Two-stream Multi-level Dynamic Point Transformer for Two-person Interaction Recognition

0
👁️
Sign in to get full access
Overview
- This paper proposes a new approach for recognizing interactions between two people using point cloud data.
- The key innovations include a frame selection method called Interval Frame Sampling (IFS) and a two-stream multi-level feature aggregation module.
- Extensive experiments on benchmark datasets show the proposed method outperforms state-of-the-art approaches.
Plain English Explanation
Understanding interactions between people is an important task in many smart applications, such as security monitoring and activity recognition. However, recognizing two-person interactions is more challenging than single-person actions due to increased body occlusion and overlap.
The researchers introduce a point cloud-based network called "Two-stream Multi-level Dynamic Point Transformer" to address this challenge. The key idea is to capture local-region spatial information, appearance information, and motion information related to the interaction. To do this efficiently, they propose a frame selection method called Interval Frame Sampling (IFS) to sample a smaller number of frames from the video while still capturing the most relevant information.
The network then uses a two-stream approach to extract global and partial features from the sampled frames. This allows it to effectively represent the different types of information about the interaction. Finally, a transformer is used to perform self-attention on the learned features for the final classification.
The researchers show that their approach outperforms state-of-the-art methods on two large-scale datasets, demonstrating the effectiveness of their innovations for two-person interaction recognition.
Technical Explanation
The paper proposes a point cloud-based network called "Two-stream Multi-level Dynamic Point Transformer" for two-person interaction recognition. The key innovations include:
-
Interval Frame Sampling (IFS): This frame selection method efficiently samples frames from videos, capturing more discriminative information in a relatively short processing time compared to using all frames.
-
Two-stream Multi-level Feature Aggregation: The network uses a frame features learning module and a two-stream multi-level feature aggregation module to extract global and partial features from the sampled frames. This effectively represents the local-region spatial information, appearance information, and motion information related to the interactions.
-
Transformer-based Classification: The learned features are then fed into a transformer to perform self-attention for the final classification.
Extensive experiments are conducted on the interaction subsets of the NTU RGB+D 60 and NTU RGB+D 120 datasets. The results show that the proposed network outperforms state-of-the-art approaches in most standard evaluation settings.
Critical Analysis
The paper presents a novel and effective approach for recognizing two-person interactions using point cloud data. The key innovations, such as the Interval Frame Sampling (IFS) and the two-stream multi-level feature aggregation, address the challenges of increased body occlusion and overlap in two-person interactions.
However, the paper does not discuss the potential limitations of the proposed method. For example, the performance of the network may degrade in scenarios with more than two people or with significant occlusions. Additionally, the paper does not explore the robustness of the method to variations in camera viewpoints or environmental conditions.
Furthermore, while the experiments are conducted on large-scale datasets, it would be valuable to see the network's performance on real-world, in-the-wild datasets that better reflect the diversity of two-person interactions in practical applications.
Overall, the research presented in this paper represents a significant contribution to the field of human action recognition and has the potential to enable more robust and reliable smart applications that rely on understanding two-person interactions.
Conclusion
This paper introduces a novel point cloud-based network for recognizing two-person interactions. The key innovations, including the Interval Frame Sampling (IFS) method and the two-stream multi-level feature aggregation module, effectively capture the local-region spatial information, appearance information, and motion information related to the interactions.
The extensive experiments demonstrate the proposed network's superior performance compared to state-of-the-art approaches on large-scale datasets. This research represents an important step forward in the field of human action recognition and has the potential to enable more advanced and privacy-preserving smart applications that rely on understanding interpersonal interactions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
Two-stream Multi-level Dynamic Point Transformer for Two-person Interaction Recognition
Yao Liu, Gangfeng Cui, Jiahui Luo, Xiaojun Chang, Lina Yao
As a fundamental aspect of human life, two-person interactions contain meaningful information about people's activities, relationships, and social settings. Human action recognition serves as the foundation for many smart applications, with a strong focus on personal privacy. However, recognizing two-person interactions poses more challenges due to increased body occlusion and overlap compared to single-person actions. In this paper, we propose a point cloud-based network named Two-stream Multi-level Dynamic Point Transformer for two-person interaction recognition. Our model addresses the challenge of recognizing two-person interactions by incorporating local-region spatial information, appearance information, and motion information. To achieve this, we introduce a designed frame selection method named Interval Frame Sampling (IFS), which efficiently samples frames from videos, capturing more discriminative information in a relatively short processing time. Subsequently, a frame features learning module and a two-stream multi-level feature aggregation module extract global and partial features from the sampled frames, effectively representing the local-region spatial information, appearance information, and motion information related to the interactions. Finally, we apply a transformer to perform self-attention on the learned features for the final classification. Extensive experiments are conducted on two large-scale datasets, the interaction subsets of NTU RGB+D 60 and NTU RGB+D 120. The results show that our network outperforms state-of-the-art approaches in most standard evaluation settings.
