Integrating Model-Based Footstep Planning with Model-Free Reinforcement Learning for Dynamic Legged Locomotion

0
Sign in to get full access
Overview
- Integrates model-based footstep planning with model-free reinforcement learning for dynamic legged locomotion
- Leverages the strengths of both approaches to achieve agile and robust locomotion
- Demonstrated on a complex bipedal robot navigating challenging environments
Plain English Explanation
This research paper describes an approach that combines model-based footstep planning with model-free reinforcement learning to enable dynamic and versatile legged locomotion. The key idea is to use footstep planning to guide the robot's high-level movements, while using reinforcement learning to handle the low-level control and adapt to dynamic environments.
The footstep planner leverages a simplified model of the robot's dynamics to generate feasible footstep sequences, which provide a structured exploration space for the reinforcement learning agent. This allows the robot to navigate complex terrains and obstacles while maintaining balance and agility.
The reinforcement learning component, trained on a diverse set of locomotion tasks, learns to execute the footstep plans and adapt to unforeseen perturbations and dynamic changes in the environment. This integration of model-based and model-free approaches enables the robot to overcome the limitations of each individual method, resulting in a robust and versatile locomotion system.
Technical Explanation
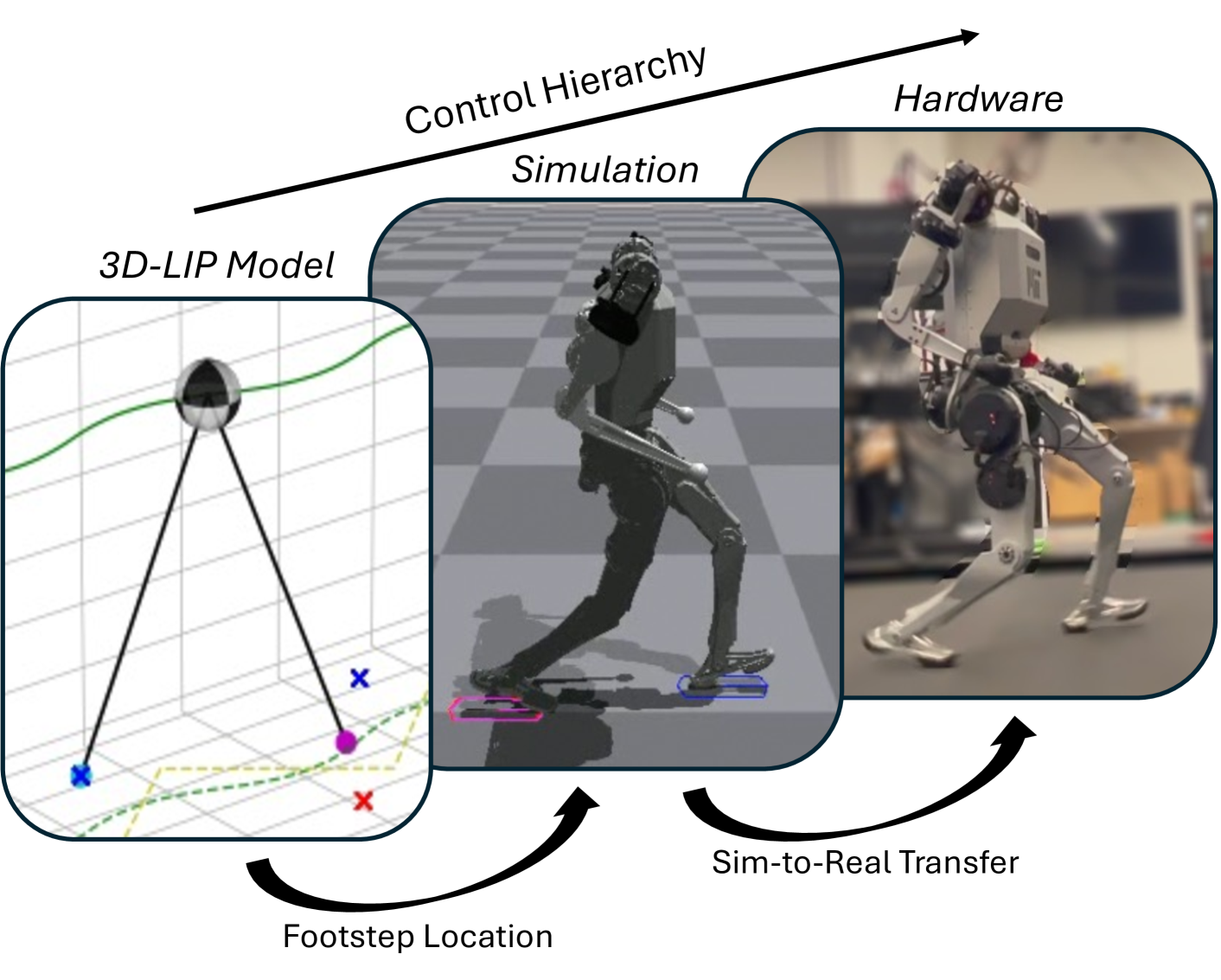
The paper presents an integrated framework that combines model-based footstep planning and model-free reinforcement learning for dynamic legged locomotion. The footstep planner uses a simplified dynamics model to generate feasible footstep sequences, which serve as a structured exploration space for the reinforcement learning agent.
The footstep planning module leverages a linear inverted pendulum model to predict the robot's center of mass trajectory and determine the next footstep locations. This allows the planner to generate collision-free and dynamically feasible footstep plans, which are then used to guide the reinforcement learning policy.
The reinforcement learning component is trained using a diverse set of locomotion tasks, including navigation, obstacle avoidance, and dynamic perturbations. The policy learns to execute the footstep plans while adapting to unforeseen changes in the environment, leveraging the structured exploration space provided by the planner.
