Interactive Masked Image Modeling for Multimodal Object Detection in Remote Sensing

0
Sign in to get full access
Overview
- The paper explores a self-supervised learning approach called Interactive Masked Image Modeling (IMIM) for multimodal object detection in remote sensing imagery.
- IMIM aims to learn robust visual representations by masking and predicting parts of an image, while also incorporating contextual information from other modalities like text.
- The proposed method is evaluated on several remote sensing datasets for object detection tasks, demonstrating improved performance compared to existing approaches.
Plain English Explanation
The researchers have developed a new way to train AI models to recognize objects in satellite and aerial images. This approach, called Interactive Masked Image Modeling (IMIM), works by hiding parts of the image and then asking the model to predict what's missing.
By doing this, the model learns to understand the visual patterns and context in the image. The researchers also incorporate information from other data sources, like text descriptions, to give the model a better understanding of the full scene.
This multi-modal approach, which combines visual and textual data, helps the model perform better at detecting various objects in remote sensing imagery, like buildings, vehicles, and infrastructure. The results show that IMIM outperforms existing object detection methods on several benchmark datasets.
Technical Explanation
The key idea behind IMIM is to leverage self-supervised learning, where the model learns visual representations by solving a pretext task of predicting masked image patches. This is combined with incorporating contextual information from other modalities, such as text descriptions, to enhance the model's understanding of the scene.
The IMIM architecture consists of a vision transformer that encodes the input image, and a text encoder that encodes any available text data. The model is trained to predict the masked image patches using the learned visual and textual representations. During inference, the trained model is used for downstream object detection tasks.
The researchers evaluate IMIM on several remote sensing datasets, including DOTA, UCAS-AOD, and OPTICALrs-4M. The results demonstrate that IMIM outperforms state-of-the-art object detection models, highlighting the benefits of the proposed self-supervised and multimodal approach.
Critical Analysis
The paper provides a comprehensive evaluation of IMIM on several remote sensing datasets, showcasing its effectiveness for object detection tasks. However, the authors do not deeply discuss potential limitations or caveats of the approach.
For example, the reliance on additional modalities, such as text data, may limit the applicability of IMIM in scenarios where such supplementary information is not available. Additionally, the performance of the model on rare or unusual object classes is not extensively explored.
Further research could investigate the model's robustness to various environmental conditions, sensor types, and data distributions commonly encountered in real-world remote sensing applications. Exploring the interpretability of the learned representations and their transferability to other vision tasks would also be valuable.
Conclusion
The Interactive Masked Image Modeling (IMIM) approach presented in this paper demonstrates a promising way to leverage self-supervised learning and multimodal data for improving object detection in remote sensing imagery.
By incorporating contextual information from text descriptions, IMIM learns more robust visual representations that lead to enhanced performance on object detection tasks. The results highlight the potential of such self-supervised and multimodal techniques to advance the field of remote sensing analysis and contribute to various applications, such as urban planning, infrastructure monitoring, and disaster response.
