Interpolating Video-LLMs: Toward Longer-sequence LMMs in a Training-free Manner

0
Sign in to get full access
Overview
- Interpolating Video-LLMs: Toward Longer-sequence LMMs in a Training-free Manner is a research paper that proposes a new approach to training large language models (LLMs) on longer video sequences.
- The key ideas are:
- Developing a "training-free" method to extend the sequence length of LLMs beyond what they were originally trained on.
- Applying this technique to video data, allowing LLMs to process and reason about longer video clips.
- This could enable more advanced video understanding capabilities for LLMs, with potential applications in areas like video summarization, captioning, and question answering.
Plain English Explanation
Large language models (LLMs) have shown impressive abilities in processing and understanding text. However, they are typically trained on relatively short sequences, limiting their ability to work with longer inputs like videos.
The researchers in this paper propose a new technique called "Interpolating Video-LLMs" to address this limitation. The core idea is to develop a "training-free" method that can take an existing LLM trained on short sequences and extend its capabilities to handle much longer sequences, without having to retrain the entire model from scratch.
The researchers apply this technique specifically to video data, allowing the LLM to process and reason about longer video clips. This could unlock new applications like improved video summarization, where the model can extract key highlights from an extended video, or more sophisticated video question answering, where the model can draw insights from the full video context.
The key innovation is that this extension to longer sequences happens in a "training-free" manner - the researchers don't need to retrain the entire LLM model, which can be computationally expensive and time-consuming. Instead, they develop a method to "interpolate" the LLM's internal representations, allowing it to handle longer inputs without modifying the original model.
Overall, this research represents an important step towards making LLMs more capable of working with extended, real-world data like videos, opening up new possibilities for video understanding and reasoning.
Technical Explanation
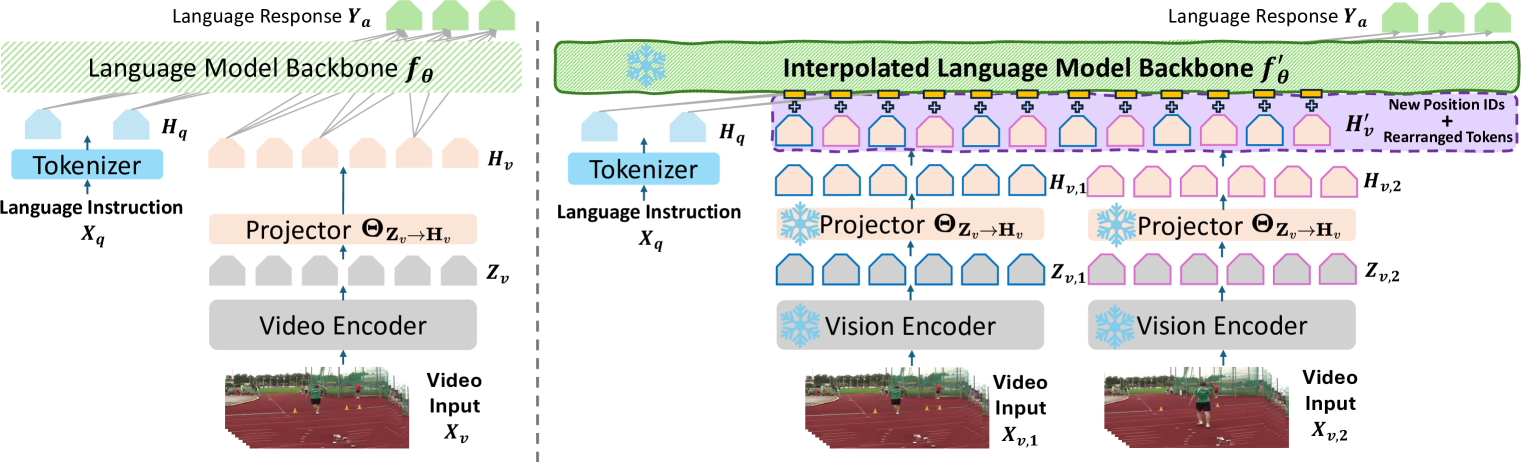
The central technical contribution of this paper is the development of a "training-free" method to extend the sequence length of large language models (LLMs) beyond what they were originally trained on. The researchers call this approach "Interpolating Video-LLMs."
The key steps are:
- Embedding Extraction: The researchers take an existing LLM (e.g. GPT-3) and extract its internal embeddings for short input sequences.
- Sequence Interpolation: They then develop a novel interpolation technique to generate embeddings for longer input sequences, without having to retrain the entire LLM.
- Video Application: The researchers apply this interpolation method specifically to video data, allowing the LLM to process and reason about longer video clips.
The interpolation technique works by learning a mapping function that can take the LLM's original embeddings for short sequences and generate plausible embeddings for longer sequences. This is done in a "training-free" manner, meaning the original LLM model is not modified or retrained.
The researchers evaluate their Interpolating Video-LLM approach on various video understanding tasks, including video summarization and question answering. They demonstrate that the extended LLM can outperform standard LLMs that were not adapted for longer video inputs.