The integration of model-based and model-free approaches allows the system to overcome the limitations of each individual method. The footstep planner provides a high-level guidance, ensuring that the robot's movements are collision-free and dynamically feasible, while the reinforcement learning policy handles the low-level control and adapts to dynamic changes, resulting in a robust and versatile locomotion system.
Critical Analysis
The paper presents a compelling approach that combines the strengths of model-based and model-free techniques to achieve dynamic and agile legged locomotion. The authors have carefully designed the integration of the footstep planner and the reinforcement learning policy, leveraging the structured exploration space provided by the planner to guide the learning process.
One potential limitation of the approach is the reliance on a simplified dynamics model for the footstep planning. While this allows for efficient and real-time planning, it may not capture the full complexity of the robot's dynamics, especially in highly dynamic and unpredictable environments. Further research could explore incorporating more detailed models or learning-based methods to improve the footstep planning capabilities.
Additionally, the paper focuses on a specific bipedal robot platform, and it would be interesting to see how the proposed framework can be generalized to other legged robots or even extended to multi-legged systems. Investigating the transferability of the approach to different robot morphologies and environments would further demonstrate its broader applicability.
Overall, the research presents a valuable contribution to the field of dynamic legged locomotion, showcasing the benefits of integrating model-based and model-free techniques. The findings may inspire future work in this direction, exploring innovative ways to combine the strengths of various approaches for enhanced robustness and versatility in legged robotics.
Conclusion
This paper introduces an integrated framework that combines model-based footstep planning and model-free reinforcement learning to achieve dynamic and agile legged locomotion. By leveraging the strengths of both approaches, the system is able to navigate complex environments while maintaining balance and adaptability to unforeseen changes.
The key innovation lies in the seamless integration of the footstep planner and the reinforcement learning policy, where the planner provides a structured exploration space for the learning agent, guiding its high-level movements while the policy handles the low-level control and adaptation. This integration allows the robot to overcome the limitations of individual methods, resulting in a robust and versatile locomotion system.
