InterAct: Capture and Modelling of Realistic, Expressive and Interactive Activities between Two Persons in Daily Scenarios

0

Sign in to get full access
Overview
- Presents a novel approach called "InterAct" for capturing and modeling realistic, expressive, and interactive activities between two people in daily scenarios
- Leverages motion capture technology and deep learning to create interactive digital human models that can engage in natural conversations and perform everyday tasks
- Aims to improve the realism and interactivity of virtual characters in applications like games, films, and social robotics
Plain English Explanation
"InterAct" is a new system that allows virtual characters to interact with each other in a more natural and lifelike way. Using motion capture technology, the researchers were able to record the movements and expressions of people as they engaged in everyday conversations and activities. They then used deep learning models to analyze this data and create digital human characters that can mimic these behaviors.
The key innovation of InterAct is its ability to capture the subtle, nuanced interactions that happen between people. Instead of just animating characters to move in predetermined ways, InterAct can generate natural-looking movements and facial expressions that respond dynamically to the actions of the other character. This allows the virtual characters to have more engaging and believable conversations and interactions.
This technology could be very useful for applications like video games, movies, and social robotics, where having realistic and interactive digital humans is important for creating immersive experiences. By modeling the complex dynamics of human-to-human interaction, InterAct aims to make virtual characters feel more lifelike and relatable.
Technical Explanation
The InterAct system consists of several key components:
-
Motion Capture: The researchers used a multi-camera motion capture system to record the movements and facial expressions of people as they engaged in various interactive scenarios, such as conversations, handshakes, and collaborative tasks.
-
Interaction Modeling: They developed deep learning models to analyze the motion capture data and extract patterns of interaction between the two people. This allowed them to capture the subtle, contextual cues and dynamics that govern natural human-to-human interactions.
-
Interactive Animation: Using the learned interaction models, the researchers were able to generate realistic animations of virtual characters that could engage in interactive behaviors. The characters' movements and expressions would dynamically respond to the actions of the other character, creating a more lifelike and engaging interaction.
-
Evaluation: The researchers conducted user studies to evaluate the realism and interactivity of the digital characters generated by InterAct. They compared the system's performance to existing approaches and found that it was able to generate more believable and engaging interactive behaviors.
The key technical innovation of InterAct lies in its ability to model the complex, contextual dynamics of human-to-human interaction. By capturing the nuanced movements, expressions, and responses that occur during real-world interactions, the system can create virtual characters that feel more natural and responsive than those produced by traditional animation techniques.
Critical Analysis
One potential limitation of the InterAct system is the amount of motion capture data required to train the models. Capturing high-quality, diverse interaction scenarios can be a time-consuming and resource-intensive process. The researchers acknowledge that expanding the dataset and improving the generalization capabilities of the models would be an important area for future work.
Additionally, while InterAct demonstrates impressive results in generating interactive behaviors, the system is still constrained by the limitations of current animation technology. The virtual characters may not be able to fully capture the subtleties and complexities of human interaction, particularly in more ambiguous or emotionally charged scenarios.
Further research could also explore the potential applications of InterAct beyond entertainment, such as in social robotics or therapeutic interventions. Expanding the system's capabilities to handle more diverse interactions and social contexts could unlock new possibilities for how we design and interact with virtual characters.
Conclusion
The InterAct system represents a significant step forward in the field of digital human modeling and animation. By leveraging motion capture and deep learning, the researchers have created a system that can generate more realistic and interactive virtual characters, with potential applications in gaming, filmmaking, and social robotics.
The system's ability to capture the nuanced dynamics of human-to-human interaction sets it apart from traditional animation techniques and opens up new avenues for creating more engaging and immersive virtual experiences. As the field of AI and computer graphics continues to evolve, tools like InterAct will likely play an increasingly important role in shaping the way we interact with and experience digital environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
InterAct: Capture and Modelling of Realistic, Expressive and Interactive Activities between Two Persons in Daily Scenarios
Yinghao Huang, Leo Ho, Dafei Qin, Mingyi Shi, Taku Komura
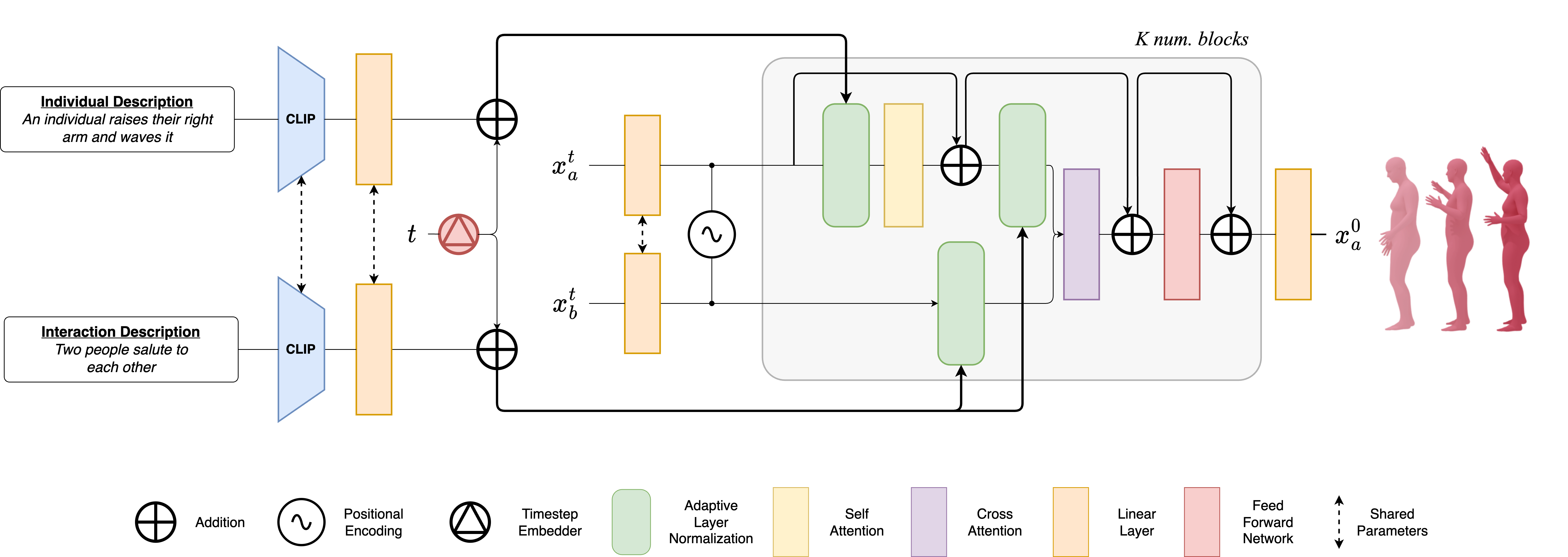
We address the problem of accurate capture and expressive modelling of interactive behaviors happening between two persons in daily scenarios. Different from previous works which either only consider one person or focus on conversational gestures, we propose to simultaneously model the activities of two persons, and target objective-driven, dynamic, and coherent interactions which often span long duration. To this end, we capture a new dataset dubbed InterAct, which is composed of 241 motion sequences where two persons perform a realistic scenario over the whole sequence. The audios, body motions, and facial expressions of both persons are all captured in our dataset. We also demonstrate the first diffusion model based approach that directly estimates the interactive motions between two persons from their audios alone. All the data and code will be available at: https://hku-cg.github.io/interact.
Read more5/28/2024
0
in2IN: Leveraging individual Information to Generate Human INteractions
Pablo Ruiz Ponce, German Barquero, Cristina Palmero, Sergio Escalera, Jose Garcia-Rodriguez
Generating human-human motion interactions conditioned on textual descriptions is a very useful application in many areas such as robotics, gaming, animation, and the metaverse. Alongside this utility also comes a great difficulty in modeling the highly dimensional inter-personal dynamics. In addition, properly capturing the intra-personal diversity of interactions has a lot of challenges. Current methods generate interactions with limited diversity of intra-person dynamics due to the limitations of the available datasets and conditioning strategies. For this, we introduce in2IN, a novel diffusion model for human-human motion generation which is conditioned not only on the textual description of the overall interaction but also on the individual descriptions of the actions performed by each person involved in the interaction. To train this model, we use a large language model to extend the InterHuman dataset with individual descriptions. As a result, in2IN achieves state-of-the-art performance in the InterHuman dataset. Furthermore, in order to increase the intra-personal diversity on the existing interaction datasets, we propose DualMDM, a model composition technique that combines the motions generated with in2IN and the motions generated by a single-person motion prior pre-trained on HumanML3D. As a result, DualMDM generates motions with higher individual diversity and improves control over the intra-person dynamics while maintaining inter-personal coherence.
Read more4/16/2024

