Wiki-LLaVA: Hierarchical Retrieval-Augmented Generation for Multimodal LLMs
2404.15406
0
0
Abstract
Multimodal LLMs are the natural evolution of LLMs, and enlarge their capabilities so as to work beyond the pure textual modality. As research is being carried out to design novel architectures and vision-and-language adapters, in this paper we concentrate on endowing such models with the capability of answering questions that require external knowledge. Our approach, termed Wiki-LLaVA, aims at integrating an external knowledge source of multimodal documents, which is accessed through a hierarchical retrieval pipeline. Relevant passages, using this approach, are retrieved from the external knowledge source and employed as additional context for the LLM, augmenting the effectiveness and precision of generated dialogues. We conduct extensive experiments on datasets tailored for visual question answering with external data and demonstrate the appropriateness of our approach.
Create account to get full access
Overview
- This paper introduces Wiki-LLaVA, a hierarchical retrieval-augmented generation model for multimodal large language models (LLMs).
- The key idea is to leverage a two-stage retrieval process to enhance the generation capabilities of multimodal LLMs.
- The model first retrieves relevant information from a knowledge base and then uses this information to generate more coherent and informative responses.
Plain English Explanation
Wiki-LLaVA is a new AI system that aims to improve the performance of large language models that can understand and generate text as well as process images. The main challenge with these models is that they can sometimes produce responses that lack coherence or relevant information.
To address this, the researchers developed a two-step process. First, the model searches through a large database of information (like an online encyclopedia) to find the most relevant facts and details to include in the response. Then, it uses these retrieved details to generate a more informed and coherent output.
This hierarchical approach, where the model first retrieves relevant information and then uses it to generate a response, helps the model provide better answers to questions or prompts. It's like a person first doing research on a topic and then using that knowledge to craft a thoughtful, well-informed response, rather than just guessing or relying on limited information.
By combining powerful language understanding with targeted information retrieval, Wiki-LLaVA aims to create more knowledgeable and coherent multimodal AI systems that can better assist users with a variety of tasks.
Technical Explanation
The key innovation in Wiki-LLaVA is the use of a hierarchical retrieval-augmented generation approach to enhance the performance of multimodal LLMs. The model first retrieves relevant information from a large knowledge base, such as Wikipedia, using a dense retrieval system. It then conditions the text generation on the retrieved information to produce more coherent and informative responses.
The architecture consists of several components:
- Multimodal Encoder: Encodes the input text and image into a shared latent representation.
- Retrieval Module: Retrieves the most relevant passages from the knowledge base given the input.
- Generation Module: Generates the output text conditioned on the input and the retrieved information.
The key advantage of this approach is that it allows the model to draw upon a vast external knowledge base to supplement its own internal knowledge, leading to more informed and coherent responses. This is particularly important for multimodal tasks where the model needs to reason about both text and visual information.
The researchers evaluate Wiki-LLaVA on a range of multimodal tasks, including visual question answering, image captioning, and open-ended dialogue. The results show that the hierarchical retrieval-augmented approach outperforms strong baselines, demonstrating the benefits of this approach for enhancing the capabilities of multimodal LLMs.
Critical Analysis
The Wiki-LLaVA paper presents a promising approach for improving the performance of multimodal LLMs, but there are a few potential limitations and areas for further research:
-
Knowledge Base Quality and Coverage: The performance of the retrieval module is heavily dependent on the quality and coverage of the underlying knowledge base. The researchers used Wikipedia, but the information may not always be up-to-date or comprehensive, especially for more specialized or niche topics.
-
Retrieval Accuracy: The retrieval module is a critical component, and its performance can impact the overall quality of the generated responses. Improving the accuracy and relevance of the retrieved information could further enhance the model's capabilities.
-
Generalization to Other Domains: While the paper demonstrates the effectiveness of Wiki-LLaVA on several multimodal tasks, it would be valuable to explore its performance on a broader range of applications and domains, such as HAMMR for generic VQA or UDKAG for augmenting large vision-language models.
