Interpreting Answers to Yes-No Questions in Dialogues from Multiple Domains

0
🔄
Sign in to get full access
Overview
- The paper provides instructions for authors submitting papers to *ACL (Association for Computational Linguistics) conferences and journals.
- It covers topics such as the required document engines, preamble settings, formatting guidelines, and submission process.
- The instructions aim to ensure consistent formatting and presentation of papers across *ACL publications.
Plain English Explanation
If you're planning to submit a paper to an *ACL (Association for Computational Linguistics) conference or journal, this document outlines the specific guidelines and requirements you need to follow. It covers the technical details, like the document engines and preamble settings you should use, as well as formatting rules for things like page layout, font sizes, and citation styles.
The goal of these instructions is to create a standardized look and feel across all *ACL publications, making it easier for readers to navigate and understand the papers. By following these guidelines, you can ensure your submission will be properly formatted and presented, giving your research the best chance of being accepted and having an impact.
Technical Explanation
The paper begins by introducing the *ACL proceedings and the need for consistent formatting guidelines. It then covers the required document engines, such as LaTeX, that authors must use to prepare their submissions.
The preamble section outlines the necessary settings and packages that should be included in the LaTeX document to ensure proper formatting. This includes specifying the document class, loading required packages, and defining custom macros or commands.
The instructions also provide detailed guidance on formatting elements like page layout, font sizes, and citation styles. For example, papers must use a two-column format with specific margins and font sizes for the main text, section headings, and captions.
The submission process is also described, including information on how to generate the final PDF file and upload it to the conference or journal's submission system.
Critical Analysis
The instructions provide a comprehensive and well-documented set of guidelines for authors submitting to *ACL publications. By enforcing consistent formatting, the instructions help maintain the high quality and readability of the proceedings, which is crucial for the dissemination of research in the field of computational linguistics.
However, the instructions do not address potential issues that may arise, such as the challenges authors may face in adhering to the strict formatting rules, particularly if they are new to LaTeX or academic publishing. The instructions could be enhanced by providing more guidance or examples to help authors navigate the technical requirements.
Additionally, the instructions do not discuss the rationale behind some of the formatting choices, which could be useful for authors to understand the underlying principles and make informed decisions about any necessary deviations from the guidelines.
Conclusion
The instructions for *ACL proceedings provide a clear and detailed set of guidelines for authors to follow when preparing their submissions. By enforcing consistent formatting, the instructions help maintain the high quality and readability of the publications, which is crucial for the effective dissemination of research in the field of computational linguistics.
While the instructions are comprehensive, they could be further improved by addressing potential challenges authors may face and providing more context on the reasoning behind the formatting choices. Overall, these guidelines play an essential role in ensuring the professional presentation and impact of *ACL publications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Interpreting Answers to Yes-No Questions in Dialogues from Multiple Domains
Zijie Wang, Farzana Rashid, Eduardo Blanco
People often answer yes-no questions without explicitly saying yes, no, or similar polar keywords. Figuring out the meaning of indirect answers is challenging, even for large language models. In this paper, we investigate this problem working with dialogues from multiple domains. We present new benchmarks in three diverse domains: movie scripts, tennis interviews, and airline customer service. We present an approach grounded on distant supervision and blended training to quickly adapt to a new dialogue domain. Experimental results show that our approach is never detrimental and yields F1 improvements as high as 11-34%.
Read more4/26/2024

0
STYLE: Improving Domain Transferability of Asking Clarification Questions in Large Language Model Powered Conversational Agents
Yue Chen, Chen Huang, Yang Deng, Wenqiang Lei, Dingnan Jin, Jia Liu, Tat-Seng Chua
Equipping a conversational search engine with strategies regarding when to ask clarification questions is becoming increasingly important across various domains. Attributing to the context understanding capability of LLMs and their access to domain-specific sources of knowledge, LLM-based clarification strategies feature rapid transfer to various domains in a post-hoc manner. However, they still struggle to deliver promising performance on unseen domains, struggling to achieve effective domain transferability. We take the first step to investigate this issue and existing methods tend to produce one-size-fits-all strategies across diverse domains, limiting their search effectiveness. In response, we introduce a novel method, called Style, to achieve effective domain transferability. Our experimental results indicate that Style bears strong domain transferability, resulting in an average search performance improvement of ~10% on four unseen domains.
