CtxMIM: Context-Enhanced Masked Image Modeling for Remote Sensing Image Understanding
2310.00022
0
0
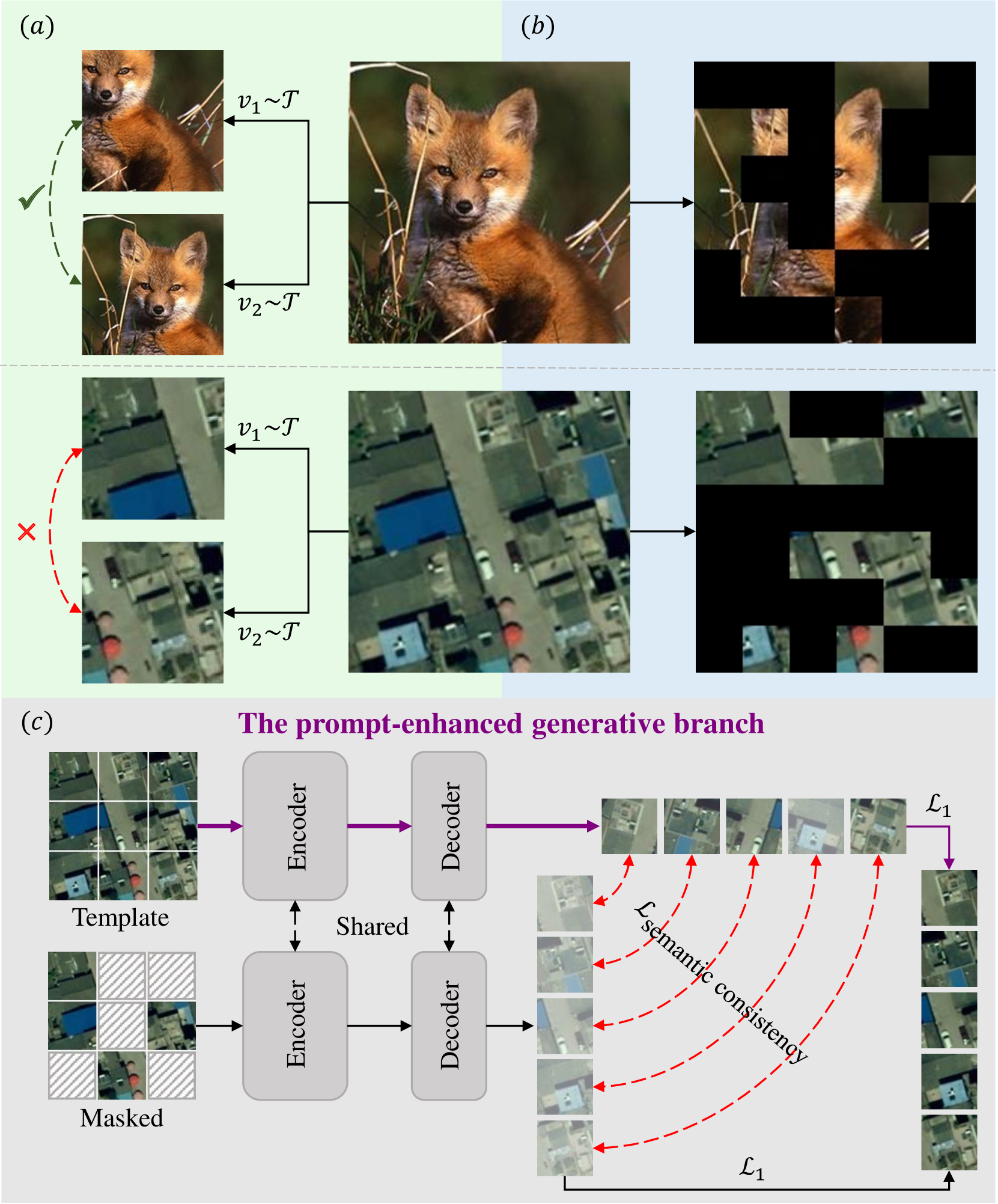
Abstract
Learning representations through self-supervision on unlabeled data has proven highly effective for understanding diverse images. However, remote sensing images often have complex and densely populated scenes with multiple land objects and no clear foreground objects. This intrinsic property generates high object density, resulting in false positive pairs or missing contextual information in self-supervised learning. To address these problems, we propose a context-enhanced masked image modeling method (CtxMIM), a simple yet efficient MIM-based self-supervised learning for remote sensing image understanding. CtxMIM formulates original image patches as a reconstructive template and employs a Siamese framework to operate on two sets of image patches. A context-enhanced generative branch is introduced to provide contextual information through context consistency constraints in the reconstruction. With the simple and elegant design, CtxMIM encourages the pre-training model to learn object-level or pixel-level features on a large-scale dataset without specific temporal or geographical constraints. Finally, extensive experiments show that features learned by CtxMIM outperform fully supervised and state-of-the-art self-supervised learning methods on various downstream tasks, including land cover classification, semantic segmentation, object detection, and instance segmentation. These results demonstrate that CtxMIM learns impressive remote sensing representations with high generalization and transferability. Code and data will be made public available.
