Intelligent Multi-View Test Time Augmentation

0

Sign in to get full access
Overview
- This paper introduces an "Intelligent Multi-View Test Time Augmentation" approach to improve model performance during inference.
- The key ideas are to generate multiple views of the input data at test time and combine the model's predictions across these views to obtain a more robust and accurate final output.
- The authors demonstrate the effectiveness of their method on several benchmark datasets, showing improvements over standard test-time augmentation techniques.
Plain English Explanation
The paper presents a new way to improve the performance of AI models during the testing or inference stage. The core idea is to create multiple "views" or versions of the input data, run the model on each of these views, and then combine the results to get a more accurate final prediction.
This is different from the typical approach of just using a single input during testing. By generating and leveraging multiple views of the data, the model can become more robust to variations and noise that may be present in real-world inputs. [This relates to the principles discussed in the paper on data augmentation for multivariate time series classification.]
The authors show that this "intelligent multi-view test time augmentation" method outperforms standard test-time augmentation techniques on several benchmark datasets. This suggests it could be a useful technique for improving the real-world performance of AI models in a wide range of applications.
Technical Explanation
The key technical elements of the paper are:
-
Test Time Augmentation (TTA): The standard approach of generating transformed versions of the input data during model testing to improve robustness.
-
Intelligent Multi-View TTA: The proposed method, which goes beyond basic TTA by intelligently generating multiple distinct "views" of the input and combining the model's predictions across these views.
-
Multi-View Generator: A neural network component that takes the original input and generates a set of transformed views, designed to capture diverse and complementary information.
-
View Aggregation: The mechanism for combining the model's predictions across the multiple views, such as using an ensemble approach or learnable fusion module.
The authors conduct experiments on several image classification benchmarks, demonstrating consistent improvements in accuracy compared to standard TTA and other baselines. The benefits are particularly pronounced in the case of corrupted or adversarial inputs, showcasing the enhanced robustness provided by the intelligent multi-view approach.
Critical Analysis
The paper presents a compelling and well-executed idea for improving model performance at test time. Some potential areas for further exploration or discussion include:
-
Computational Overhead: While the multi-view generation and aggregation add some computational cost, the authors could further investigate the trade-offs between inference time and accuracy gains. [This relates to the discussions around computational time limitations in test-time adaptation.]
-
Generalization to Other Domains: The experiments focus on image classification tasks, so it would be valuable to explore the applicability of the proposed method to other domains, such as natural language processing or multivariate time series analysis.
-
Interpretability of the Multi-View Generator: The paper does not provide much insight into how the multi-view generator network learns to produce diverse and complementary views. Further analysis of this component could yield interesting insights.
-
Potential for Zero-Shot Generalization: The multi-view approach could be explored in the context of zero-shot or few-shot learning scenarios, where the model needs to adapt to novel classes or domains at test time.
Overall, the paper presents a compelling and practical technique that could have significant real-world impact, especially in applications that require clinician-preferred segmentation or other safety-critical domains.
Conclusion
This paper introduces an "Intelligent Multi-View Test Time Augmentation" approach that generates multiple transformed views of the input data during model inference and combines the model's predictions across these views to obtain more robust and accurate results.
The key innovation is the multi-view generator network that learns to produce diverse and complementary views of the input, going beyond standard test-time augmentation techniques. The authors demonstrate the effectiveness of their method on several image classification benchmarks, showing consistent improvements over baseline approaches.