Read more5/15/2024

0
FastForensics: Efficient Two-Stream Design for Real-Time Image Manipulation Detection
Yangxiang Zhang, Yuezun Li, Ao Luo, Jiaran Zhou, Junyu Dong
With the rise in popularity of portable devices, the spread of falsified media on social platforms has become rampant. This necessitates the timely identification of authentic content. However, most advanced detection methods are computationally heavy, hindering their real-time application. In this paper, we describe an efficient two-stream architecture for real-time image manipulation detection. Our method consists of two-stream branches targeting the cognitive and inspective perspectives. In the cognitive branch, we propose efficient wavelet-guided Transformer blocks to capture the global manipulation traces related to frequency. This block contains an interactive wavelet-guided self-attention module that integrates wavelet transformation with efficient attention design, interacting with the knowledge from the inspective branch. The inspective branch consists of simple convolutions that capture fine-grained traces and interact bidirectionally with Transformer blocks to provide mutual support. Our method is lightweight ($sim$ 8M) but achieves competitive performance compared to many other counterparts, demonstrating its efficacy in image manipulation detection and its potential for portable integration.
Read more8/30/2024

0
InterAct: Capture and Modelling of Realistic, Expressive and Interactive Activities between Two Persons in Daily Scenarios
Yinghao Huang, Leo Ho, Dafei Qin, Mingyi Shi, Taku Komura
We address the problem of accurate capture and expressive modelling of interactive behaviors happening between two persons in daily scenarios. Different from previous works which either only consider one person or focus on conversational gestures, we propose to simultaneously model the activities of two persons, and target objective-driven, dynamic, and coherent interactions which often span long duration. To this end, we capture a new dataset dubbed InterAct, which is composed of 241 motion sequences where two persons perform a realistic scenario over the whole sequence. The audios, body motions, and facial expressions of both persons are all captured in our dataset. We also demonstrate the first diffusion model based approach that directly estimates the interactive motions between two persons from their audios alone. All the data and code will be available at: https://hku-cg.github.io/interact.
