Integrating Present and Past in Unsupervised Continual Learning
2404.19132
0
0
🤷
Abstract
We formulate a unifying framework for unsupervised continual learning (UCL), which disentangles learning objectives that are specific to the present and the past data, encompassing stability, plasticity, and cross-task consolidation. The framework reveals that many existing UCL approaches overlook cross-task consolidation and try to balance plasticity and stability in a shared embedding space. This results in worse performance due to a lack of within-task data diversity and reduced effectiveness in learning the current task. Our method, Osiris, which explicitly optimizes all three objectives on separate embedding spaces, achieves state-of-the-art performance on all benchmarks, including two novel benchmarks proposed in this paper featuring semantically structured task sequences. Compared to standard benchmarks, these two structured benchmarks more closely resemble visual signals received by humans and animals when navigating real-world environments. Finally, we show some preliminary evidence that continual models can benefit from such realistic learning scenarios.
Create account to get full access
Overview
- The paper proposes a unifying framework for unsupervised continual learning (UCL) that addresses three key objectives: stability, plasticity, and cross-task consolidation.
- The framework reveals that many existing UCL approaches overlook cross-task consolidation and focus on balancing plasticity and stability in a shared embedding space, which can lead to reduced performance.
- The authors' method, Osiris, explicitly optimizes all three objectives on separate embedding spaces and achieves state-of-the-art performance on various benchmarks.
- The paper also introduces two novel benchmarks featuring semantically structured task sequences, which more closely resemble the visual signals received by humans and animals in real-world environments.
- The authors provide preliminary evidence that continual models can benefit from such realistic learning scenarios.
Plain English Explanation
The paper presents a new approach to unsupervised continual learning, which is the ability of an AI system to learn new tasks or skills continuously without forgetting what it has learned before. The key idea is to separate the learning objectives into three distinct parts:
- Stability: Ensuring the AI system doesn't forget what it has learned in the past.
- Plasticity: Allowing the AI system to adapt and learn new tasks or skills.
- Cross-task consolidation: Helping the AI system connect and combine the knowledge it has learned across different tasks.
Many existing approaches to continual learning focus on balancing stability and plasticity, but they often overlook the importance of cross-task consolidation. This can lead to the AI system performing worse on new tasks, as it doesn't fully leverage the knowledge it has gained from previous tasks.
The authors' method, called Osiris, addresses all three learning objectives separately, using different "embedding spaces" (essentially, different ways of representing the information in the AI system). This allows Osiris to achieve state-of-the-art performance on various continual learning benchmarks.
The paper also introduces two new benchmarks that are more realistic, as they involve task sequences that are semantically structured, similar to the visual signals that humans and animals encounter in the real world. The authors show that continual learning models can benefit from these more realistic learning scenarios, suggesting that this is an important direction for future research.
Technical Explanation
The paper formulates a unifying framework for unsupervised continual learning (UCL), which aims to disentangle the learning objectives of stability, plasticity, and cross-task consolidation. The authors argue that many existing UCL approaches, such as those that try to balance plasticity and stability in a shared embedding space, overlook the importance of cross-task consolidation, leading to reduced performance.
To address this, the authors propose a method called Osiris, which explicitly optimizes all three objectives on separate embedding spaces. By doing this, Osiris is able to achieve state-of-the-art performance on various continual learning benchmarks, including two novel benchmarks introduced in the paper.
These new benchmarks feature semantically structured task sequences, which the authors argue more closely resemble the visual signals received by humans and animals when navigating real-world environments. Compared to standard benchmarks, these structured benchmarks present a more realistic challenge for continual learning models.
The authors provide preliminary evidence that continual learning models can indeed benefit from these more realistic learning scenarios, suggesting that this could be an important direction for future research in the field of continual learning with pre-trained models.
