Towards Latent Masked Image Modeling for Self-Supervised Visual Representation Learning

0
Sign in to get full access
Overview
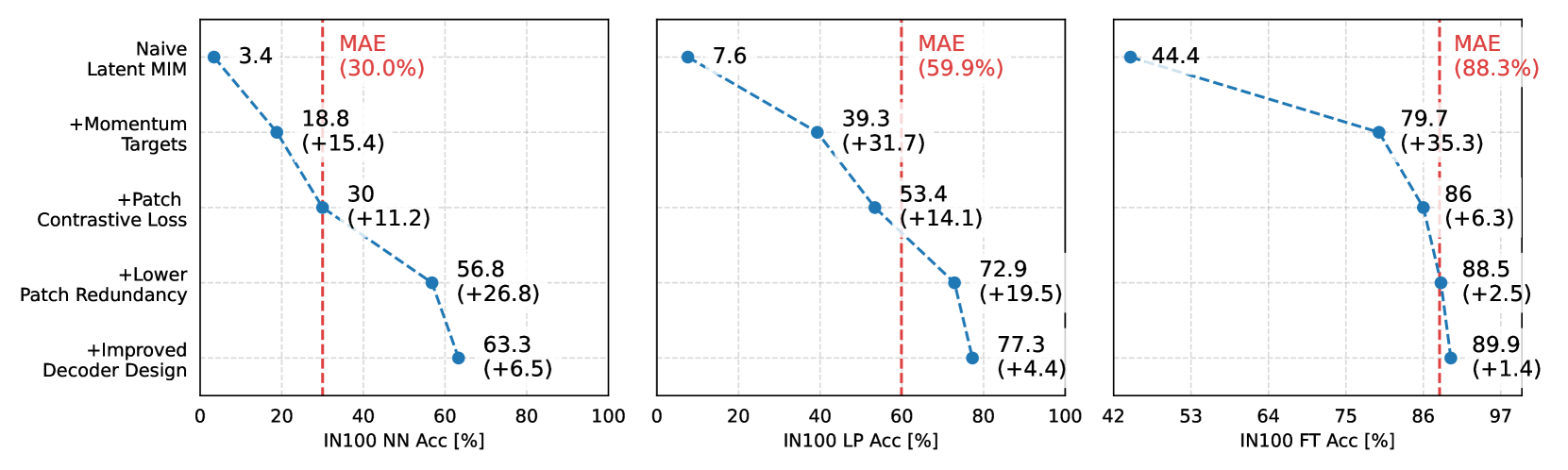
- The paper explores a self-supervised learning approach called Latent Masked Image Modeling (LMIM) for visual representation learning.
- LMIM aims to learn robust visual representations by predicting the latent representation of masked image regions.
- The model is trained to reconstruct the latent features of the masked regions based on the visible parts of the image.
Plain English Explanation
The researchers developed a new self-supervised learning technique called Latent Masked Image Modeling (LMIM) to help AI systems learn useful visual representations from images. Self-supervised learning is a way for AI models to learn features and patterns in data without being explicitly told what to look for.
In LMIM, the model is shown an image with some parts masked - meaning those regions are hidden from the model. The model then has to try to figure out what the hidden parts of the image look like based on the visible parts. To do this, the model predicts the "latent representation" of the masked regions, which is a way of encoding the underlying features and structure of those areas.
By learning to accurately predict the latent representation of the masked parts, the model develops a stronger understanding of the visual world. This helps it learn useful visual features and representations that can be applied to other computer vision tasks, like image classification or object detection, without needing labeled training data for those specific tasks.
The key idea is that forcing the model to reason about the hidden parts of the image encourages it to learn more robust and generalizable visual representations. This self-supervised approach could make it easier to build capable computer vision systems without the need for large amounts of labeled training data.
Technical Explanation
The core of the Latent Masked Image Modeling (LMIM) approach is to train a model to predict the latent representation of masked image regions based on the visible parts of the image. The model is composed of an encoder that extracts visual features from the input image and a decoder that reconstructs the latent representation of the masked regions.
During training, the model is presented with an input image where some regions have been randomly masked out. The encoder processes the visible parts of the image to produce a latent feature representation. The decoder then attempts to predict the latent representation of the masked regions based on this encoded feature map.
The training objective is to minimize the reconstruction error between the predicted latent representation and the true latent representation of the masked regions. By learning to accurately predict the latent features of the masked areas, the model is encouraged to develop a deeper understanding of the visual patterns and relationships in the image.
The key insight is that this self-supervised pretraining on latent masked image modeling can lead to more robust and generalizable visual representations that can be fine-tuned for a variety of downstream computer vision tasks. The authors demonstrate the effectiveness of this approach through extensive experiments on image classification, object detection, and other benchmarks.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the Latent Masked Image Modeling (LMIM) approach, demonstrating its effectiveness across a range of computer vision tasks. However, there are a few potential limitations and areas for further research:
-
Computational Complexity: The authors note that the LMIM framework incurs additional computational overhead compared to simpler masked image modeling approaches. The need to predict the latent representation of masked regions may limit the scalability of the technique, especially for high-resolution images.
-
Sensitivity to Masking Strategy: The performance of LMIM may be sensitive to the specific masking strategy employed during training. The authors experiment with different masking patterns, but more research is needed to understand how the masking approach impacts the learned representations.
-
Interpretability: While the LMIM framework leads to strong empirical performance, the inner workings of the model and the nature of the learned representations are not always interpretable. Developing techniques to better understand the representations learned by LMIM could lead to further insights and improvements.