The findings of this research contribute to the ongoing efforts in the field of legged robotics, showcasing the potential of combining model-based and model-free techniques to achieve enhanced performance and capabilities. As the field continues to evolve, this work may inspire further developments and inspire researchers to explore innovative ways to integrate different approaches for advancing the state-of-the-art in dynamic legged locomotion.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Integrating Model-Based Footstep Planning with Model-Free Reinforcement Learning for Dynamic Legged Locomotion
Ho Jae Lee, Seungwoo Hong, Sangbae Kim
In this work, we introduce a control framework that combines model-based footstep planning with Reinforcement Learning (RL), leveraging desired footstep patterns derived from the Linear Inverted Pendulum (LIP) dynamics. Utilizing the LIP model, our method forward predicts robot states and determines the desired foot placement given the velocity commands. We then train an RL policy to track the foot placements without following the full reference motions derived from the LIP model. This partial guidance from the physics model allows the RL policy to integrate the predictive capabilities of the physics-informed dynamics and the adaptability characteristics of the RL controller without overfitting the policy to the template model. Our approach is validated on the MIT Humanoid, demonstrating that our policy can achieve stable yet dynamic locomotion for walking and turning. We further validate the adaptability and generalizability of our policy by extending the locomotion task to unseen, uneven terrain. During the hardware deployment, we have achieved forward walking speeds of up to 1.5 m/s on a treadmill and have successfully performed dynamic locomotion maneuvers such as 90-degree and 180-degree turns.
Read more8/6/2024
0
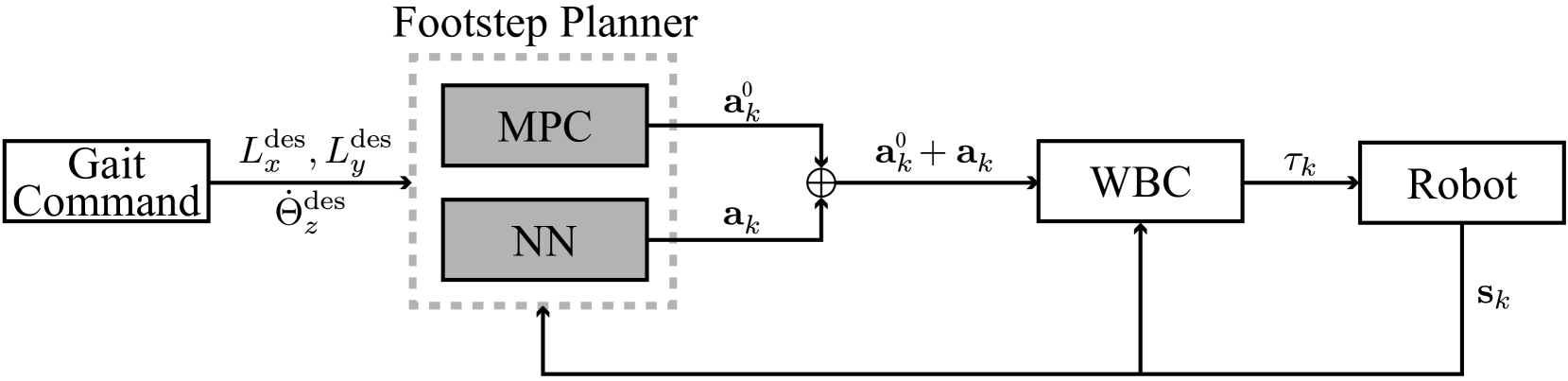
RL-augmented MPC Framework for Agile and Robust Bipedal Footstep Locomotion Planning and Control
Seung Hyeon Bang, Carlos Arribalzaga Jov'e, Luis Sentis
This paper proposes an online bipedal footstep planning strategy that combines model predictive control (MPC) and reinforcement learning (RL) to achieve agile and robust bipedal maneuvers. While MPC-based foot placement controllers have demonstrated their effectiveness in achieving dynamic locomotion, their performance is often limited by the use of simplified models and assumptions. To address this challenge, we develop a novel foot placement controller that leverages a learned policy to bridge the gap between the use of a simplified model and the more complex full-order robot system. Specifically, our approach employs a unique combination of an ALIP-based MPC foot placement controller for sub-optimal footstep planning and the learned policy for refining footstep adjustments, enabling the resulting footstep policy to capture the robot's whole-body dynamics effectively. This integration synergizes the predictive capability of MPC with the flexibility and adaptability of RL. We validate the effectiveness of our framework through a series of experiments using the full-body humanoid robot DRACO 3. The results demonstrate significant improvements in dynamic locomotion performance, including better tracking of a wide range of walking speeds, enabling reliable turning and traversing challenging terrains while preserving the robustness and stability of the walking gaits compared to the baseline ALIP-based MPC approach.