Further research to address the identified limitations and explore the broader applicability of IMIM could lead to even more impactful advancements in this domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Interactive Masked Image Modeling for Multimodal Object Detection in Remote Sensing
Minh-Duc Vu, Zuheng Ming, Fangchen Feng, Bissmella Bahaduri, Anissa Mokraoui
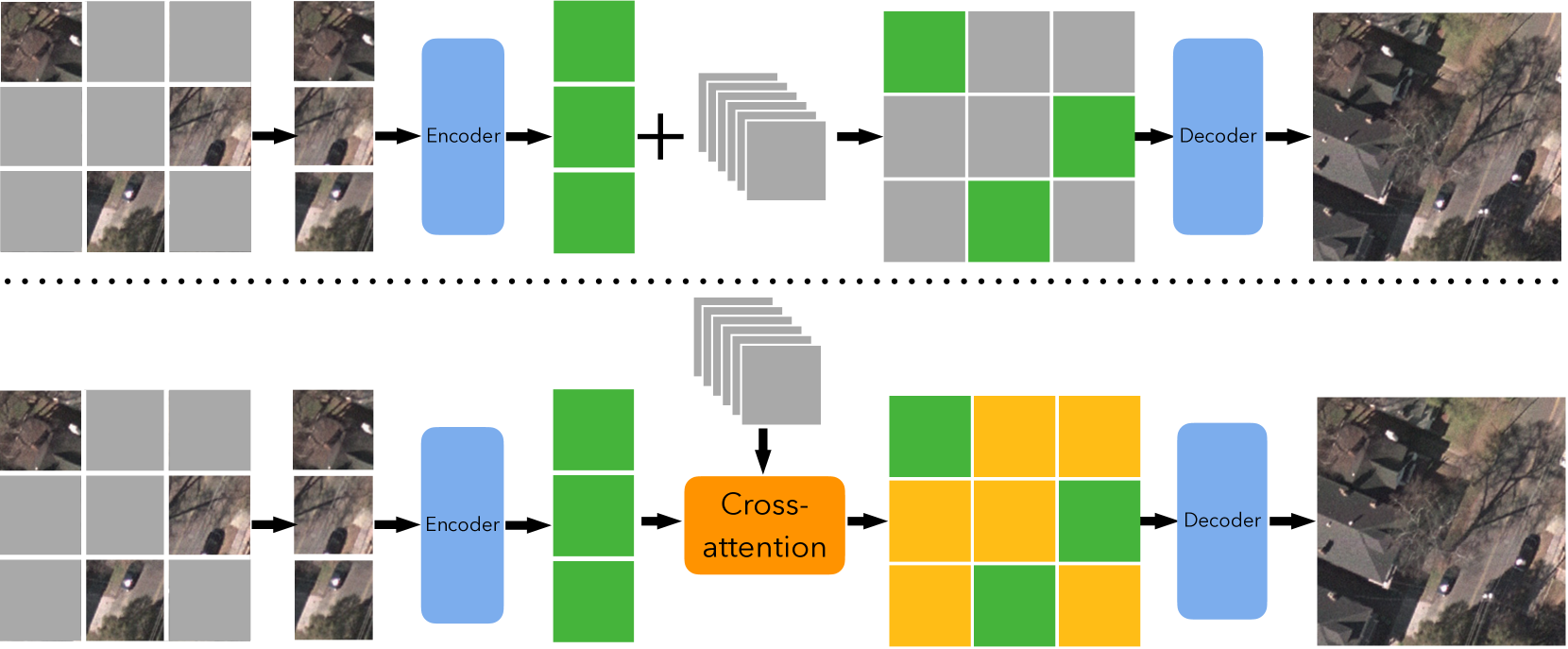
Object detection in remote sensing imagery plays a vital role in various Earth observation applications. However, unlike object detection in natural scene images, this task is particularly challenging due to the abundance of small, often barely visible objects across diverse terrains. To address these challenges, multimodal learning can be used to integrate features from different data modalities, thereby improving detection accuracy. Nonetheless, the performance of multimodal learning is often constrained by the limited size of labeled datasets. In this paper, we propose to use Masked Image Modeling (MIM) as a pre-training technique, leveraging self-supervised learning on unlabeled data to enhance detection performance. However, conventional MIM such as MAE which uses masked tokens without any contextual information, struggles to capture the fine-grained details due to a lack of interactions with other parts of image. To address this, we propose a new interactive MIM method that can establish interactions between different tokens, which is particularly beneficial for object detection in remote sensing. The extensive ablation studies and evluation demonstrate the effectiveness of our approach.
