Integrating Reinforcement Learning and Model Predictive Control with Applications to Microgrids

0

Sign in to get full access
Overview
- Integrates reinforcement learning and model predictive control for applications in microgrids
- Develops a novel control framework that combines the strengths of both approaches
- Demonstrates the effectiveness of the proposed method through simulations on a microgrid case study
Plain English Explanation
The paper presents an approach that combines reinforcement learning and model predictive control to control the operation of a microgrid. Microgrids are small-scale power grids that can operate independently from the main grid and are becoming increasingly important for renewable energy integration and grid resilience.
The main idea is to leverage the advantages of both reinforcement learning and model predictive control. Reinforcement learning is a machine learning technique that allows an agent to learn optimal actions by interacting with an environment and receiving rewards. Model predictive control, on the other hand, is an optimization-based control method that can handle complex system dynamics and constraints.
By combining these two approaches, the researchers develop a control framework that can adaptively learn and optimize the microgrid's operation in response to changing conditions, while still considering the system's physical constraints and objectives. This allows for more reliable, efficient, and economical microgrid management.
Technical Explanation
The proposed control framework consists of two main components: a reinforcement learning agent and a model predictive controller. The reinforcement learning agent is responsible for learning the optimal actions to take in the microgrid environment, while the model predictive controller uses a mathematical model of the microgrid to optimize the control actions over a future time horizon.
The reinforcement learning agent uses a deep neural network to approximate the optimal control policy. The agent interacts with a simulation of the microgrid and receives rewards based on the system's performance, such as minimizing energy costs, maintaining power balance, and ensuring reliable operation.
The model predictive controller, on the other hand, solves an optimization problem at each time step to determine the optimal control actions for the microgrid, considering factors like energy prices, renewable generation, and load demand. The controller uses a linearized model of the microgrid to predict the system's future behavior and optimize the control actions accordingly.
By integrating the reinforcement learning agent and the model predictive controller, the researchers create a hybrid control framework that can adaptively learn and optimize the microgrid's operation while respecting its physical constraints and operational objectives.
Critical Analysis
The paper presents a promising approach for integrating reinforcement learning and model predictive control for microgrid applications. The key strengths of the proposed method include its ability to adapt to changing conditions, handle complex system dynamics and constraints, and optimize the microgrid's performance.
One potential limitation of the research is the use of a simulated microgrid environment for the experiments. While the simulation is based on realistic models, it may not fully capture the complexity and uncertainties of real-world microgrid systems. Further validation on actual microgrid testbeds or field deployments would be valuable to assess the method's practical applicability and robustness.
Additionally, the paper does not provide a detailed analysis of the computational complexity and scalability of the proposed control framework. As microgrids can potentially involve a large number of distributed energy resources and control variables, the scalability of the approach to larger-scale systems should be investigated.
Conclusion
The paper presents an innovative approach that combines reinforcement learning and model predictive control for optimizing the operation of microgrids. By leveraging the strengths of both techniques, the proposed control framework can adaptively learn and optimize microgrid performance while considering physical constraints and operational objectives.
The research has important implications for the integration of renewable energy sources and the development of more resilient and efficient power grids. The integration of reinforcement learning and model predictive control could pave the way for smarter, more adaptive, and more responsive energy management systems that can better accommodate the increasing complexity of modern power systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Integrating Reinforcement Learning and Model Predictive Control with Applications to Microgrids
Caio Fabio Oliveira da Silva, Azita Dabiri, Bart De Schutter
This work proposes an approach that integrates reinforcement learning and model predictive control (MPC) to efficiently solve finite-horizon optimal control problems in mixed-logical dynamical systems. Optimization-based control of such systems with discrete and continuous decision variables entails the online solution of mixed-integer quadratic or linear programs, which suffer from the curse of dimensionality. Our approach aims at mitigating this issue by effectively decoupling the decision on the discrete variables and the decision on the continuous variables. Moreover, to mitigate the combinatorial growth in the number of possible actions due to the prediction horizon, we conceive the definition of decoupled Q-functions to make the learning problem more tractable. The use of reinforcement learning reduces the online optimization problem of the MPC controller from a mixed-integer linear (quadratic) program to a linear (quadratic) program, greatly reducing the computational time. Simulation experiments for a microgrid, based on real-world data, demonstrate that the proposed method significantly reduces the online computation time of the MPC approach and that it generates policies with small optimality gaps and high feasibility rates.