Create account to get full access
Overview
- The paper presents a prompt-enhanced self-supervised representation learning approach for remote sensing image understanding.
- It explores the use of prompts to guide the self-supervised pretraining of deep learning models for remote sensing tasks.
- The method aims to improve the learned representations and downstream task performance compared to standard self-supervised learning.
Plain English Explanation
This research paper focuses on improving how deep learning models can understand and make sense of satellite and aerial images, which is an important capability for various remote sensing applications. The researchers developed a new approach called "prompt-enhanced self-supervised representation learning" that uses textual prompts to guide the process of pretraining the deep learning model before it is applied to specific tasks.
Typically, deep learning models for remote sensing are first pretrained on large datasets of unlabeled images using self-supervised learning techniques. This allows the model to learn general visual representations that can then be fine-tuned for particular tasks, like identifying different types of land cover or detecting changes over time. The key innovation in this paper is the use of textual prompts to provide additional guidance during the pretraining stage.
The prompts act as high-level descriptions or instructions that steer the model to learn representations that are more aligned with the desired capabilities for remote sensing tasks. For example, a prompt might ask the model to identify the different types of vegetation present in an image or to detect signs of human activity. By incorporating these prompts, the researchers found that the resulting representations were more useful for a variety of downstream remote sensing applications, leading to better performance compared to standard self-supervised pretraining.
The paper demonstrates the potential of this prompt-enhanced approach through experiments on several remote sensing datasets and tasks. The findings suggest that leveraging textual information in addition to the visual data can be a powerful way to develop deep learning models that are better equipped to understand and analyze remote sensing imagery.
Technical Explanation
The paper introduces a prompt-enhanced self-supervised representation learning approach for remote sensing image understanding. The key idea is to incorporate textual prompts during the self-supervised pretraining stage to guide the model in learning more useful representations for remote sensing tasks.
The authors build upon recent advancements in masked image modeling and contrastive learning techniques for self-supervised pretraining. They introduce a prompt-enhanced objective that encourages the model to not only reconstruct the masked regions of the input image, but also predict the provided textual prompt.
The prompts are designed to capture high-level semantics and task-relevant information for remote sensing, such as "identify the different types of vegetation in the image" or "detect signs of human activity." By aligning the model's learned representations with these prompts, the authors hypothesize that the pretraining will result in more useful features for downstream remote sensing tasks.
The proposed method is evaluated on several remote sensing datasets and tasks, including land cover classification, change detection, and object detection. The results demonstrate that the prompt-enhanced self-supervised representations outperform standard self-supervised pretraining and other baselines, highlighting the benefits of incorporating textual guidance during the pretraining stage.
Critical Analysis
The paper presents a novel and promising approach to improve the performance of deep learning models for remote sensing applications. The use of textual prompts to guide the self-supervised pretraining is a clever idea, as it allows the model to learn representations that are more aligned with the specific needs and characteristics of remote sensing tasks.
One potential limitation of the approach is the reliance on manually-crafted prompts. While the authors demonstrate the effectiveness of their prompt design, the process of creating appropriate prompts may be challenging and time-consuming, especially for a diverse range of remote sensing applications. An interesting avenue for future research could be the exploration of automatic prompt generation or learning techniques to make the process more scalable.
Additionally, the paper focuses on the pretraining stage and does not delve deeply into the specific downstream tasks and their unique challenges. It would be valuable to see a more comprehensive analysis of how the prompt-enhanced representations perform across a wider range of remote sensing applications, including their robustness to various environmental conditions, sensor characteristics, and data distribution shifts.
Overall, this research contributes a novel and promising direction in the field of remote sensing image understanding. The use of textual prompts to guide self-supervised representation learning is a creative approach that has the potential to significantly improve the performance of deep learning models in this domain.
Conclusion
The paper presents a prompt-enhanced self-supervised representation learning approach for remote sensing image understanding. By incorporating textual prompts during the pretraining stage, the method aims to learn more useful visual representations that can be effectively applied to a variety of downstream remote sensing tasks.
The key contribution of this work is the demonstration that guiding the self-supervised pretraining process with task-relevant semantic information, in the form of textual prompts, can lead to significant improvements in the performance of deep learning models for remote sensing applications. The experimental results across multiple datasets and tasks highlight the benefits of this prompt-enhanced approach compared to standard self-supervised learning.