Read more9/16/2024
0
Masked Image Modeling: A Survey
Vlad Hondru, Florinel Alin Croitoru, Shervin Minaee, Radu Tudor Ionescu, Nicu Sebe
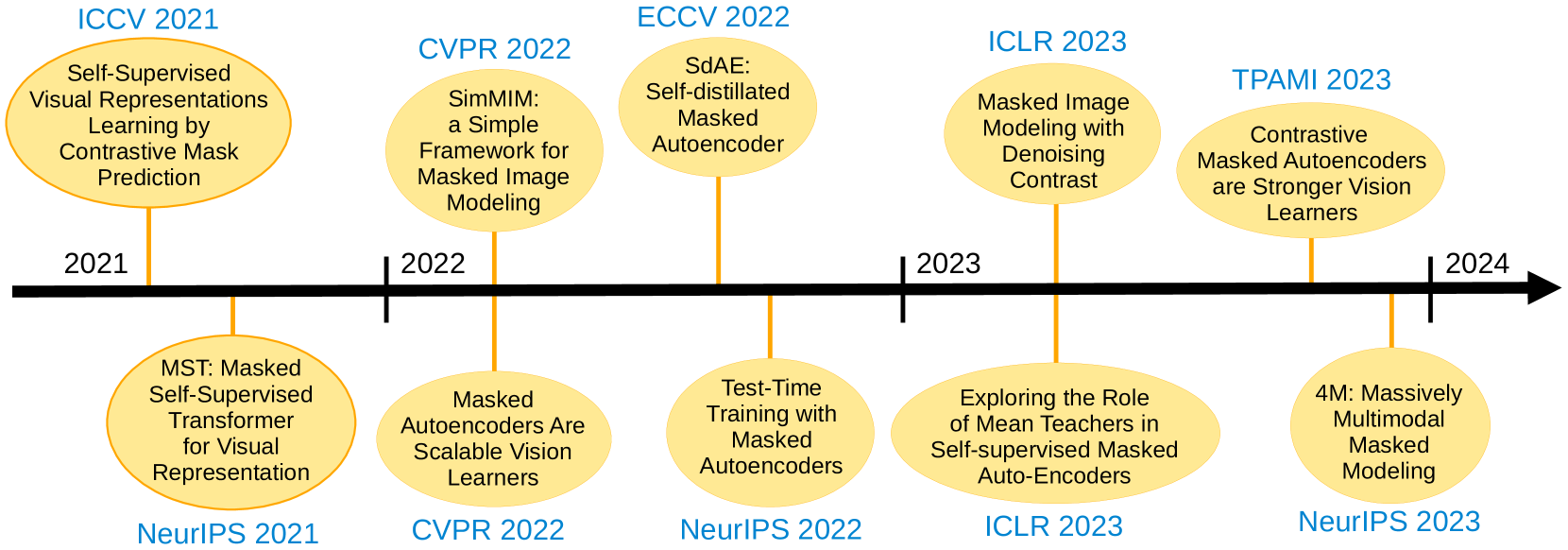
In this work, we survey recent studies on masked image modeling (MIM), an approach that emerged as a powerful self-supervised learning technique in computer vision. The MIM task involves masking some information, e.g. pixels, patches, or even latent representations, and training a model, usually an autoencoder, to predicting the missing information by using the context available in the visible part of the input. We identify and formalize two categories of approaches on how to implement MIM as a pretext task, one based on reconstruction and one based on contrastive learning. Then, we construct a taxonomy and review the most prominent papers in recent years. We complement the manually constructed taxonomy with a dendrogram obtained by applying a hierarchical clustering algorithm. We further identify relevant clusters via manually inspecting the resulting dendrogram. Our review also includes datasets that are commonly used in MIM research. We aggregate the performance results of various masked image modeling methods on the most popular datasets, to facilitate the comparison of competing methods. Finally, we identify research gaps and propose several interesting directions of future work.
