InterPreT: Interactive Predicate Learning from Language Feedback for Generalizable Task Planning

0
Sign in to get full access
Overview
- This paper introduces InterPreT, a system that allows users to interactively teach a robot new tasks by providing language-based feedback during planning and execution.
- The key idea is to learn interpretable predicates from language feedback, which can then be used to generalize task planning to new environments.
- The system is evaluated on a range of simulated and real-world robotic manipulation tasks, demonstrating its ability to learn new tasks quickly with minimal human input.
Plain English Explanation
The researchers have developed a system called InterPreT that allows people to teach robots new tasks by talking to them. Instead of just programming the robot to do a specific task, the system can learn new skills based on the feedback and instructions provided by the user during planning and execution.
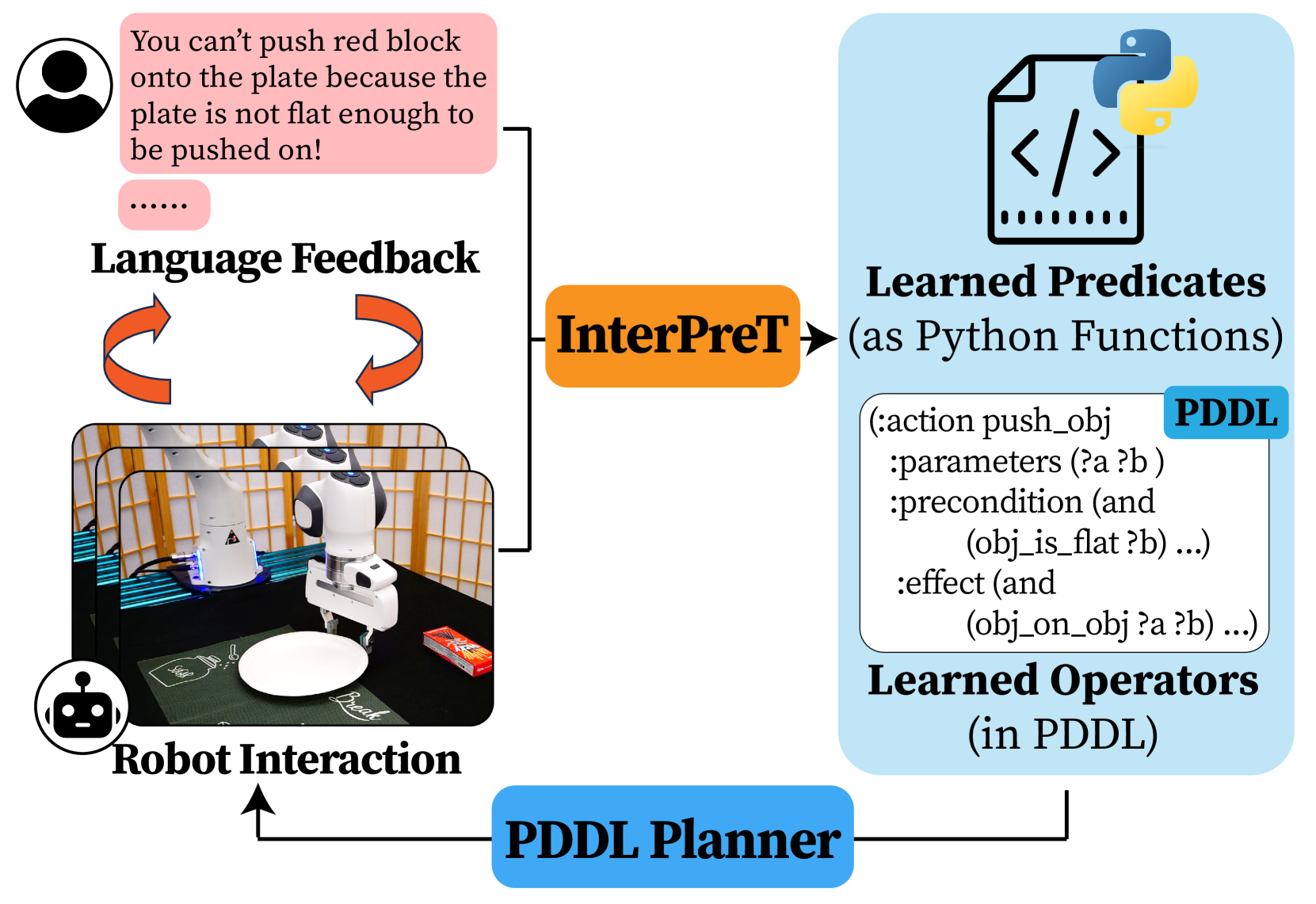
The core innovation is the way InterPreT learns "predicates" - logical statements that describe the state of the world - from the natural language feedback. These predicates can then be used by the robot to plan how to accomplish the new task, even in environments that are different from the one where it was originally trained.
