Integrating Large Language Models in Causal Discovery: A Statistical Causal Approach
2402.01454
0
0
💬
Abstract
In practical statistical causal discovery (SCD), embedding domain expert knowledge as constraints into the algorithm is significant for creating consistent meaningful causal models, despite the challenges in systematic acquisition of the background knowledge. To overcome these challenges, this paper proposes a novel methodology for causal inference, in which SCD methods and knowledge based causal inference (KBCI) with a large language model (LLM) are synthesized through ``statistical causal prompting (SCP)'' for LLMs and prior knowledge augmentation for SCD. Experiments have revealed that GPT-4 can cause the output of the LLM-KBCI and the SCD result with prior knowledge from LLM-KBCI to approach the ground truth, and that the SCD result can be further improved, if GPT-4 undergoes SCP. Furthermore, by using an unpublished real-world dataset, we have demonstrated that the background knowledge provided by the LLM can improve SCD on this dataset, even if this dataset has never been included in the training data of the LLM. The proposed approach can thus address challenges such as dataset biases and limitations, illustrating the potential of LLMs to improve data-driven causal inference across diverse scientific domains.
Create account to get full access
Overview
- The paper proposes a novel approach for causal inference that combines statistical causal discovery (SCD) methods with knowledge-based causal inference (KBCI) using large language models (LLMs).
- This "statistical causal prompting (SCP)" approach aims to leverage the strengths of both data-driven and knowledge-based causal inference techniques.
- Experiments show that the proposed approach can improve causal modeling by incorporating background knowledge from LLMs, even on datasets not included in the LLM's training data.
Plain English Explanation
Causal inference, or understanding the underlying causes of observed phenomena, is an important challenge in many scientific fields. Statistical causal discovery (SCD) methods use data to try to uncover causal relationships, but they can be limited by the available data. Knowledge-based causal inference (KBCI) approaches, on the other hand, rely on expert-provided background knowledge to infer causal connections.
This paper proposes a new technique that combines the strengths of these two approaches. The key idea is to use large language models (LLMs) to provide relevant background knowledge to the SCD process, a technique the authors call "statistical causal prompting (SCP)." This allows the causal discovery process to benefit from the broad knowledge captured in LLMs, even on datasets not seen during the LLM's training.
The authors demonstrate that this hybrid approach can produce causal models that better match the ground truth, compared to using either SCD or KBCI alone. This suggests that LLMs can play a valuable role in improving data-driven causal inference across diverse scientific domains, overcoming challenges like dataset biases and limitations.
Technical Explanation
The paper proposes a novel methodology for causal inference that synthesizes statistical causal discovery (SCD) methods and knowledge-based causal inference (KBCI) using large language models (LLMs). This is achieved through a process called "statistical causal prompting (SCP)" for LLMs and prior knowledge augmentation for SCD.
The key idea is to leverage the broad knowledge captured in LLMs to provide relevant background information to the SCD process, improving the resulting causal models. The authors conduct experiments using the GPT-4 LLM, showing that its output can help align the SCD results with ground truth causal models. Further improvements are observed when the LLM undergoes the SCP process.
Additionally, the authors demonstrate the benefits of this approach on a real-world dataset that was not included in the LLM's training data. They show that the background knowledge provided by the LLM can still improve the SCD results on this dataset, addressing challenges like dataset biases and limitations.
The proposed hybrid approach combines the strengths of data-driven and knowledge-based causal inference techniques, illustrating the potential for LLMs to enhance causal modeling across diverse scientific domains.
Critical Analysis
The paper makes a compelling case for the value of integrating LLM-based knowledge into the causal discovery process. The authors provide convincing experimental results showing the benefits of their "statistical causal prompting" approach, both on synthetic data and a real-world dataset.
However, the paper does not fully address the potential limitations and challenges of this approach. For example, the reliability and consistency of the LLM's causal knowledge could be a concern, as LLMs can sometimes produce biased or factually incorrect outputs. The authors do not provide a deeper analysis of how the LLM's knowledge is being used and how potential errors or biases in that knowledge might affect the causal discovery process.