Critical Analysis
The paper presents a compelling framework for unsupervised continual learning and an effective method, Osiris, that addresses the key objectives of stability, plasticity, and cross-task consolidation. The introduction of the novel benchmarks with semantically structured task sequences is a valuable contribution, as it highlights the importance of evaluating continual learning models in more realistic settings.
However, the paper does not provide a detailed analysis of the limitations or potential issues with the Osiris method. For example, it would be helpful to understand the computational and memory requirements of the separate embedding spaces, as well as the scalability of the approach to larger and more complex task sequences.
Additionally, the paper does not explore the potential biases or lack of diversity that may arise in the semantically structured task sequences, and how this could impact the generalization of the learned representations. Further research is needed to fully understand the implications of these realistic learning scenarios and their impact on continual learning performance.
Overall, the paper presents a valuable contribution to the field of continual learning, but there are opportunities for deeper analysis and exploration of the limitations and potential issues with the proposed framework and benchmarks.
Conclusion
This paper introduces a unifying framework for unsupervised continual learning that disentangles the key learning objectives of stability, plasticity, and cross-task consolidation. The authors' method, Osiris, which explicitly optimizes these objectives on separate embedding spaces, achieves state-of-the-art performance on various benchmarks.
Importantly, the paper also presents two novel benchmarks featuring semantically structured task sequences, which more closely resemble the visual signals encountered by humans and animals in real-world environments. The authors provide preliminary evidence that continual learning models can benefit from these more realistic learning scenarios, suggesting that this is an important direction for future research in the field.
By addressing the limitations of existing approaches and introducing more realistic evaluation scenarios, this paper advances the state of the art in unsupervised continual learning and paves the way for the development of AI systems that can learn and adapt in a more natural and effective manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Read Between the Layers: Leveraging Intra-Layer Representations for Rehearsal-Free Continual Learning with Pre-Trained Models
Kyra Ahrens, Hans Hergen Lehmann, Jae Hee Lee, Stefan Wermter
0
0
We address the Continual Learning (CL) problem, wherein a model must learn a sequence of tasks from non-stationary distributions while preserving prior knowledge upon encountering new experiences. With the advancement of foundation models, CL research has pivoted from the initial learning-from-scratch paradigm towards utilizing generic features from large-scale pre-training. However, existing approaches to CL with pre-trained models primarily focus on separating class-specific features from the final representation layer and neglect the potential of intermediate representations to capture low- and mid-level features, which are more invariant to domain shifts. In this work, we propose LayUP, a new prototype-based approach to continual learning that leverages second-order feature statistics from multiple intermediate layers of a pre-trained network. Our method is conceptually simple, does not require access to prior data, and works out of the box with any foundation model. LayUP surpasses the state of the art in four of the seven class-incremental learning benchmarks, all three domain-incremental learning benchmarks and in six of the seven online continual learning benchmarks, while significantly reducing memory and computational requirements compared to existing baselines. Our results demonstrate that fully exhausting the representational capacities of pre-trained models in CL goes well beyond their final embeddings.