For example, let's say you want to teach a robot how to set a table. You might give the robot feedback like "move the plate closer to the edge of the table" or "pick up the fork and place it to the right of the plate." InterPreT would learn predicates like "plate-near-edge" or "fork-right-of-plate" from this language, and use them to plan how to set the table in different dining rooms.
The researchers tested InterPreT on a variety of simulated and real-world robotic manipulation tasks, and found that it could learn new skills quickly with minimal human input. This suggests the approach could be a powerful way to make robots more flexible and adaptable, by allowing people to train them using natural language rather than just programming.
Technical Explanation
The key technical innovation in InterPreT is the way it learns interpretable predicates from natural language feedback provided by users during task planning and execution. These predicates capture logical statements about the state of the world, such as "plate-near-edge" or "fork-right-of-plate", and can be used by the robot's planner to generalize task completion to new environments.
The system operates in an interactive loop, where the user provides language feedback as the robot attempts to complete a task. InterPreT then uses this feedback to update a latent predicate representation, which is used to refine the robot's task plan. Over multiple iterations, the system learns a set of predicates that allow it to reliably complete the task.
Importantly, the learned predicates are
The authors evaluate InterPreT on a range of simulated and real-world robotic manipulation tasks, including block stacking, table setting, and object sorting. They find that the system can learn new tasks quickly, often after just a few iterations of feedback. Furthermore, the learned predicates enable the robot to generalize the task to novel environments, demonstrating the power of the interactive predicate learning approach.
Critical Analysis
The InterPreT system represents an exciting advance in interactive robot learning, allowing users to teach new tasks to robots using natural language feedback. The interpretability of the learned predicates is a particular strength, as it enhances the transparency and trust of the system.
That said, the evaluation is primarily focused on relatively simple manipulation tasks in controlled environments. It remains to be seen how well the approach would scale to more complex, real-world scenarios with greater uncertainty and variability. The authors acknowledge this as an area for future work, highlighting the need to improve the system's robustness and generalization capabilities.
Additionally, the current implementation of InterPreT assumes that the user's language feedback is unambiguous and directly maps to the underlying state of the world. In practice, human language is often more nuanced and context-dependent, which could pose challenges for the predicate learning process. Exploring techniques to handle ambiguous or incomplete language feedback would be a valuable direction for further research.
Overall, the InterPreT system represents an important step forward in the quest to create more flexible and adaptable robots that can learn from natural human interaction. By focusing on interpretable representations and interactive learning, the authors have laid the groundwork for future advancements in this area. As the field continues to evolve, it will be exciting to see how the ideas introduced in this paper are built upon and applied to increasingly complex robotic tasks.
Conclusion
The InterPreT system presented in this paper is a novel approach to robot learning that allows users to teach new tasks to robots using natural language feedback. By learning interpretable predicates from this feedback, the system can generalize task planning to new environments, demonstrating a powerful way to enhance the flexibility and adaptability of robotic systems.
The authors' evaluation of InterPreT on a range of simulated and real-world manipulation tasks is promising, showing that the system can learn new skills quickly with minimal human input. While there are still some challenges to address, such as scaling to more complex real-world scenarios, the core ideas introduced in this paper represent an important contribution to the field of interactive robot learning.