Read more9/18/2024
🏅
0
MPC-Inspired Reinforcement Learning for Verifiable Model-Free Control
Yiwen Lu, Zishuo Li, Yihan Zhou, Na Li, Yilin Mo
In this paper, we introduce a new class of parameterized controllers, drawing inspiration from Model Predictive Control (MPC). The controller resembles a Quadratic Programming (QP) solver of a linear MPC problem, with the parameters of the controller being trained via Deep Reinforcement Learning (DRL) rather than derived from system models. This approach addresses the limitations of common controllers with Multi-Layer Perceptron (MLP) or other general neural network architecture used in DRL, in terms of verifiability and performance guarantees, and the learned controllers possess verifiable properties like persistent feasibility and asymptotic stability akin to MPC. On the other hand, numerical examples illustrate that the proposed controller empirically matches MPC and MLP controllers in terms of control performance and has superior robustness against modeling uncertainty and noises. Furthermore, the proposed controller is significantly more computationally efficient compared to MPC and requires fewer parameters to learn than MLP controllers. Real-world experiments on vehicle drift maneuvering task demonstrate the potential of these controllers for robotics and other demanding control tasks.
Read more4/10/2024
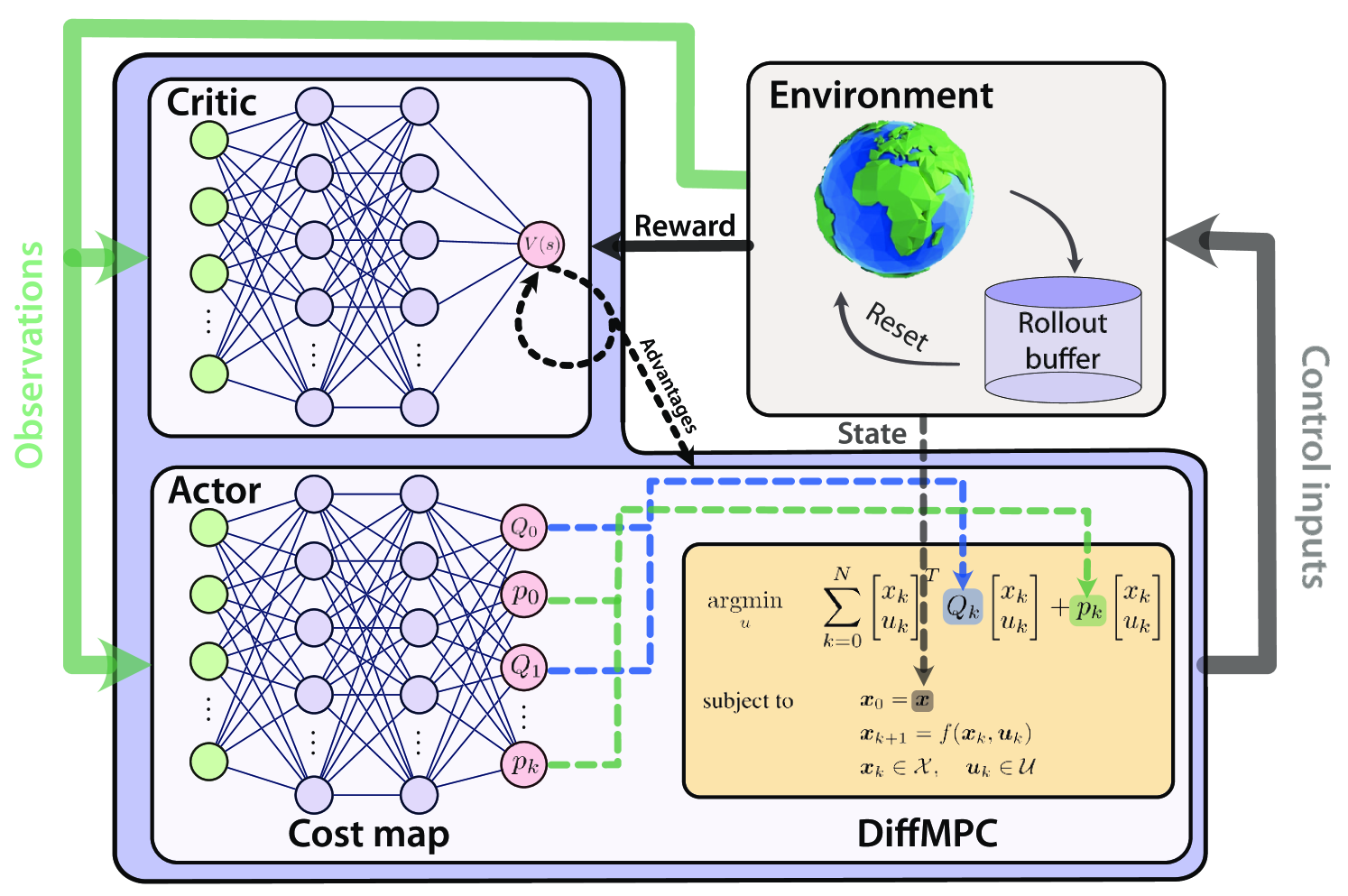
0
Actor-Critic Model Predictive Control
Angel Romero, Yunlong Song, Davide Scaramuzza
An open research question in robotics is how to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC). This paper provides an answer by introducing a new framework called Actor-Critic Model Predictive Control. The key idea is to embed a differentiable MPC within an actor-critic RL framework. The proposed approach leverages the short-term predictive optimization capabilities of MPC with the exploratory and end-to-end training properties of RL. The resulting policy effectively