Read more5/28/2024
0
Simultaneous Detection and Interaction Reasoning for Object-Centric Action Recognition
Xunsong Li, Pengzhan Sun, Yangcen Liu, Lixin Duan, Wen Li
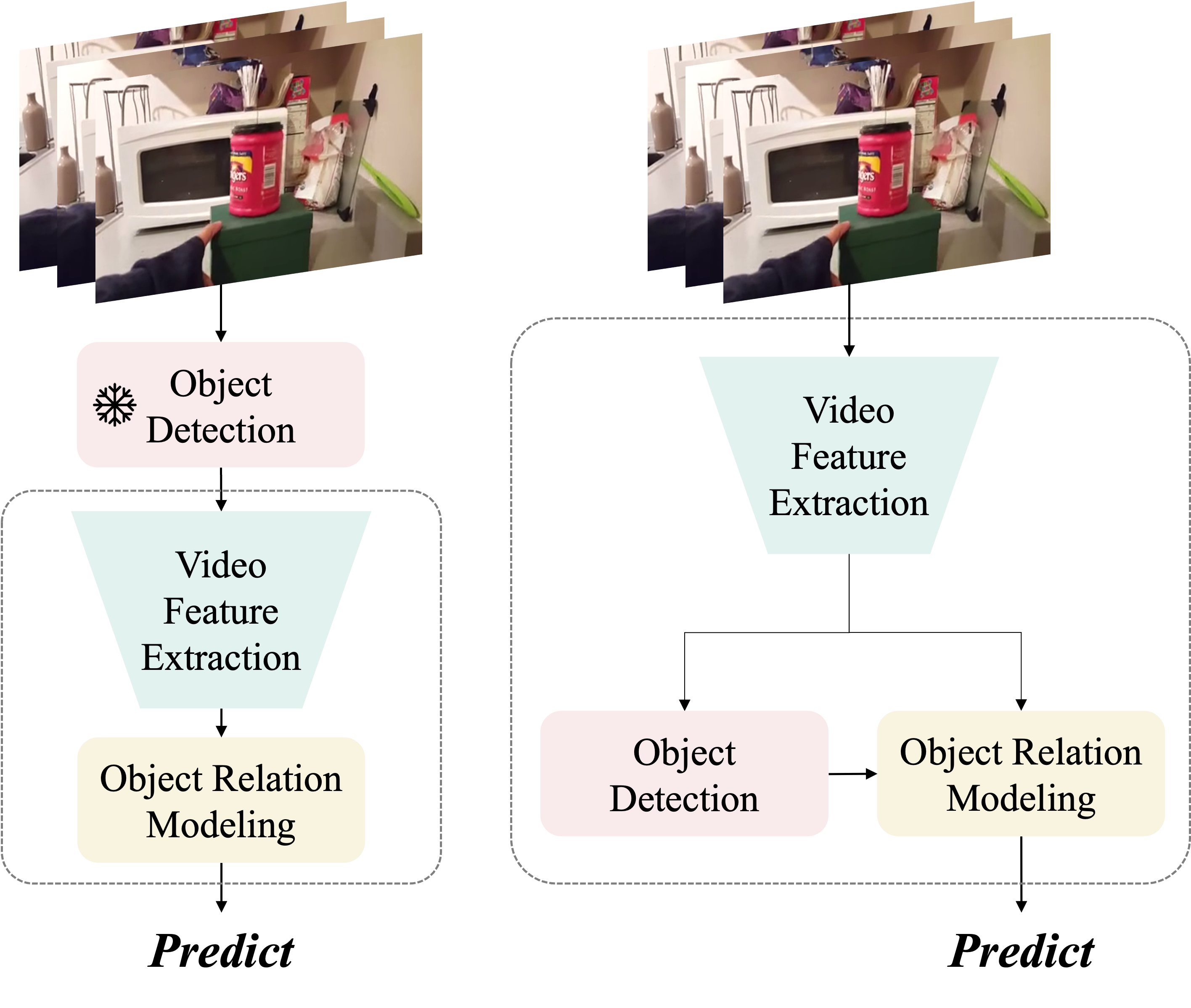
The interactions between human and objects are important for recognizing object-centric actions. Existing methods usually adopt a two-stage pipeline, where object proposals are first detected using a pretrained detector, and then are fed to an action recognition model for extracting video features and learning the object relations for action recognition. However, since the action prior is unknown in the object detection stage, important objects could be easily overlooked, leading to inferior action recognition performance. In this paper, we propose an end-to-end object-centric action recognition framework that simultaneously performs Detection And Interaction Reasoning in one stage. Particularly, after extracting video features with a base network, we create three modules for concurrent object detection and interaction reasoning. First, a Patch-based Object Decoder generates proposals from video patch tokens. Then, an Interactive Object Refining and Aggregation identifies important objects for action recognition, adjusts proposal scores based on position and appearance, and aggregates object-level info into a global video representation. Lastly, an Object Relation Modeling module encodes object relations. These three modules together with the video feature extractor can be trained jointly in an end-to-end fashion, thus avoiding the heavy reliance on an off-the-shelf object detector, and reducing the multi-stage training burden. We conduct experiments on two datasets, Something-Else and Ikea-Assembly, to evaluate the performance of our proposed approach on conventional, compositional, and few-shot action recognition tasks. Through in-depth experimental analysis, we show the crucial role of interactive objects in learning for action recognition, and we can outperform state-of-the-art methods on both datasets.
Read more4/19/2024