Read more7/26/2024
🏅
0
Reinforcement Learning for Versatile, Dynamic, and Robust Bipedal Locomotion Control
Zhongyu Li, Xue Bin Peng, Pieter Abbeel, Sergey Levine, Glen Berseth, Koushil Sreenath
This paper presents a comprehensive study on using deep reinforcement learning (RL) to create dynamic locomotion controllers for bipedal robots. Going beyond focusing on a single locomotion skill, we develop a general control solution that can be used for a range of dynamic bipedal skills, from periodic walking and running to aperiodic jumping and standing. Our RL-based controller incorporates a novel dual-history architecture, utilizing both a long-term and short-term input/output (I/O) history of the robot. This control architecture, when trained through the proposed end-to-end RL approach, consistently outperforms other methods across a diverse range of skills in both simulation and the real world. The study also delves into the adaptivity and robustness introduced by the proposed RL system in developing locomotion controllers. We demonstrate that the proposed architecture can adapt to both time-invariant dynamics shifts and time-variant changes, such as contact events, by effectively using the robot's I/O history. Additionally, we identify task randomization as another key source of robustness, fostering better task generalization and compliance to disturbances. The resulting control policies can be successfully deployed on Cassie, a torque-controlled human-sized bipedal robot. This work pushes the limits of agility for bipedal robots through extensive real-world experiments. We demonstrate a diverse range of locomotion skills, including: robust standing, versatile walking, fast running with a demonstration of a 400-meter dash, and a diverse set of jumping skills, such as standing long jumps and high jumps.
Read more8/27/2024
