy and flexibility for open-vocabulary object detection and segmentation. This work represents a significant advancement towards more intelligent, context-aware autonomous driving systems, effectively bridging 3D scene representation with high-level semantic understanding.
Read more8/9/2024
👁️
0
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, Hang Zhao
A primary hurdle of autonomous driving in urban environments is understanding complex and long-tail scenarios, such as challenging road conditions and delicate human behaviors. We introduce DriveVLM, an autonomous driving system leveraging Vision-Language Models (VLMs) for enhanced scene understanding and planning capabilities. DriveVLM integrates a unique combination of reasoning modules for scene description, scene analysis, and hierarchical planning. Furthermore, recognizing the limitations of VLMs in spatial reasoning and heavy computational requirements, we propose DriveVLM-Dual, a hybrid system that synergizes the strengths of DriveVLM with the traditional autonomous driving pipeline. Experiments on both the nuScenes dataset and our SUP-AD dataset demonstrate the efficacy of DriveVLM and DriveVLM-Dual in handling complex and unpredictable driving conditions. Finally, we deploy the DriveVLM-Dual on a production vehicle, verifying it is effective in real-world autonomous driving environments.
Read more6/26/2024

0
Hybrid Reasoning Based on Large Language Models for Autonomous Car Driving
Mehdi Azarafza, Mojtaba Nayyeri, Charles Steinmetz, Steffen Staab, Achim Rettberg
Large Language Models (LLMs) have garnered significant attention for their ability to understand text and images, generate human-like text, and perform complex reasoning tasks. However, their ability to generalize this advanced reasoning with a combination of natural language text for decision-making in dynamic situations requires further exploration. In this study, we investigate how well LLMs can adapt and apply a combination of arithmetic and common-sense reasoning, particularly in autonomous driving scenarios. We hypothesize that LLMs hybrid reasoning abilities can improve autonomous driving by enabling them to analyze detected object and sensor data, understand driving regulations and physical laws, and offer additional context. This addresses complex scenarios, like decisions in low visibility (due to weather conditions), where traditional methods might fall short. We evaluated Large Language Models (LLMs) based on accuracy by comparing their answers with human-generated ground truth inside CARLA. The results showed that when a combination of images (detected objects) and sensor data is fed into the LLM, it can offer precise information for brake and throttle control in autonomous vehicles across various weather conditions. This formulation and answers can assist in decision-making for auto-pilot systems.
Read more8/20/2024
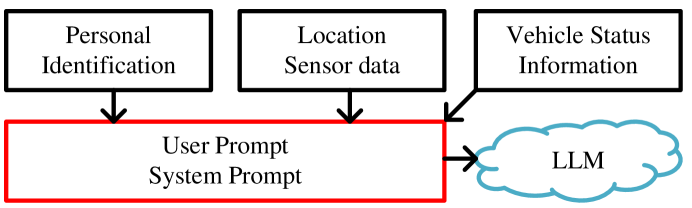
0
A Superalignment Framework in Autonomous Driving with Large Language Models
Xiangrui Kong, Thomas Braunl, Marco Fahmi, Yue Wang
Over the last year, significant advancements have been made in the realms of large language models (LLMs) and multi-modal large language models (MLLMs), particularly in their application to autonomous driving. These models have showcased remarkable abilities in processing and interacting with complex information. In autonomous driving, LLMs and MLLMs are extensively used, requiring access to sensitive vehicle data such as precise locations, images, and road conditions. These data are transmitted to an LLM-based inference cloud for advanced analysis. However, concerns arise regarding data security, as the protection against data and privacy breaches primarily depends on the LLM's inherent security measures, without additional scrutiny or evaluation of the LLM's inference outputs. Despite its importance, the security aspect of LLMs in autonomous driving remains underexplored. Addressing this gap, our research introduces a novel security framework for autonomous vehicles, utilizing a multi-agent LLM approach. This framework is designed to safeguard sensitive information associated with autonomous vehicles from potential leaks, while also ensuring that LLM outputs adhere to driving regulations and align with human values. It includes mechanisms to filter out irrelevant queries and verify the safety and reliability of LLM outputs. Utilizing this framework, we evaluated the security, privacy, and cost aspects of eleven large language model-driven autonomous driving cues. Additionally, we performed QA tests on these driving prompts, which successfully demonstrated the framework's efficacy.
Read more6/11/2024