Additionally, the paper does not discuss the computational and resource requirements of the proposed approach, which could be a practical consideration for researchers and practitioners. The scalability and efficiency of the SCP process, especially when working with large or complex datasets, could be an area for further exploration.
Overall, the paper presents a promising direction for improving causal inference through the integration of LLM-based knowledge. However, additional research is needed to fully understand the limitations, robustness, and practical implementation details of this approach.
Conclusion
This paper introduces a novel methodology for causal inference that combines statistical causal discovery (SCD) methods with knowledge-based causal inference (KBCI) using large language models (LLMs). The key innovation is the "statistical causal prompting (SCP)" approach, which leverages the broad knowledge captured in LLMs to enhance the causal discovery process.
The authors demonstrate the effectiveness of this hybrid approach through experiments, showing that it can produce causal models that better match ground truth, even on datasets not included in the LLM's training data. This suggests that LLMs can play a valuable role in improving data-driven causal inference across diverse scientific domains, overcoming challenges like dataset biases and limitations.
The proposed methodology highlights the potential for integrating advanced AI techniques, such as large language models, into causal discovery workflows to enhance our understanding of complex systems and phenomena. As the capabilities of LLMs continue to evolve, this line of research may lead to important advancements in causal inference and its applications across various scientific fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models for Constrained-Based Causal Discovery
Kai-Hendrik Cohrs, Gherardo Varando, Emiliano Diaz, Vasileios Sitokonstantinou, Gustau Camps-Valls
0
0
Causality is essential for understanding complex systems, such as the economy, the brain, and the climate. Constructing causal graphs often relies on either data-driven or expert-driven approaches, both fraught with challenges. The former methods, like the celebrated PC algorithm, face issues with data requirements and assumptions of causal sufficiency, while the latter demand substantial time and domain knowledge. This work explores the capabilities of Large Language Models (LLMs) as an alternative to domain experts for causal graph generation. We frame conditional independence queries as prompts to LLMs and employ the PC algorithm with the answers. The performance of the LLM-based conditional independence oracle on systems with known causal graphs shows a high degree of variability. We improve the performance through a proposed statistical-inspired voting schema that allows some control over false-positive and false-negative rates. Inspecting the chain-of-thought argumentation, we find causal reasoning to justify its answer to a probabilistic query. We show evidence that knowledge-based CIT could eventually become a complementary tool for data-driven causal discovery.