Critical Analysis
One key limitation of this work is that the interpolation technique, while effective, still relies on the availability of an LLM pre-trained on shorter sequences. The researchers do not address how one might train such an LLM from scratch to handle longer sequences natively.
Additionally, the paper does not provide a rigorous analysis of the computational and memory efficiency of the interpolation method. While it is touted as "training-free," there may still be significant overhead in applying the interpolation technique that could limit its practical deployment.
Further research is also needed to understand the robustness and generalization capabilities of the Interpolating Video-LLM approach. The experiments focus on relatively narrow video understanding tasks - it's unclear how well the technique would scale to more open-ended video reasoning or other modalities beyond text and video.
Overall, this work represents an important step forward in enhancing the sequence processing capabilities of large language models. However, there are still significant challenges to overcome in making such techniques truly practical and widely applicable.
Conclusion
The "Interpolating Video-LLMs" research presents a novel approach to extend the sequence length of large language models beyond their original training, with a specific focus on applying this to video data.
By developing a "training-free" interpolation technique, the researchers have found a way to equip LLMs with the ability to process and reason about longer video inputs, opening up new possibilities for advanced video understanding tasks like summarization and question answering.
While the approach has some limitations in terms of its reliance on pre-trained LLMs and the need for further efficiency and robustness analysis, this work represents an important step forward in enhancing the capabilities of large language models to handle real-world, extended data sources. As LLMs become more widely deployed, techniques like Interpolating Video-LLMs will be crucial for expanding their practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Interpolating Video-LLMs: Toward Longer-sequence LMMs in a Training-free Manner
Yuzhang Shang, Bingxin Xu, Weitai Kang, Mu Cai, Yuheng Li, Zehao Wen, Zhen Dong, Kurt Keutzer, Yong Jae Lee, Yan Yan
Advancements in Large Language Models (LLMs) inspire various strategies for integrating video modalities. A key approach is Video-LLMs, which incorporate an optimizable interface linking sophisticated video encoders to LLMs. However, due to computation and data limitations, these Video-LLMs are typically pre-trained to process only short videos, limiting their broader application for understanding longer video content. Additionally, fine-tuning Video-LLMs to handle longer videos is cost-prohibitive. Consequently, it becomes essential to explore the interpolation of Video-LLMs under a completely training-free setting. In this paper, we first identify the primary challenges in interpolating Video-LLMs: (1) the video encoder and modality alignment projector are fixed, preventing the integration of additional frames into Video-LLMs, and (2) the LLM backbone is limited in its content length capabilities, which complicates the processing of an increased number of video tokens. To address these challenges, we propose a specific INTerPolation method for Video-LLMs (INTP-Video-LLMs). We introduce an alternative video token rearrangement technique that circumvents limitations imposed by the fixed video encoder and alignment projector. Furthermore, we introduce a training-free LLM context window extension method to enable Video-LLMs to understand a correspondingly increased number of visual tokens.
Read more10/3/2024
0
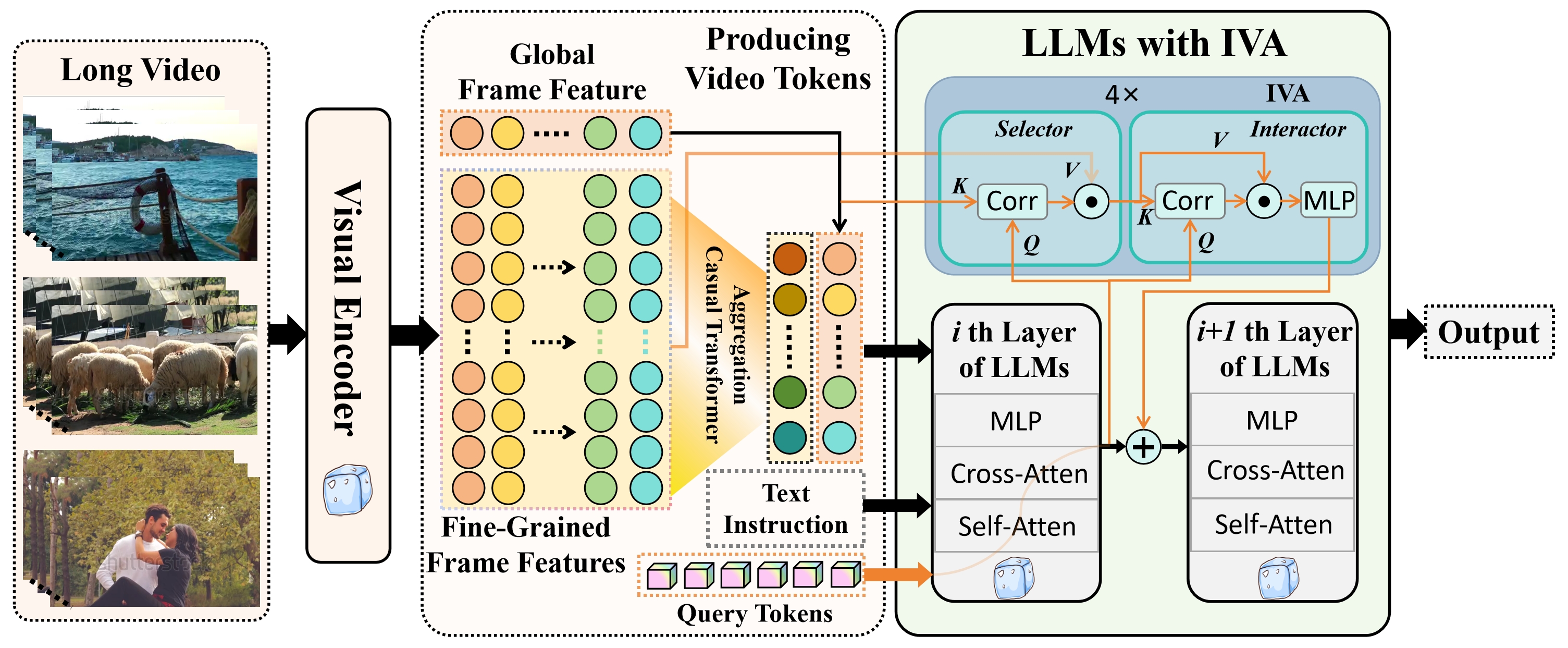
LLMs Meet Long Video: Advancing Long Video Question Answering with An Interactive Visual Adapter in LLMs
Yunxin Li, Xinyu Chen, Baotain Hu, Min Zhang