This research opens up new avenues for developing more intelligent and capable deep learning systems for remote sensing, by leveraging the synergies between visual and textual information. The findings from this paper suggest that the integration of language-based guidance can be a powerful strategy for advancing the state-of-the-art in remote sensing image understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Scaling Efficient Masked Autoencoder Learning on Large Remote Sensing Dataset
Fengxiang Wang, Hongzhen Wang, Di Wang, Zonghao Guo, Zhenyu Zhong, Long Lan, Jing Zhang, Zhiyuan Liu, Maosong Sun
0
0
Masked Image Modeling (MIM) has emerged as a pivotal approach for developing foundational visual models in the field of remote sensing (RS). However, current RS datasets are limited in volume and diversity, which significantly constrains the capacity of MIM methods to learn generalizable representations. In this study, we introduce textbf{RS-4M}, a large-scale dataset designed to enable highly efficient MIM training on RS images. RS-4M comprises 4 million optical images encompassing abundant and fine-grained RS visual tasks, including object-level detection and pixel-level segmentation. Compared to natural images, RS images often contain massive redundant background pixels, which limits the training efficiency of the conventional MIM models. To address this, we propose an efficient MIM method, termed textbf{SelectiveMAE}, which dynamically encodes and reconstructs a subset of patch tokens selected based on their semantic richness. SelectiveMAE roots in a progressive semantic token selection module, which evolves from reconstructing semantically analogical tokens to encoding complementary semantic dependencies. This approach transforms conventional MIM training into a progressive feature learning process, enabling SelectiveMAE to efficiently learn robust representations of RS images. Extensive experiments show that SelectiveMAE significantly boosts training efficiency by 2.2-2.7 times and enhances the classification, detection, and segmentation performance of the baseline MIM model.The dataset, source code, and trained models will be released.
6/19/2024

SemanticMIM: Marring Masked Image Modeling with Semantics Compression for General Visual Representation
Yike Yuan, Huanzhang Dou, Fengjun Guo, Xi Li
0
0
This paper represents a neat yet effective framework, named SemanticMIM, to integrate the advantages of masked image modeling (MIM) and contrastive learning (CL) for general visual representation. We conduct a thorough comparative analysis between CL and MIM, revealing that their complementary advantages fundamentally stem from two distinct phases, i.e., compression and reconstruction. Specifically, SemanticMIM leverages a proxy architecture that customizes interaction between image and mask tokens, bridging these two phases to achieve general visual representation with the property of abundant semantic and positional awareness. Through extensive qualitative and quantitative evaluations, we demonstrate that SemanticMIM effectively amalgamates the benefits of CL and MIM, leading to significant enhancement of performance and feature linear separability. SemanticMIM also offers notable interpretability through attention response visualization. Codes are available at https://github.com/yyk-wew/SemanticMIM.
6/18/2024

Morphing Tokens Draw Strong Masked Image Models
Taekyung Kim, Byeongho Heo, Dongyoon Han
0
0
Masked image modeling (MIM) is a promising option for training Vision Transformers among various self-supervised learning (SSL) methods. The essence of MIM lies in token-wise masked token predictions, with targets tokenized from images or generated by pre-trained models such as vision-language models. While tokenizers or pre-trained models are plausible MIM targets, they often offer spatially inconsistent targets even for neighboring tokens, complicating models to learn unified discriminative representations. Our pilot study confirms that addressing spatial inconsistencies has the potential to enhance representation quality. Motivated by the findings, we introduce a novel self-supervision signal called Dynamic Token Morphing (DTM), which dynamically aggregates contextually related tokens to yield contextualized targets. DTM is compatible with various SSL frameworks; we showcase an improved MIM by employing DTM, barely introducing extra training costs. Our experiments on ImageNet-1K and ADE20K demonstrate the superiority of our methods compared with state-of-the-art, complex MIM methods. Furthermore, the comparative evaluation of the iNaturalists and fine-grained visual classification datasets further validates the transferability of our method on various downstream tasks. Code is available at https://github.com/naver-ai/dtm
5/3/2024
📈
MGIMM: Multi-Granularity Instruction Multimodal Model for Attribute-Guided Remote Sensing Image Detailed Description
Cong Yang, Zuchao Li, Lefei Zhang
0
0
Recently, large multimodal models have built a bridge from visual to textual information, but they tend to underperform in remote sensing scenarios. This underperformance is due to the complex distribution of objects and the significant scale differences among targets in remote sensing images, leading to visual ambiguities and insufficient descriptions by these multimodal models. Moreover, the lack of multimodal fine-tuning data specific to the remote sensing field makes it challenging for the model's behavior to align with user queries. To address these issues, this paper proposes an attribute-guided textbf{Multi-Granularity Instruction Multimodal Model (MGIMM)} for remote sensing image detailed description. MGIMM guides the multimodal model to learn the consistency between visual regions and corresponding text attributes (such as object names, colors, and shapes) through region-level instruction tuning. Then, with the multimodal model aligned on region-attribute, guided by multi-grain visual features, MGIMM fully perceives both region-level and global image information, utilizing large language models for comprehensive descriptions of remote sensing images. Due to the lack of a standard benchmark for generating detailed descriptions of remote sensing images, we construct a dataset featuring 38,320 region-attribute pairs and 23,463 image-detailed description pairs. Compared with various advanced methods on this dataset, the results demonstrate the effectiveness of MGIMM's region-attribute guided learning approach. Code can be available at https://github.com/yangcong356/MGIMM.git
6/10/2024