-
Interpretability and Transparency: As with many complex AI systems, understanding the inner workings and decision-making process of Wiki-LLaVA could be challenging. Approaches like Explaining Multi-Modal Large Language Models could help improve the model's interpretability and transparency.
Overall, the Wiki-LLaVA paper presents a compelling approach to enhance the capabilities of multimodal LLMs, and the proposed hierarchical retrieval-augmented generation technique is a valuable contribution to the field of Retrieval-Augmented Generation for Large Language Models.
Conclusion
Wiki-LLaVA introduces a novel hierarchical retrieval-augmented generation approach to improve the performance of multimodal LLMs. By leveraging a two-stage retrieval process to supplement the model's internal knowledge, Wiki-LLaVA can generate more coherent and informative responses, particularly for tasks that require reasoning about both text and visual information.
The key innovation of this work is the integration of powerful language understanding, targeted information retrieval, and text generation, which collectively enhance the capabilities of multimodal LLMs. As AI systems become more ubiquitous in our daily lives, advancements like Wiki-LLaVA will be crucial in developing AI assistants that can provide more knowledgeable, coherent, and useful support across a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
0
0
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
6/7/2024
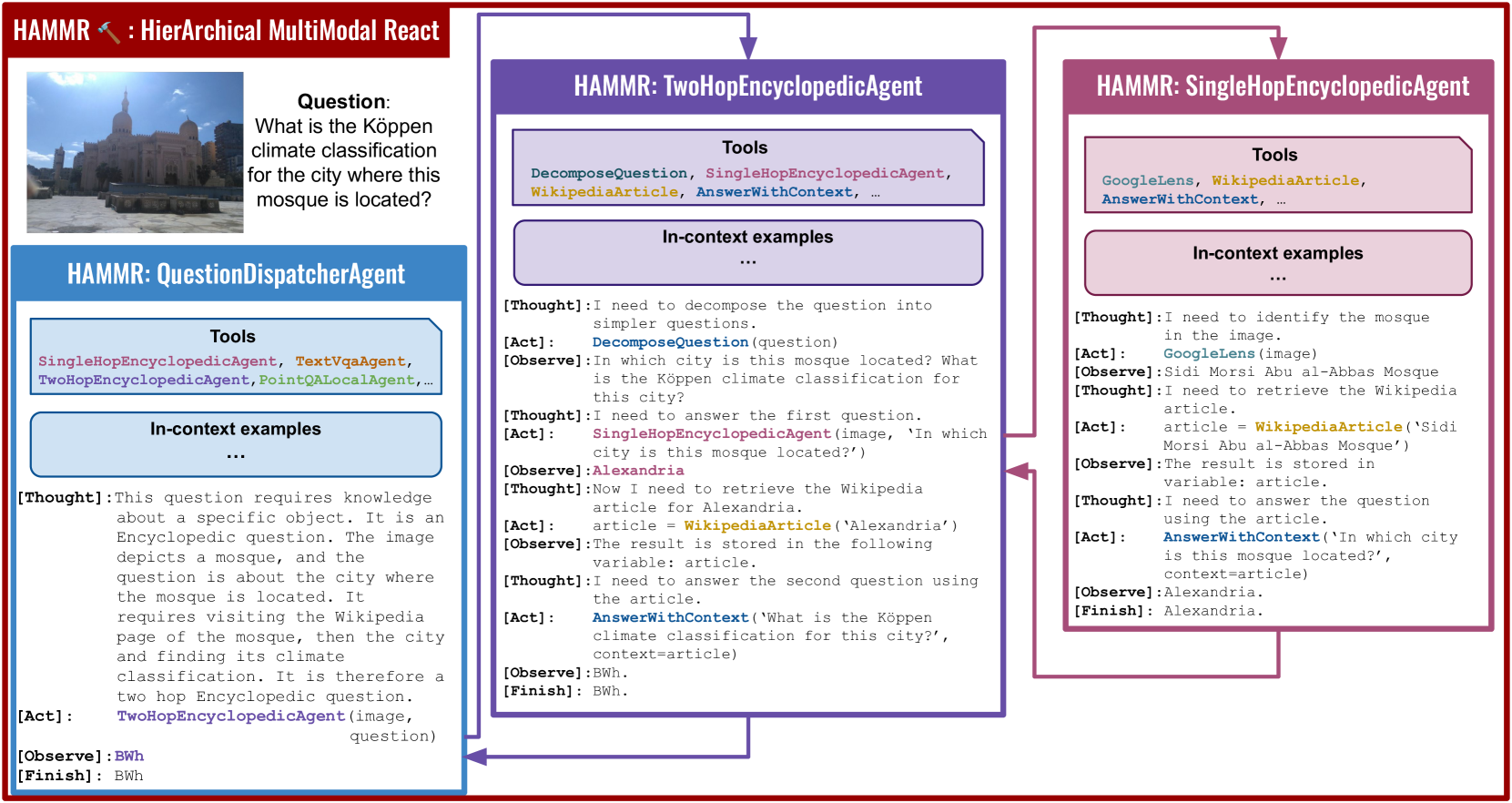
HAMMR: HierArchical MultiModal React agents for generic VQA
Lluis Castrejon, Thomas Mensink, Howard Zhou, Vittorio Ferrari, Andre Araujo, Jasper Uijlings
0
0
Combining Large Language Models (LLMs) with external specialized tools (LLMs+tools) is a recent paradigm to solve multimodal tasks such as Visual Question Answering (VQA). While this approach was demonstrated to work well when optimized and evaluated for each individual benchmark, in practice it is crucial for the next generation of real-world AI systems to handle a broad range of multimodal problems. Therefore we pose the VQA problem from a unified perspective and evaluate a single system on a varied suite of VQA tasks including counting, spatial reasoning, OCR-based reasoning, visual pointing, external knowledge, and more. In this setting, we