Interaural time difference loss for binaural target sound extraction

0

Sign in to get full access
Overview
- The paper discusses a method for binaural target sound extraction using interaural time difference (ITD) loss.
- The goal is to selectively extract a target sound from a mixture of sounds while preserving the spatial properties of the target sound.
- The proposed method uses a deep learning model to estimate the ITD of the target sound and minimize the loss between the estimated and ground truth ITDs.
Plain English Explanation
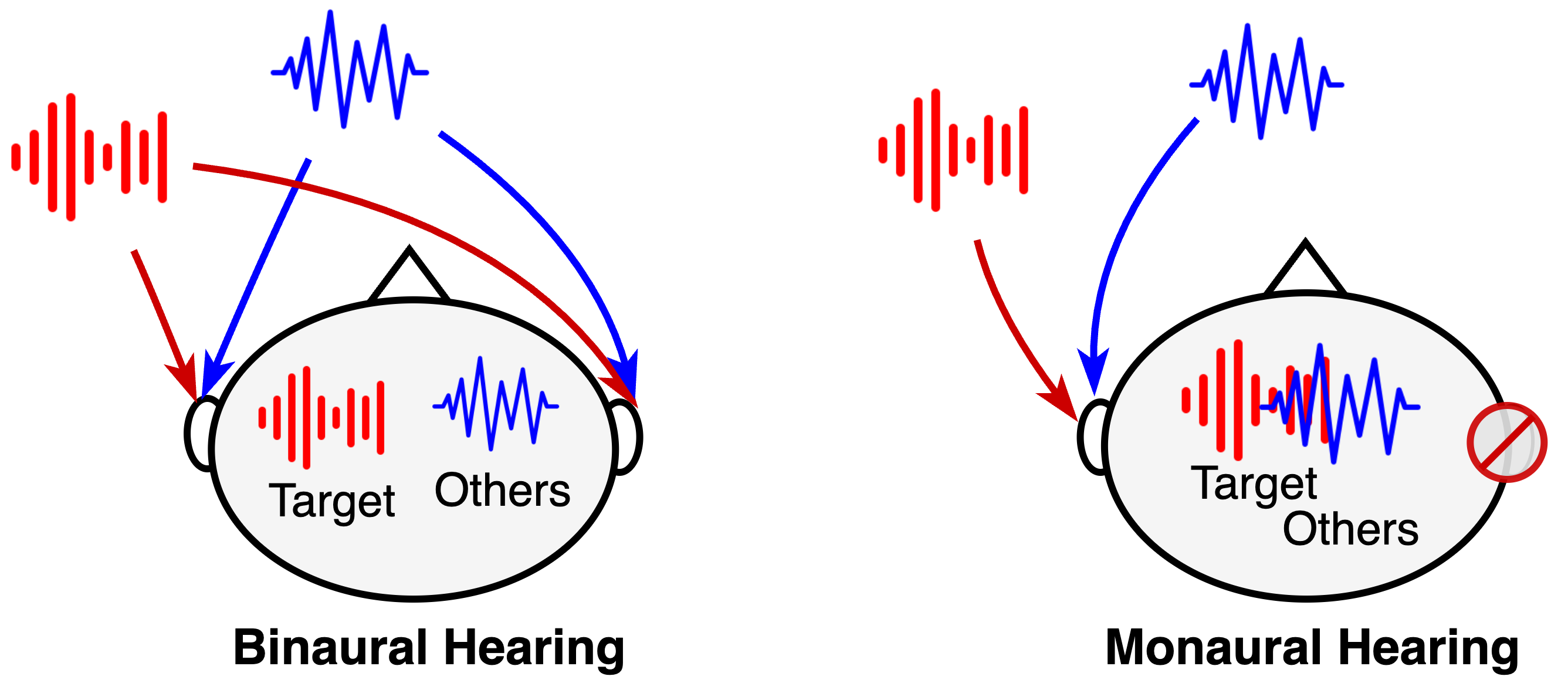
When we hear sounds, our two ears detect slight differences in the time it takes for the sound to reach each ear. This interaural time difference (ITD) provides important cues about the spatial location of the sound source.
The paper explores a way to extract a target sound from a mix of sounds while preserving the ITD information. This could be useful for applications like hearing aids, where you want to focus on a particular person's voice while still being aware of the surrounding environment.
The method uses a deep learning model to estimate the ITD of the target sound. It then tries to minimize the difference between the estimated ITD and the actual ITD of the target sound. This helps the model isolate the target sound while maintaining its spatial properties.
Technical Explanation
The proposed approach uses a deep neural network to extract a target sound from a binaural (two-channel) audio mixture. The key idea is to explicitly preserve the interaural time difference (ITD) of the target sound during the extraction process.
The model takes the binaural mixture as input and outputs an estimate of the target sound's ITD. The network is trained to minimize the L1 loss between the estimated ITD and the ground truth ITD of the target, which is obtained from the clean target signal.
By preserving the ITD, the extracted target sound maintains its spatial properties, allowing the listener to still perceive the target's location in the acoustic scene. This is in contrast to other techniques that may distort the spatial cues during sound separation.
Critical Analysis
The paper presents a novel approach to binaural target sound extraction that is focused on preserving the spatial properties of the target. This is an important consideration for applications like hearing aids, where maintaining environmental awareness is crucial.
One potential limitation mentioned in the paper is that the method may not perform as well in reverberant environments, where the ITD cues can be distorted. The authors suggest exploring ways to incorporate additional spatial cues, such as interaural level difference, to improve performance in complex acoustic scenarios.
Additionally, the paper does not provide a direct comparison to other state-of-the-art binaural source separation techniques. Further research could evaluate the proposed method against a wider range of baselines to better understand its relative strengths and weaknesses.
Conclusion
The paper presents a novel approach to binaural target sound extraction that focuses on preserving the spatial properties of the target sound. By explicitly incorporating interaural time difference (ITD) information into the extraction process, the method can isolate a target sound while maintaining its perceived location within the acoustic scene.
This work could have important implications for applications like hearing aids, where selectively attending to a target sound while still being aware of the surrounding environment is crucial. Future research could explore ways to further improve the method's performance in challenging acoustic conditions and compare it to other state-of-the-art techniques in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Interaural time difference loss for binaural target sound extraction
Carlos Hernandez-Olivan, Marc Delcroix, Tsubasa Ochiai, Naohiro Tawara, Tomohiro Nakatani, Shoko Araki
Binaural target sound extraction (TSE) aims to extract a desired sound from a binaural mixture of arbitrary sounds while preserving the spatial cues of the desired sound. Indeed, for many applications, the target sound signal and its spatial cues carry important information about the sound source. Binaural TSE can be realized with a neural network trained to output only the desired sound given a binaural mixture and an embedding characterizing the desired sound class as inputs. Conventional TSE systems are trained using signal-level losses, which measure the difference between the extracted and reference signals for the left and right channels. In this paper, we propose adding explicit spatial losses to better preserve the spatial cues of the target sound. In particular, we explore losses aiming at preserving the interaural level (ILD), phase (IPD), and time differences (ITD). We show experimentally that adding such spatial losses, particularly our newly proposed ITD loss, helps preserve better spatial cues while maintaining the signal-level metrics.
Read more8/2/2024
0
Binaural Selective Attention Model for Target Speaker Extraction
Hanyu Meng, Qiquan Zhang, Xiangyu Zhang, Vidhyasaharan Sethu, Eliathamby Ambikairajah
The remarkable ability of humans to selectively focus on a target speaker in cocktail party scenarios is facilitated by binaural audio processing. In this paper, we present a binaural time-domain Target Speaker Extraction model based on the Filter-and-Sum Network (FaSNet). Inspired by human selective hearing, our proposed model introduces target speaker embedding into separators using a multi-head attention-based selective attention block. We also compared two binaural interaction approaches -- the cosine similarity of time-domain signals and inter-channel correlation in learned spectral representations. Our experimental results show that our proposed model outperforms monaural configurations and state-of-the-art multi-channel target speaker extraction models, achieving best-in-class performance with 18.52 dB SI-SDR, 19.12 dB SDR, and 3.05 PESQ scores under anechoic two-speaker test configurations.
Read more6/19/2024