Read more8/14/2024
0
CtxMIM: Context-Enhanced Masked Image Modeling for Remote Sensing Image Understanding
Mingming Zhang, Qingjie Liu, Yunhong Wang
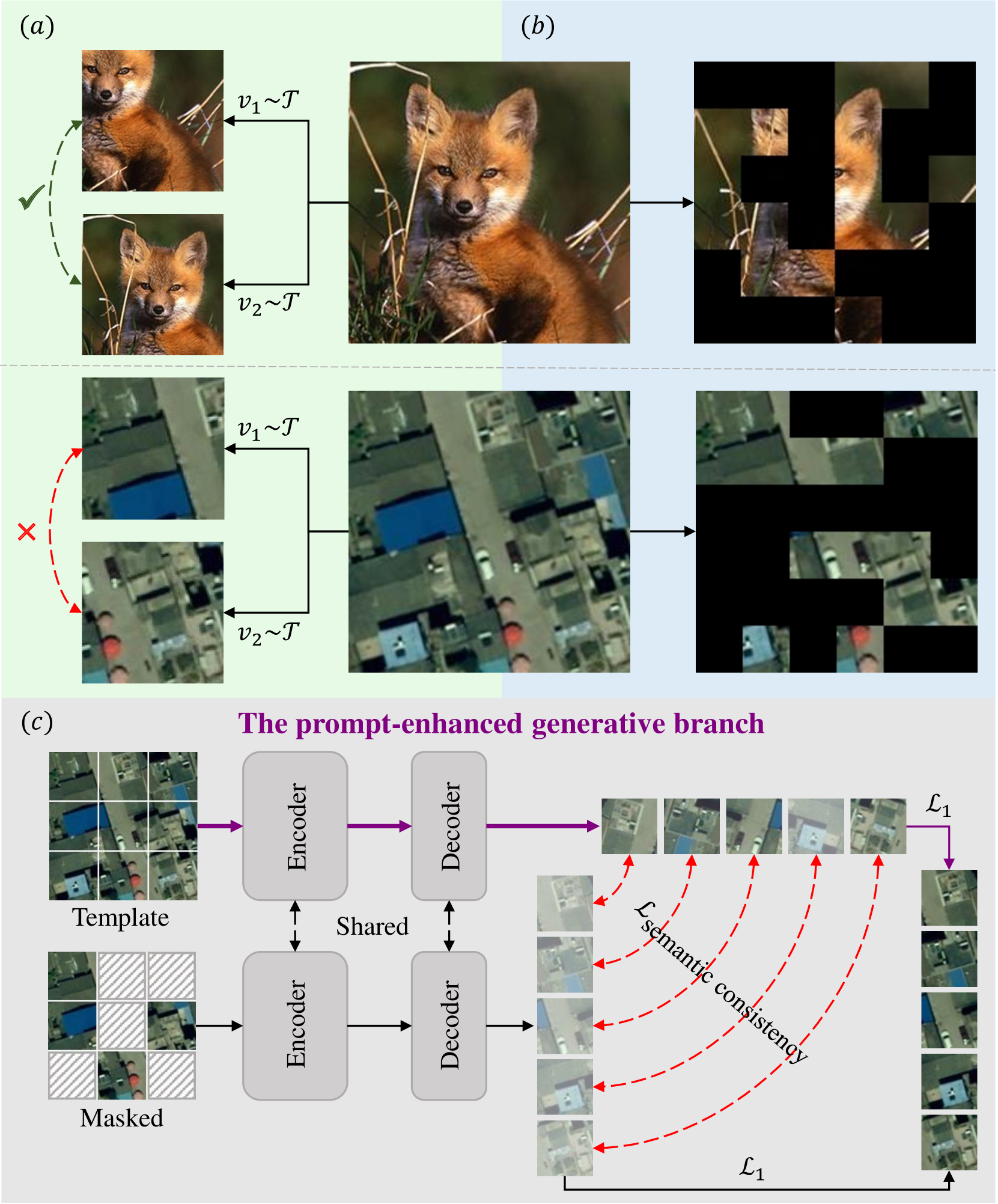
Learning representations through self-supervision on unlabeled data has proven highly effective for understanding diverse images. However, remote sensing images often have complex and densely populated scenes with multiple land objects and no clear foreground objects. This intrinsic property generates high object density, resulting in false positive pairs or missing contextual information in self-supervised learning. To address these problems, we propose a context-enhanced masked image modeling method (CtxMIM), a simple yet efficient MIM-based self-supervised learning for remote sensing image understanding. CtxMIM formulates original image patches as a reconstructive template and employs a Siamese framework to operate on two sets of image patches. A context-enhanced generative branch is introduced to provide contextual information through context consistency constraints in the reconstruction. With the simple and elegant design, CtxMIM encourages the pre-training model to learn object-level or pixel-level features on a large-scale dataset without specific temporal or geographical constraints. Finally, extensive experiments show that features learned by CtxMIM outperform fully supervised and state-of-the-art self-supervised learning methods on various downstream tasks, including land cover classification, semantic segmentation, object detection, and instance segmentation. These results demonstrate that CtxMIM learns impressive remote sensing representations with high generalization and transferability. Code and data will be made public available.