As the demand for more capable and user-friendly robots continues to grow, systems like InterPreT that can learn from natural human interaction will become increasingly valuable. The ability to teach robots new skills through language-based feedback, rather than just programming, has the potential to revolutionize how we interact with and deploy robotic technologies in our homes, workplaces, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
InterPreT: Interactive Predicate Learning from Language Feedback for Generalizable Task Planning
Muzhi Han, Yifeng Zhu, Song-Chun Zhu, Ying Nian Wu, Yuke Zhu
Learning abstract state representations and knowledge is crucial for long-horizon robot planning. We present InterPreT, an LLM-powered framework for robots to learn symbolic predicates from language feedback of human non-experts during embodied interaction. The learned predicates provide relational abstractions of the environment state, facilitating the learning of symbolic operators that capture action preconditions and effects. By compiling the learned predicates and operators into a PDDL domain on-the-fly, InterPreT allows effective planning toward arbitrary in-domain goals using a PDDL planner. In both simulated and real-world robot manipulation domains, we demonstrate that InterPreT reliably uncovers the key predicates and operators governing the environment dynamics. Although learned from simple training tasks, these predicates and operators exhibit strong generalization to novel tasks with significantly higher complexity. In the most challenging generalization setting, InterPreT attains success rates of 73% in simulation and 40% in the real world, substantially outperforming baseline methods.
Read more5/31/2024

0
Learning Planning Abstractions from Language
Weiyu Liu, Geng Chen, Joy Hsu, Jiayuan Mao, Jiajun Wu
This paper presents a framework for learning state and action abstractions in sequential decision-making domains. Our framework, planning abstraction from language (PARL), utilizes language-annotated demonstrations to automatically discover a symbolic and abstract action space and induce a latent state abstraction based on it. PARL consists of three stages: 1) recovering object-level and action concepts, 2) learning state abstractions, abstract action feasibility, and transition models, and 3) applying low-level policies for abstract actions. During inference, given the task description, PARL first makes abstract action plans using the latent transition and feasibility functions, then refines the high-level plan using low-level policies. PARL generalizes across scenarios involving novel object instances and environments, unseen concept compositions, and tasks that require longer planning horizons than settings it is trained on.
Read more5/8/2024
💬
0
A Framework for Neurosymbolic Robot Action Planning using Large Language Models
Alessio Capitanelli, Fulvio Mastrogiovanni
Symbolic task planning is a widely used approach to enforce robot autonomy due to its ease of understanding and deployment in robot architectures. However, techniques for symbolic task planning are difficult to scale in real-world, human-robot collaboration scenarios because of the poor performance in complex planning domains or when frequent re-planning is needed. We present a framework, Teriyaki, specifically aimed at bridging the gap between symbolic task planning and machine learning approaches. The rationale is training Large Language Models (LLMs), namely GPT-3, into a neurosymbolic task planner compatible with the Planning Domain Definition Language (PDDL), and then leveraging its generative capabilities to overcome a number of limitations inherent to symbolic task planners. Potential benefits include (i) a better scalability in so far as the planning domain complexity increases, since LLMs' response time linearly scales with the combined length of the input and the output, and (ii) the ability to synthesize a plan action-by-action instead of end-to-end, making each action available for execution as soon as it is generated instead of waiting for the whole plan to be available, which in turn enables concurrent planning and execution. Recently, significant efforts have been devoted by the research community to evaluate the cognitive capabilities of LLMs, with alternate successes. Instead, with Teriyaki we aim to provide an overall planning performance comparable to traditional planners in specific planning domains, while leveraging LLMs capabilities to build a look-ahead predictive planning model. Preliminary results in selected domains show that our method can: (i) solve 95.5% of problems in a test data set of 1,000 samples; (ii) produce plans up to 13.5% shorter than a traditional symbolic planner; (iii) reduce average overall waiting times for a plan availability by up to 61.4%
Read more6/5/2024
🖼️
0
TIC: Translate-Infer-Compile for accurate text to plan using LLMs and Logical Representations
Sudhir Agarwal, Anu Sreepathy
We study the problem of generating plans for given natural language planning task requests. On one hand, LLMs excel at natural language processing but do not perform well on planning. On the other hand, classical planning tools excel at planning tasks but require input in a structured language such as the Planning Domain Definition Language (PDDL). We leverage the strengths of both the techniques by using an LLM for generating the PDDL representation (task PDDL) of planning task requests followed by using a classical planner for computing a plan. Unlike previous approaches that use LLMs for generating task PDDLs directly, our approach comprises of (a) translate: using an LLM only for generating a logically interpretable intermediate representation of natural language task description, (b) infer: deriving additional logically dependent information from the intermediate representation using a logic reasoner (currently, Answer Set Programming solver), and (c) compile: generating the target task PDDL from the base and inferred information. We observe that using an LLM to only output the intermediate representation significantly reduces LLM errors. Consequently, TIC approach achieves, for at least one LLM, high accuracy on task PDDL generation for all seven domains of our evaluation dataset.
Read more7/2/2024