While the paper focuses on image tasks, the core principles could potentially be applied to a wide range of domains, including natural language processing, time series analysis, and safety-critical applications. Further exploration of the computational trade-offs, interpretability of the multi-view generator, and the potential for zero-shot generalization could yield valuable insights and extensions of this work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Intelligent Multi-View Test Time Augmentation
Efe Ozturk, Mohit Prabhushankar, Ghassan AlRegib
In this study, we introduce an intelligent Test Time Augmentation (TTA) algorithm designed to enhance the robustness and accuracy of image classification models against viewpoint variations. Unlike traditional TTA methods that indiscriminately apply augmentations, our approach intelligently selects optimal augmentations based on predictive uncertainty metrics. This selection is achieved via a two-stage process: the first stage identifies the optimal augmentation for each class by evaluating uncertainty levels, while the second stage implements an uncertainty threshold to determine when applying TTA would be advantageous. This methodological advancement ensures that augmentations contribute to classification more effectively than a uniform application across the dataset. Experimental validation across several datasets and neural network architectures validates our approach, yielding an average accuracy improvement of 1.73% over methods that use single-view images. This research underscores the potential of adaptive, uncertainty-aware TTA in improving the robustness of image classification in the presence of viewpoint variations, paving the way for further exploration into intelligent augmentation strategies.
Read more6/14/2024

0
Test-Time Augmentation Meets Variational Bayes
Masanari Kimura, Howard Bondell
Data augmentation is known to contribute significantly to the robustness of machine learning models. In most instances, data augmentation is utilized during the training phase. Test-Time Augmentation (TTA) is a technique that instead leverages these data augmentations during the testing phase to achieve robust predictions. More precisely, TTA averages the predictions of multiple data augmentations of an instance to produce a final prediction. Although the effectiveness of TTA has been empirically reported, it can be expected that the predictive performance achieved will depend on the set of data augmentation methods used during testing. In particular, the data augmentation methods applied should make different contributions to performance. That is, it is anticipated that there may be differing degrees of contribution in the set of data augmentation methods used for TTA, and these could have a negative impact on prediction performance. In this study, we consider a weighted version of the TTA based on the contribution of each data augmentation. Some variants of TTA can be regarded as considering the problem of determining the appropriate weighting. We demonstrate that the determination of the coefficients of this weighted TTA can be formalized in a variational Bayesian framework. We also show that optimizing the weights to maximize the marginal log-likelihood suppresses candidates of unwanted data augmentations at the test phase.