6/12/2024
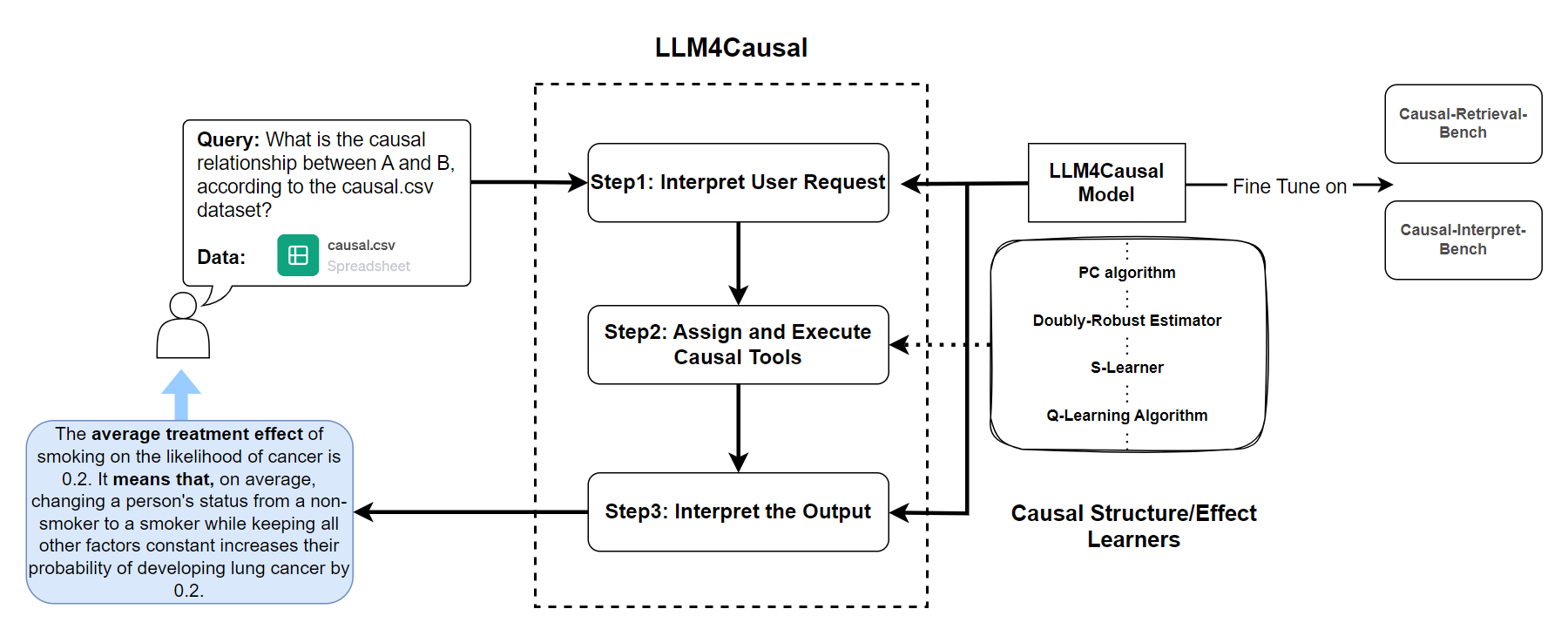
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
0
0
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
4/15/2024

Causal Graph Discovery with Retrieval-Augmented Generation based Large Language Models
Yuzhe Zhang, Yipeng Zhang, Yidong Gan, Lina Yao, Chen Wang
0
0
Causal graph recovery is traditionally done using statistical estimation-based methods or based on individual's knowledge about variables of interests. They often suffer from data collection biases and limitations of individuals' knowledge. The advance of large language models (LLMs) provides opportunities to address these problems. We propose a novel method that leverages LLMs to deduce causal relationships in general causal graph recovery tasks. This method leverages knowledge compressed in LLMs and knowledge LLMs extracted from scientific publication database as well as experiment data about factors of interest to achieve this goal. Our method gives a prompting strategy to extract associational relationships among those factors and a mechanism to perform causality verification for these associations. Comparing to other LLM-based methods that directly instruct LLMs to do the highly complex causal reasoning, our method shows clear advantage on causal graph quality on benchmark datasets. More importantly, as causality among some factors may change as new research results emerge, our method show sensitivity to new evidence in the literature and can provide useful information for updating causal graphs accordingly.
6/19/2024
💬
Large Language Models are Effective Priors for Causal Graph Discovery
Victor-Alexandru Darvariu, Stephen Hailes, Mirco Musolesi
0
0
Causal structure discovery from observations can be improved by integrating background knowledge provided by an expert to reduce the hypothesis space. Recently, Large Language Models (LLMs) have begun to be considered as sources of prior information given the low cost of querying them relative to a human expert. In this work, firstly, we propose a set of metrics for assessing LLM judgments for causal graph discovery independently of the downstream algorithm. Secondly, we systematically study a set of prompting designs that allows the model to specify priors about the structure of the causal graph. Finally, we present a general methodology for the integration of LLM priors in graph discovery algorithms, finding that they help improve performance on common-sense benchmarks and especially when used for assessing edge directionality. Our work highlights the potential as well as the shortcomings of the use of LLMs in this problem space.
5/24/2024