demonstrate that naively applying the LLM+tools approach using the combined set of all tools leads to poor results. This motivates us to introduce HAMMR: HierArchical MultiModal React. We start from a multimodal ReAct-based system and make it hierarchical by enabling our HAMMR agents to call upon other specialized agents. This enhances the compositionality of the LLM+tools approach, which we show to be critical for obtaining high accuracy on generic VQA. Concretely, on our generic VQA suite, HAMMR outperforms the naive LLM+tools approach by 19.5%. Additionally, HAMMR achieves state-of-the-art results on this task, outperforming the generic standalone PaLI-X VQA model by 5.0%.
4/9/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024

LLMs Meet Multimodal Generation and Editing: A Survey
Yingqing He, Zhaoyang Liu, Jingye Chen, Zeyue Tian, Hongyu Liu, Xiaowei Chi, Runtao Liu, Ruibin Yuan, Yazhou Xing, Wenhai Wang, Jifeng Dai, Yong Zhang, Wei Xue, Qifeng Liu, Yike Guo, Qifeng Chen
0
0
With the recent advancement in large language models (LLMs), there is a growing interest in combining LLMs with multimodal learning. Previous surveys of multimodal large language models (MLLMs) mainly focus on multimodal understanding. This survey elaborates on multimodal generation and editing across various domains, comprising image, video, 3D, and audio. Specifically, we summarize the notable advancements with milestone works in these fields and categorize these studies into LLM-based and CLIP/T5-based methods. Then, we summarize the various roles of LLMs in multimodal generation and exhaustively investigate the critical technical components behind these methods and the multimodal datasets utilized in these studies. Additionally, we dig into tool-augmented multimodal agents that can leverage existing generative models for human-computer interaction. Lastly, we discuss the advancements in the generative AI safety field, investigate emerging applications, and discuss future prospects. Our work provides a systematic and insightful overview of multimodal generation and processing, which is expected to advance the development of Artificial Intelligence for Generative Content (AIGC) and world models. A curated list of all related papers can be found at https://github.com/YingqingHe/Awesome-LLMs-meet-Multimodal-Generation
6/11/2024