Read more5/24/2024
0
Towards Latent Masked Image Modeling for Self-Supervised Visual Representation Learning
Yibing Wei, Abhinav Gupta, Pedro Morgado
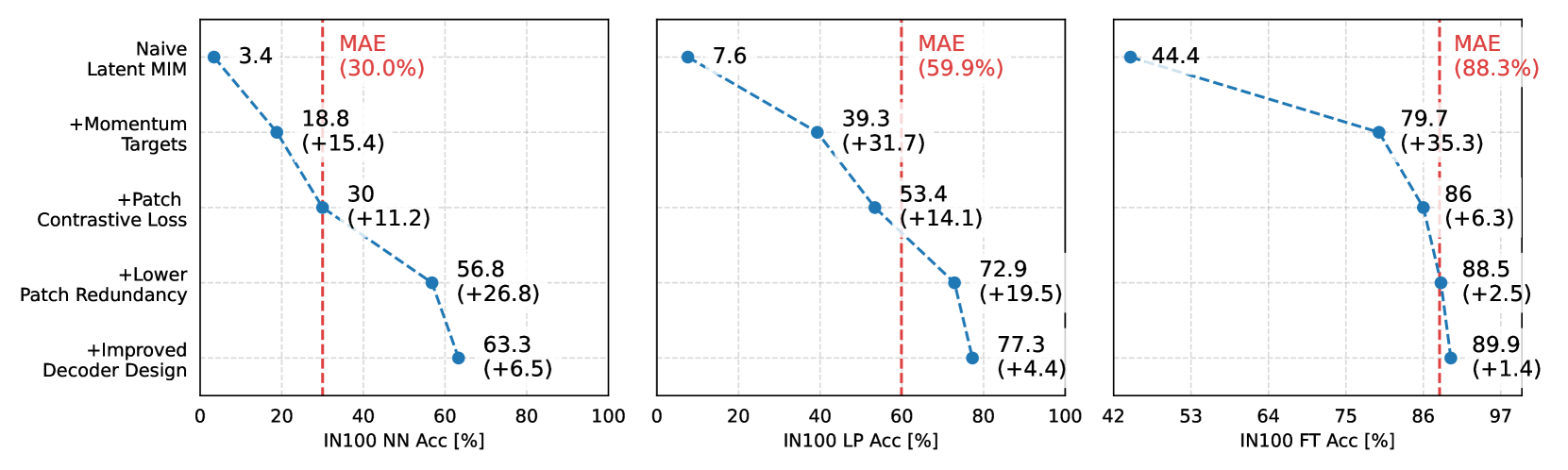
Masked Image Modeling (MIM) has emerged as a promising method for deriving visual representations from unlabeled image data by predicting missing pixels from masked portions of images. It excels in region-aware learning and provides strong initializations for various tasks, but struggles to capture high-level semantics without further supervised fine-tuning, likely due to the low-level nature of its pixel reconstruction objective. A promising yet unrealized framework is learning representations through masked reconstruction in latent space, combining the locality of MIM with the high-level targets. However, this approach poses significant training challenges as the reconstruction targets are learned in conjunction with the model, potentially leading to trivial or suboptimal solutions.Our study is among the first to thoroughly analyze and address the challenges of such framework, which we refer to as Latent MIM. Through a series of carefully designed experiments and extensive analysis, we identify the source of these challenges, including representation collapsing for joint online/target optimization, learning objectives, the high region correlation in latent space and decoding conditioning. By sequentially addressing these issues, we demonstrate that Latent MIM can indeed learn high-level representations while retaining the benefits of MIM models.
Read more7/23/2024