0
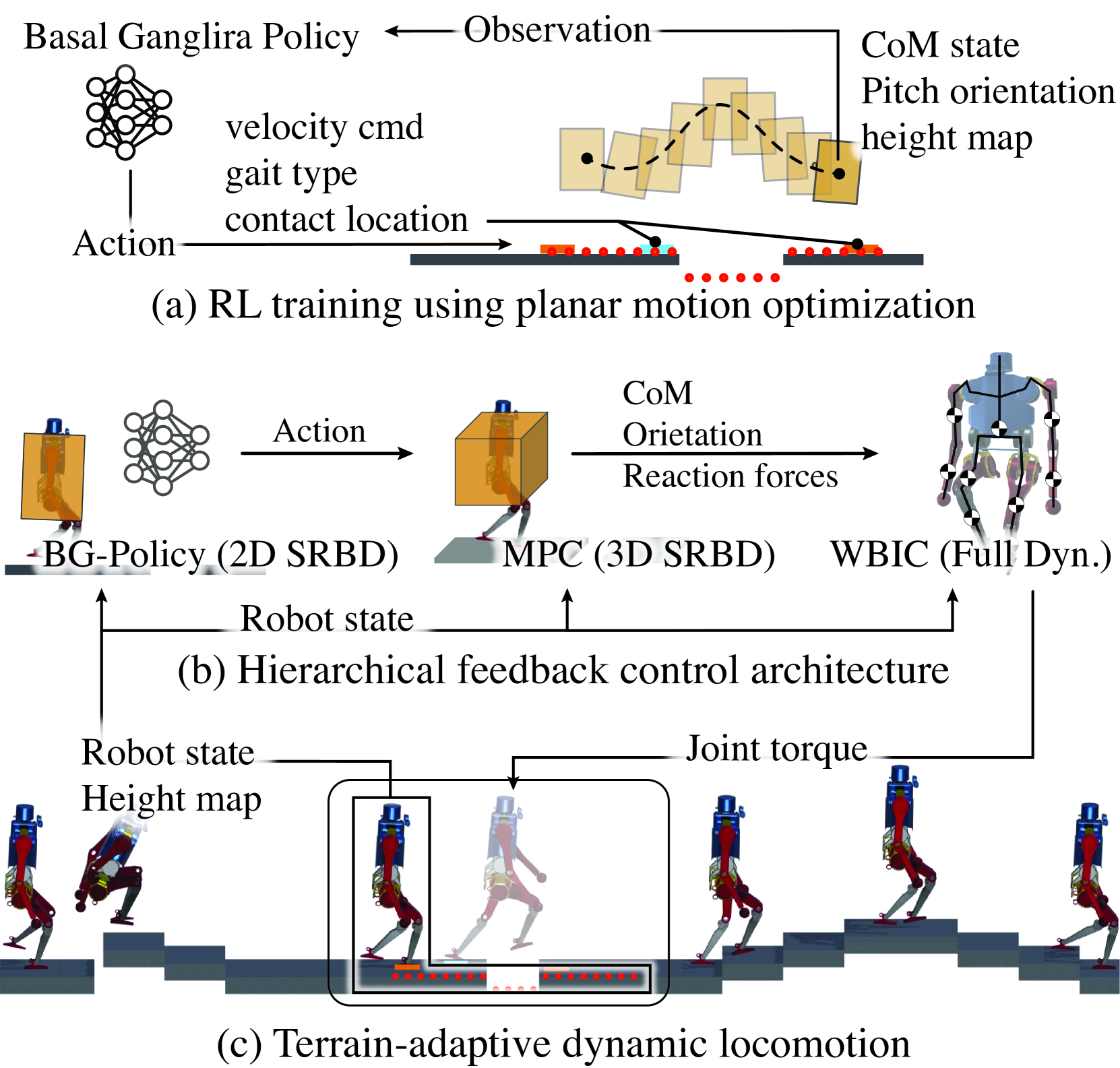
Learning Generic and Dynamic Locomotion of Humanoids Across Discrete Terrains
Shangqun Yu, Nisal Perera, Daniel Marew, Donghyun Kim
This paper addresses the challenge of terrain-adaptive dynamic locomotion in humanoid robots, a problem traditionally tackled by optimization-based methods or reinforcement learning (RL). Optimization-based methods, such as model-predictive control, excel in finding optimal reaction forces and achieving agile locomotion, especially in quadruped, but struggle with the nonlinear hybrid dynamics of legged systems and the real-time computation of step location, timing, and reaction forces. Conversely, RL-based methods show promise in navigating dynamic and rough terrains but are limited by their extensive data requirements. We introduce a novel locomotion architecture that integrates a neural network policy, trained through RL in simplified environments, with a state-of-the-art motion controller combining model-predictive control (MPC) and whole-body impulse control (WBIC). The policy efficiently learns high-level locomotion strategies, such as gait selection and step positioning, without the need for full dynamics simulations. This control architecture enables humanoid robots to dynamically navigate discrete terrains, making strategic locomotion decisions (e.g., walking, jumping, and leaping) based on ground height maps. Our results demonstrate that this integrated control architecture achieves dynamic locomotion with significantly fewer training samples than conventional RL-based methods and can be transferred to different humanoid platforms without additional training. The control architecture has been extensively tested in dynamic simulations, accomplishing terrain height-based dynamic locomotion for three different robots.
Read more7/30/2024