Long video understanding is a significant and ongoing challenge in the intersection of multimedia and artificial intelligence. Employing large language models (LLMs) for comprehending video becomes an emerging and promising method. However, this approach incurs high computational costs due to the extensive array of video tokens, experiences reduced visual clarity as a consequence of token aggregation, and confronts challenges arising from irrelevant visual tokens while answering video-related questions. To alleviate these issues, we present an Interactive Visual Adapter (IVA) within LLMs, designed to enhance interaction with fine-grained visual elements. Specifically, we first transform long videos into temporal video tokens via leveraging a visual encoder alongside a pretrained causal transformer, then feed them into LLMs with the video instructions. Subsequently, we integrated IVA, which contains a lightweight temporal frame selector and a spatial feature interactor, within the internal blocks of LLMs to capture instruction-aware and fine-grained visual signals. Consequently, the proposed video-LLM facilitates a comprehensive understanding of long video content through appropriate long video modeling and precise visual interactions. We conducted extensive experiments on nine video understanding benchmarks and experimental results show that our interactive visual adapter significantly improves the performance of video LLMs on long video QA tasks. Ablation studies further verify the effectiveness of IVA in understanding long and short video.
Read more8/27/2024
📊
0
Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization
Yang Jin, Zhicheng Sun, Kun Xu, Kun Xu, Liwei Chen, Hao Jiang, Quzhe Huang, Chengru Song, Yuliang Liu, Di Zhang, Yang Song, Kun Gai, Yadong Mu
In light of recent advances in multimodal Large Language Models (LLMs), there is increasing attention to scaling them from image-text data to more informative real-world videos. Compared to static images, video poses unique challenges for effective large-scale pre-training due to the modeling of its spatiotemporal dynamics. In this paper, we address such limitations in video-language pre-training with an efficient video decomposition that represents each video as keyframes and temporal motions. These are then adapted to an LLM using well-designed tokenizers that discretize visual and temporal information as a few tokens, thus enabling unified generative pre-training of videos, images, and text. At inference, the generated tokens from the LLM are carefully recovered to the original continuous pixel space to create various video content. Our proposed framework is both capable of comprehending and generating image and video content, as demonstrated by its competitive performance across 13 multimodal benchmarks in image and video understanding and generation. Our code and models are available at https://video-lavit.github.io.
Read more6/4/2024

0
VideoLLM-online: Online Video Large Language Model for Streaming Video
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, Mike Zheng Shou
Recent Large Language Models have been enhanced with vision capabilities, enabling them to comprehend images, videos, and interleaved vision-language content. However, the learning methods of these large multimodal models typically treat videos as predetermined clips, making them less effective and efficient at handling streaming video inputs. In this paper, we propose a novel Learning-In-Video-Stream (LIVE) framework, which enables temporally aligned, long-context, and real-time conversation within a continuous video stream. Our LIVE framework comprises comprehensive approaches to achieve video streaming dialogue, encompassing: (1) a training objective designed to perform language modeling for continuous streaming inputs, (2) a data generation scheme that converts offline temporal annotations into a streaming dialogue format, and (3) an optimized inference pipeline to speed up the model responses in real-world video streams. With our LIVE framework, we built VideoLLM-online model upon Llama-2/Llama-3 and demonstrate its significant advantages in processing streaming videos. For instance, on average, our model can support streaming dialogue in a 5-minute video clip at over 10 FPS on an A100 GPU. Moreover, it also showcases state-of-the-art performance on public offline video benchmarks, such as recognition, captioning, and forecasting. The code, model, data, and demo have been made available at https://showlab.github.io/videollm-online.
Read more6/18/2024