0
Dyadic Interaction Modeling for Social Behavior Generation
Minh Tran, Di Chang, Maksim Siniukov, Mohammad Soleymani
Human-human communication is like a delicate dance where listeners and speakers concurrently interact to maintain conversational dynamics. Hence, an effective model for generating listener nonverbal behaviors requires understanding the dyadic context and interaction. In this paper, we present an effective framework for creating 3D facial motions in dyadic interactions. Existing work consider a listener as a reactive agent with reflexive behaviors to the speaker's voice and facial motions. The heart of our framework is Dyadic Interaction Modeling (DIM), a pre-training approach that jointly models speakers' and listeners' motions through masking and contrastive learning to learn representations that capture the dyadic context. To enable the generation of non-deterministic behaviors, we encode both listener and speaker motions into discrete latent representations, through VQ-VAE. The pre-trained model is further fine-tuned for motion generation. Extensive experiments demonstrate the superiority of our framework in generating listener motions, establishing a new state-of-the-art according to the quantitative measures capturing the diversity and realism of generated motions. Qualitative results demonstrate the superior capabilities of the proposed approach in generating diverse and realistic expressions, eye blinks and head gestures. The code is available at https://github.com/Boese0601/Dyadic-Interaction-Modeling
Read more7/19/2024

0
HOI-M3:Capture Multiple Humans and Objects Interaction within Contextual Environment
Juze Zhang, Jingyan Zhang, Zining Song, Zhanhe Shi, Chengfeng Zhao, Ye Shi, Jingyi Yu, Lan Xu, Jingya Wang
Humans naturally interact with both others and the surrounding multiple objects, engaging in various social activities. However, recent advances in modeling human-object interactions mostly focus on perceiving isolated individuals and objects, due to fundamental data scarcity. In this paper, we introduce HOI-M3, a novel large-scale dataset for modeling the interactions of Multiple huMans and Multiple objects. Notably, it provides accurate 3D tracking for both humans and objects from dense RGB and object-mounted IMU inputs, covering 199 sequences and 181M frames of diverse humans and objects under rich activities. With the unique HOI-M3 dataset, we introduce two novel data-driven tasks with companion strong baselines: monocular capture and unstructured generation of multiple human-object interactions. Extensive experiments demonstrate that our dataset is challenging and worthy of further research about multiple human-object interactions and behavior analysis. Our HOI-M3 dataset, corresponding codes, and pre-trained models will be disseminated to the community for future research.
Read more4/3/2024