manages both short-term decisions through the MPC-based actor and long-term prediction via the critic network, unifying the benefits of both model-based control and end-to-end learning. We validate our method in both simulation and the real world with a quadcopter platform across various high-level tasks. We show that the proposed architecture can achieve real-time control performance, learn complex behaviors via trial and error, and retain the predictive properties of the MPC to better handle out of distribution behaviour.
Read more4/15/2024
🏅
0
Mixed-Integer Optimal Control via Reinforcement Learning: A Case Study on Hybrid Electric Vehicle Energy Management
Jinming Xu, Nasser Lashgarian Azad, Yuan Lin
Many optimal control problems require the simultaneous output of discrete and continuous control variables. These problems are usually formulated as mixed-integer optimal control (MIOC) problems, which are challenging to solve due to the complexity of the solution space. Numerical methods such as branch-and-bound are computationally expensive and undesirable for real-time control. This paper proposes a novel hybrid-action reinforcement learning (HARL) algorithm, twin delayed deep deterministic actor-Q (TD3AQ), for MIOC problems. TD3AQ combines the advantages of both actor-critic and Q-learning methods, and can handle the discrete and continuous action spaces simultaneously. The proposed algorithm is evaluated on a plug-in hybrid electric vehicle (PHEV) energy management problem, where real-time control of the discrete variables, clutch engagement/disengagement and gear shift, and continuous variable, engine torque, is essential to maximize fuel economy while satisfying driving constraints. Simulation outcomes demonstrate that TD3AQ achieves control results close to optimality when compared with dynamic programming (DP), with just 4.69% difference. Furthermore, it surpasses the performance of baseline reinforcement learning algorithms.
Read more6/3/2024