Interpretable global minima of deep ReLU neural networks on sequentially separable data

0
🤿
Sign in to get full access
Overview
- Researchers propose a method for constructing zero-loss neural network classifiers.
- The weight matrices and bias vectors are written in terms of cumulative parameters, which determine truncation maps acting recursively on the input space.
- The training data configurations considered are: (i) sufficiently small, well-separated clusters corresponding to each class, and (ii) equivalence classes which are sequentially linearly separable.
- In the best case, for
$Q$classes of data in$\mathbb{R}^M$, global minimizers can be described with$Q(M+2)$parameters.
Plain English Explanation
The researchers have developed a new way to create neural network classifiers that can perfectly classify the training data without any errors or loss. They do this by representing the neural network's weights and biases using a set of cumulative parameters that define how the network maps the input space onto the classes.
The training data they consider has two key properties: [1] the data for each class is contained in small, well-separated clusters, and [2] the classes can be sequentially separated by linear boundaries. In the best-case scenario, where there are $Q$ classes in an $M$-dimensional input space, the entire neural network can be described using only $Q(M+2)$ parameters.
This is an important result because it shows that under certain conditions, neural networks can learn very compact and efficient representations of the training data that allow for perfect classification. This could lead to smaller, faster, and more interpretable neural network models.
Technical Explanation
The researchers explicitly construct zero-loss neural network classifiers by writing the weight matrices and bias vectors in terms of cumulative parameters. These cumulative parameters determine truncation maps that act recursively on the input space to separate the data into the target classes.
The two training data configurations considered are: [1] sufficiently small, well-separated clusters corresponding to each class, and [2] equivalence classes which are sequentially linearly separable. In the best case, for $Q$ classes of data in $\mathbb{R}^M$, the global minimizers of the classification problem can be described using only $Q(M+2)$ parameters.
This result demonstrates that under certain conditions, neural networks can learn extremely compact representations of the training data that allow for perfect classification. This relates to other work on three quantization regimes for ReLU networks, regularized gradient clipping, and convergence rates for learning convolutional neural networks.
Critical Analysis
The paper provides an interesting theoretical result showing that under specific assumptions about the training data, neural networks can learn highly compact representations that allow for perfect classification. However, the practical applicability of this result may be limited, as the assumptions - such as well-separated, linearly separable clusters - may not hold for many real-world datasets.
Additionally, the paper does not address how to actually find these compact representations in practice, nor does it consider the implications for training deep neural networks for classification tasks. Further research would be needed to understand how this theoretical result translates to more complex, high-dimensional datasets and architectural choices.
Conclusion
This paper presents a novel technique for constructing zero-loss neural network classifiers by representing the network's weights and biases using a small set of cumulative parameters. Under certain assumptions about the training data, the researchers show that the global minimizers of the classification problem can be described using a surprisingly small number of parameters.
While this is an interesting theoretical result, its practical implications may be limited, as the required assumptions about the data may not hold in many real-world scenarios. Additional research is needed to understand how this technique can be applied to more complex classification tasks and datasets. Nevertheless, this work contributes to our understanding of the fundamental capabilities and limitations of neural networks for learning compact representations of data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Interpretable global minima of deep ReLU neural networks on sequentially separable data
Thomas Chen, Patricia Mu~noz Ewald
We explicitly construct zero loss neural network classifiers. We write the weight matrices and bias vectors in terms of cumulative parameters, which determine truncation maps acting recursively on input space. The configurations for the training data considered are (i) sufficiently small, well separated clusters corresponding to each class, and (ii) equivalence classes which are sequentially linearly separable. In the best case, for $Q$ classes of data in $mathbb{R}^M$, global minimizers can be described with $Q(M+2)$ parameters.
Read more9/18/2024
0
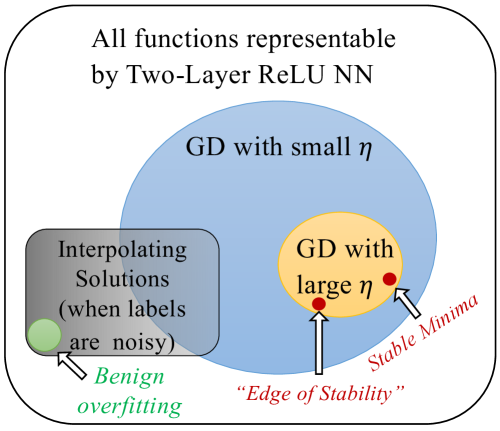
Stable Minima Cannot Overfit in Univariate ReLU Networks: Generalization by Large Step Sizes
Dan Qiao, Kaiqi Zhang, Esha Singh, Daniel Soudry, Yu-Xiang Wang
We study the generalization of two-layer ReLU neural networks in a univariate nonparametric regression problem with noisy labels. This is a problem where kernels (emph{e.g.} NTK) are provably sub-optimal and benign overfitting does not happen, thus disqualifying existing theory for interpolating (0-loss, global optimal) solutions. We present a new theory of generalization for local minima that gradient descent with a constant learning rate can emph{stably} converge to. We show that gradient descent with a fixed learning rate $eta$ can only find local minima that represent smooth functions with a certain weighted emph{first order total variation} bounded by $1/eta - 1/2 + widetilde{O}(sigma + sqrt{mathrm{MSE}})$ where $sigma$ is the label noise level, $mathrm{MSE}$ is short for mean squared error against the ground truth, and $widetilde{O}(cdot)$ hides a logarithmic factor. Under mild assumptions, we also prove a nearly-optimal MSE bound of $widetilde{O}(n^{-4/5})$ within the strict interior of the support of the $n$ data points. Our theoretical results are validated by extensive simulation that demonstrates large learning rate training induces sparse linear spline fits. To the best of our knowledge, we are the first to obtain generalization bound via minima stability in the non-interpolation case and the first to show ReLU NNs without regularization can achieve near-optimal rates in nonparametric regression.
Read more6/12/2024
↗️
0
Nonparametric regression using over-parameterized shallow ReLU neural networks
Yunfei Yang, Ding-Xuan Zhou
It is shown that over-parameterized neural networks can achieve minimax optimal rates of convergence (up to logarithmic factors) for learning functions from certain smooth function classes, if the weights are suitably constrained or regularized. Specifically, we consider the nonparametric regression of estimating an unknown $d$-variate function by using shallow ReLU neural networks. It is assumed that the regression function is from the Holder space with smoothness $alpha<(d+3)/2$ or a variation space corresponding to shallow neural networks, which can be viewed as an infinitely wide neural network. In this setting, we prove that least squares estimators based on shallow neural networks with certain norm constraints on the weights are minimax optimal, if the network width is sufficiently large. As a byproduct, we derive a new size-independent bound for the local Rademacher complexity of shallow ReLU neural networks, which may be of independent interest.
Read more5/16/2024
🧠
0
Local Recovery of Two-layer Neural Networks at Overparameterization
Leyang Zhang, Yaoyu Zhang, Tao Luo
Under mild assumptions, we investigate the geometry of the loss landscape for two-layer neural networks in the vicinity of global minima. Utilizing novel techniques, we demonstrate: (i) how global minima with zero generalization error become geometrically separated from other global minima as the sample size grows; and (ii) the local convergence properties and rate of gradient flow dynamics. Our results indicate that two-layer neural networks can be locally recovered in the regime of overparameterization.
Read more7/19/2024