Read more9/20/2024
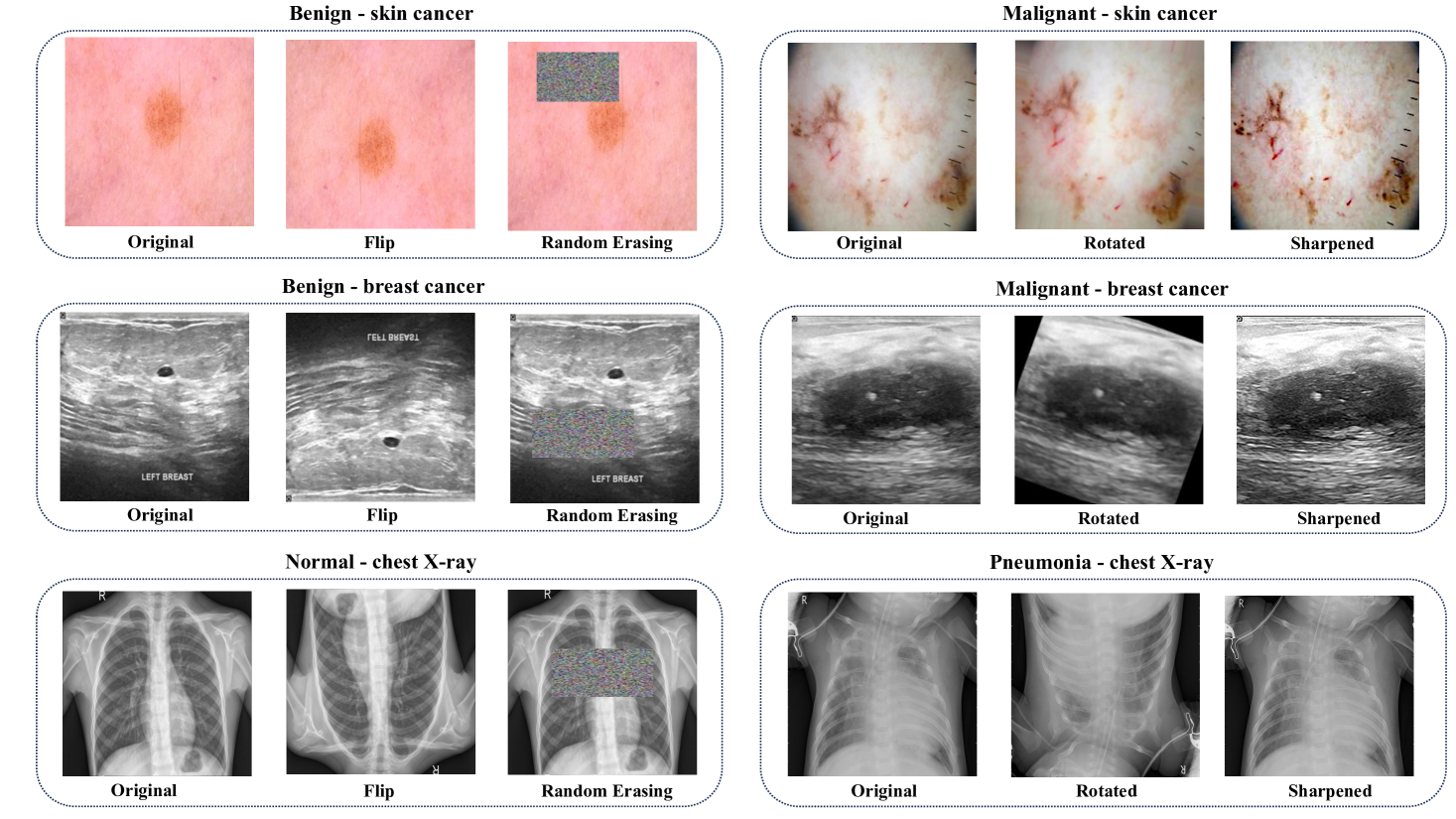
0
BayTTA: Uncertainty-aware medical image classification with optimized test-time augmentation using Bayesian model averaging
Zeinab Sherkatghanad, Moloud Abdar, Mohammadreza Bakhtyari, Pawel Plawiak, Vladimir Makarenkov
Test-time augmentation (TTA) is a well-known technique employed during the testing phase of computer vision tasks. It involves aggregating multiple augmented versions of input data. Combining predictions using a simple average formulation is a common and straightforward approach after performing TTA. This paper introduces a novel framework for optimizing TTA, called BayTTA (Bayesian-based TTA), which is based on Bayesian Model Averaging (BMA). First, we generate a prediction list associated with different variations of the input data created through TTA. Then, we use BMA to combine predictions weighted by the respective posterior probabilities. Such an approach allows one to take into account model uncertainty, and thus to enhance the predictive performance of the related machine learning or deep learning model. We evaluate the performance of BayTTA on various public data, including three medical image datasets comprising skin cancer, breast cancer, and chest X-ray images and two well-known gene editing datasets, CRISPOR and GUIDE-seq. Our experimental results indicate that BayTTA can be effectively integrated into state-of-the-art deep learning models used in medical image analysis as well as into some popular pre-trained CNN models such as VGG-16, MobileNetV2, DenseNet201, ResNet152V2, and InceptionRes-NetV2, leading to the enhancement in their accuracy and robustness performance. The source code of the proposed BayTTA method is freely available at: underline {https://github.com/Z-Sherkat/BayTTA}.
Read more8/28/2024

0
Single Image Test-Time Adaptation for Segmentation
Klara Janouskova, Tamir Shor, Chaim Baskin, Jiri Matas
Test-Time Adaptation (TTA) methods improve the robustness of deep neural networks to domain shift on a variety of tasks such as image classification or segmentation. This work explores adapting segmentation models to a single unlabelled image with no other data available at test-time. In particular, this work focuses on adaptation by optimizing self-supervised losses at test-time. Multiple baselines based on different principles are evaluated under diverse conditions and a novel adversarial training is introduced for adaptation with mask refinement. Our additions to the baselines result in a 3.51 and 3.28 % increase over non-adapted baselines, without these improvements, the increase would be 1.7 and 2.16 % only.
Read more7/4/2024