4/19/2024
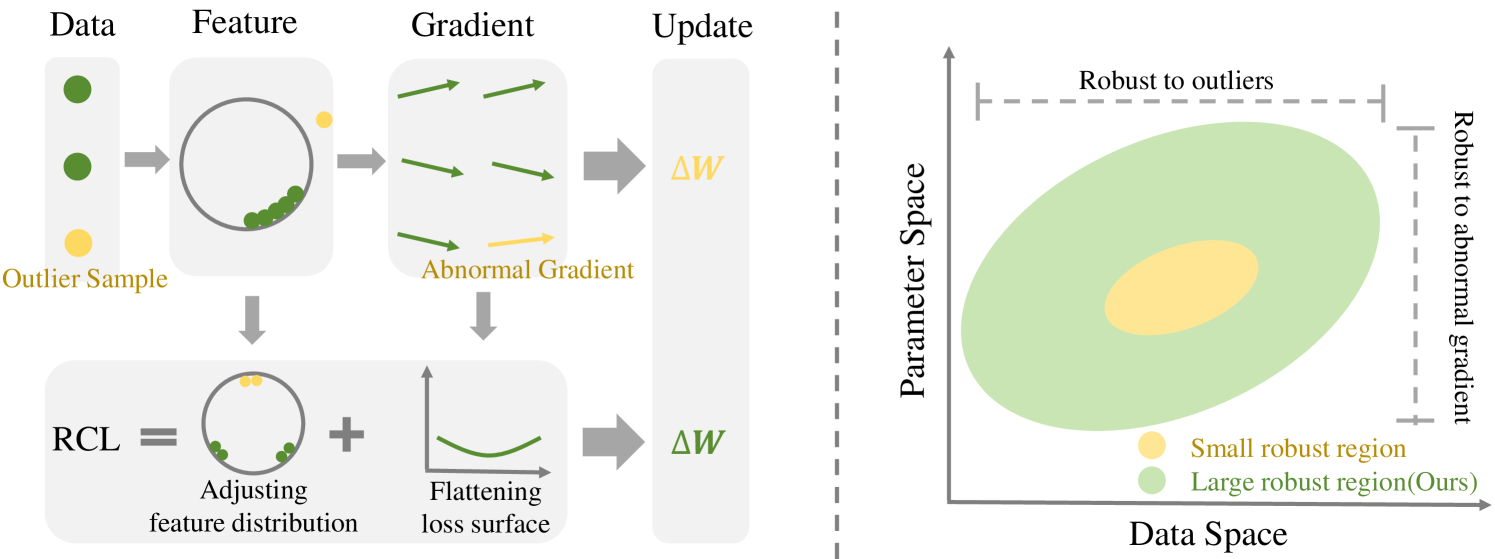
Improving Data-aware and Parameter-aware Robustness for Continual Learning
Hanxi Xiao, Fan Lyu
0
0
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
5/28/2024

Controlling Forgetting with Test-Time Data in Continual Learning
Vaibhav Singh, Rahaf Aljundi, Eugene Belilovsky
0
0
Foundational vision-language models have shown impressive performance on various downstream tasks. Yet, there is still a pressing need to update these models later as new tasks or domains become available. Ongoing Continual Learning (CL) research provides techniques to overcome catastrophic forgetting of previous information when new knowledge is acquired. To date, CL techniques focus only on the supervised training sessions. This results in significant forgetting yielding inferior performance to even the prior model zero shot performance. In this work, we argue that test-time data hold great information that can be leveraged in a self supervised manner to refresh the model's memory of previous learned tasks and hence greatly reduce forgetting at no extra labelling cost. We study how unsupervised data can be employed online to improve models' performance on prior tasks upon encountering representative samples. We propose a simple yet effective student-teacher model with gradient based sparse parameters updates and show significant performance improvements and reduction in forgetting, which could alleviate the role of an offline episodic memory/experience replay buffer.
6/21/2024
On the Convergence of Continual Learning with Adaptive Methods
Seungyub Han, Yeongmo Kim, Taehyun Cho, Jungwoo Lee
0
0
One of the objectives of continual learning is to prevent catastrophic forgetting in learning multiple tasks sequentially, and the existing solutions have been driven by the conceptualization of the plasticity-stability dilemma. However, the convergence of continual learning for each sequential task is less studied so far. In this paper, we provide a convergence analysis of memory-based continual learning with stochastic gradient descent and empirical evidence that training current tasks causes the cumulative degradation of previous tasks. We propose an adaptive method for nonconvex continual learning (NCCL), which adjusts step sizes of both previous and current tasks with the gradients. The proposed method can achieve the same convergence rate as the SGD method when the catastrophic forgetting term which we define in the paper is suppressed at each iteration. Further, we demonstrate that the proposed algorithm improves the performance of continual learning over existing methods for several image classification tasks.
4/16/2024