0
TSE-PI: Target Sound Extraction under Reverberant Environments with Pitch Information
Yiwen Wang, Xihong Wu
Target sound extraction (TSE) separates the target sound from the mixture signals based on provided clues. However, the performance of existing models significantly degrades under reverberant conditions. Inspired by auditory scene analysis (ASA), this work proposes a TSE model provided with pitch information named TSE-PI. Conditional pitch extraction is achieved through the Feature-wise Linearly Modulated layer with the sound-class label. A modified Waveformer model combined with pitch information, employing a learnable Gammatone filterbank in place of the convolutional encoder, is used for target sound extraction. The inclusion of pitch information is aimed at improving the model's performance. The experimental results on the FSD50K dataset illustrate 2.4 dB improvements of target sound extraction under reverberant environments when incorporating pitch information and Gammatone filterbank.
Read more6/14/2024

0
New!Language-Queried Target Sound Extraction Without Parallel Training Data
Hao Ma, Zhiyuan Peng, Xu Li, Yukai Li, Mingjie Shao, Qiuqiang Kong, Ju Liu
Language-queried target sound extraction (TSE) aims to extract specific sounds from mixtures based on language queries. Traditional fully-supervised training schemes require extensively annotated parallel audio-text data, which are labor-intensive. We introduce a language-free training scheme, requiring only unlabelled audio clips for TSE model training by utilizing the multi-modal representation alignment nature of the contrastive language-audio pre-trained model (CLAP). In a vanilla language-free training stage, target audio is encoded using the pre-trained CLAP audio encoder to form a condition embedding for the TSE model, while during inference, user language queries are encoded by CLAP text encoder. This straightforward approach faces challenges due to the modality gap between training and inference queries and information leakage from direct exposure to target audio during training. To address this, we propose a retrieval-augmented strategy. Specifically, we create an embedding cache using audio captions generated by a large language model (LLM). During training, target audio embeddings retrieve text embeddings from this cache to use as condition embeddings, ensuring consistent modalities between training and inference and eliminating information leakage. Extensive experiment results show that our retrieval-augmented approach achieves consistent and notable performance improvements over existing state-of-the-art with better generalizability.
Read more9/17/2024