-
Generalization to other Modalities: The current work focuses on visual representation learning, but it would be interesting to explore whether the LMIM approach could be extended to other data modalities, such as text or audio, to enable more cross-modal learning capabilities.
Overall, the Latent Masked Image Modeling technique represents a promising step forward in self-supervised visual representation learning, with the potential to reduce the reliance on large labeled datasets for building capable computer vision systems. Further research into the technique's scalability, interpretability, and generalization could lead to even more impactful advancements.
Conclusion
The Latent Masked Image Modeling (LMIM) approach presented in this paper offers a novel self-supervised learning technique for developing robust visual representations. By training models to predict the latent features of masked image regions, LMIM encourages the learning of generalizable visual patterns and relationships that can be effectively transferred to a variety of downstream computer vision tasks.
The strong empirical results demonstrated in the paper suggest that LMIM could be a valuable tool for building more capable and data-efficient computer vision systems. As the field of self-supervised learning continues to evolve, techniques like LMIM that leverage the inherent structure and redundancy in visual data hold great promise for advancing the state of the art in artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Latent Masked Image Modeling for Self-Supervised Visual Representation Learning
Yibing Wei, Abhinav Gupta, Pedro Morgado
Masked Image Modeling (MIM) has emerged as a promising method for deriving visual representations from unlabeled image data by predicting missing pixels from masked portions of images. It excels in region-aware learning and provides strong initializations for various tasks, but struggles to capture high-level semantics without further supervised fine-tuning, likely due to the low-level nature of its pixel reconstruction objective. A promising yet unrealized framework is learning representations through masked reconstruction in latent space, combining the locality of MIM with the high-level targets. However, this approach poses significant training challenges as the reconstruction targets are learned in conjunction with the model, potentially leading to trivial or suboptimal solutions.Our study is among the first to thoroughly analyze and address the challenges of such framework, which we refer to as Latent MIM. Through a series of carefully designed experiments and extensive analysis, we identify the source of these challenges, including representation collapsing for joint online/target optimization, learning objectives, the high region correlation in latent space and decoding conditioning. By sequentially addressing these issues, we demonstrate that Latent MIM can indeed learn high-level representations while retaining the benefits of MIM models.
Read more7/23/2024
0
Masked Image Modeling: A Survey
Vlad Hondru, Florinel Alin Croitoru, Shervin Minaee, Radu Tudor Ionescu, Nicu Sebe
In this work, we survey recent studies on masked image modeling (MIM), an approach that emerged as a powerful self-supervised learning technique in computer vision. The MIM task involves masking some information, e.g. pixels, patches, or even latent representations, and training a model, usually an autoencoder, to predicting the missing information by using the context available in the visible part of the input. We identify and formalize two categories of approaches on how to implement MIM as a pretext task, one based on reconstruction and one based on contrastive learning. Then, we construct a taxonomy and review the most prominent papers in recent years. We complement the manually constructed taxonomy with a dendrogram obtained by applying a hierarchical clustering algorithm. We further identify relevant clusters via manually inspecting the resulting dendrogram. Our review also includes datasets that are commonly used in MIM research. We aggregate the performance results of various masked image modeling methods on the most popular datasets, to facilitate the comparison of competing methods. Finally, we identify research gaps and propose several interesting directions of future work.
Read more8/14/2024
0
New!Interactive Masked Image Modeling for Multimodal Object Detection in Remote Sensing
Minh-Duc Vu, Zuheng Ming, Fangchen Feng, Bissmella Bahaduri, Anissa Mokraoui
Object detection in remote sensing imagery plays a vital role in various Earth observation applications. However, unlike object detection in natural scene images, this task is particularly challenging due to the abundance of small, often barely visible objects across diverse terrains. To address these challenges, multimodal learning can be used to integrate features from different data modalities, thereby improving detection accuracy. Nonetheless, the performance of multimodal learning is often constrained by the limited size of labeled datasets. In this paper, we propose to use Masked Image Modeling (MIM) as a pre-training technique, leveraging self-supervised learning on unlabeled data to enhance detection performance. However, conventional MIM such as MAE which uses masked tokens without any contextual information, struggles to capture the fine-grained details due to a lack of interactions with other parts of image. To address this, we propose a new interactive MIM method that can establish interactions between different tokens, which is particularly beneficial for object detection in remote sensing. The extensive ablation studies and evluation demonstrate the effectiveness of our approach.
Read more9/16/2024

0
Symmetric masking strategy enhances the performance of Masked Image Modeling
Khanh-Binh Nguyen, Chae Jung Park
Masked Image Modeling (MIM) is a technique in self-supervised learning that focuses on acquiring detailed visual representations from unlabeled images by estimating the missing pixels in randomly masked sections. It has proven to be a powerful tool for the preliminary training of Vision Transformers (ViTs), yielding impressive results across various tasks. Nevertheless, most MIM methods heavily depend on the random masking strategy to formulate the pretext task. This strategy necessitates numerous trials to ascertain the optimal dropping ratio, which can be resource-intensive, requiring the model to be pre-trained for anywhere between 800 to 1600 epochs. Furthermore, this approach may not be suitable for all datasets. In this work, we propose a new masking strategy that effectively helps the model capture global and local features. Based on this masking strategy, SymMIM, our proposed training pipeline for MIM is introduced. SymMIM achieves a new SOTA accuracy of 85.9% on ImageNet using ViT-Large and surpasses previous SOTA across downstream tasks such as image classification, semantic segmentation, object detection, instance segmentation tasks, and so on.
Read more8/26/2024