Read more6/4/2024
0
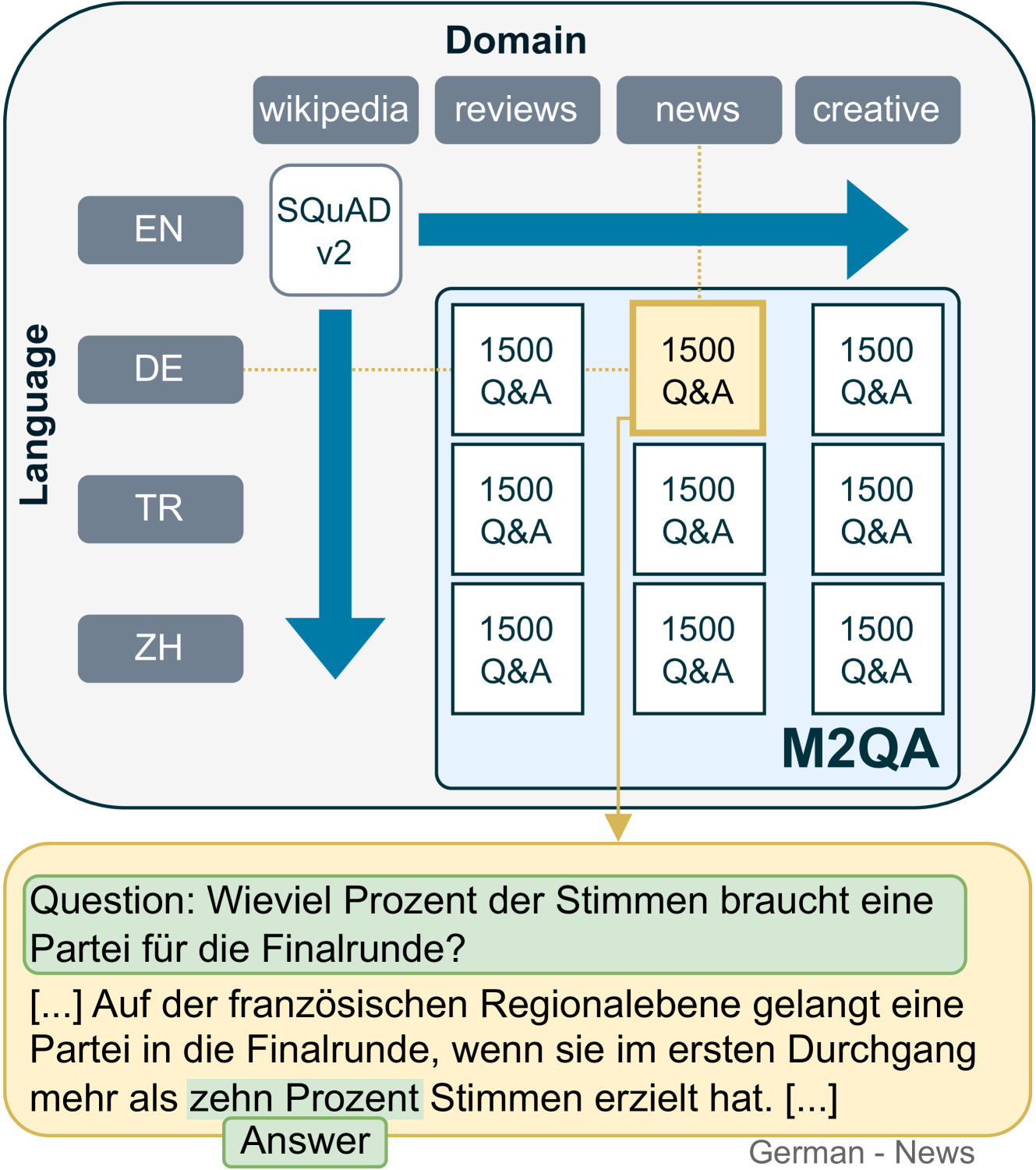
M2QA: Multi-domain Multilingual Question Answering
Leon Englander, Hannah Sterz, Clifton Poth, Jonas Pfeiffer, Ilia Kuznetsov, Iryna Gurevych
Generalization and robustness to input variation are core desiderata of machine learning research. Language varies along several axes, most importantly, language instance (e.g. French) and domain (e.g. news). While adapting NLP models to new languages within a single domain, or to new domains within a single language, is widely studied, research in joint adaptation is hampered by the lack of evaluation datasets. This prevents the transfer of NLP systems from well-resourced languages and domains to non-dominant language-domain combinations. To address this gap, we introduce M2QA, a multi-domain multilingual question answering benchmark. M2QA includes 13,500 SQuAD 2.0-style question-answer instances in German, Turkish, and Chinese for the domains of product reviews, news, and creative writing. We use M2QA to explore cross-lingual cross-domain performance of fine-tuned models and state-of-the-art LLMs and investigate modular approaches to domain and language adaptation. We witness 1) considerable performance variations across domain-language combinations within model classes and 2) considerable performance drops between source and target language-domain combinations across all model sizes. We demonstrate that M2QA is far from solved, and new methods to effectively transfer both linguistic and domain-specific information are necessary. We make M2QA publicly available at https://github.com/UKPLab/m2qa.
Read more7/2/2024
🔍
0
Narrowing the Knowledge Evaluation Gap: Open-Domain Question Answering with Multi-Granularity Answers
Gal Yona, Roee Aharoni, Mor Geva
Factual questions typically can be answered correctly at different levels of granularity. For example, both ``August 4, 1961'' and ``1961'' are correct answers to the question ``When was Barack Obama born?''. Standard question answering (QA) evaluation protocols, however, do not explicitly take this into account and compare a predicted answer against answers of a single granularity level. In this work, we propose GRANOLA QA, a novel evaluation setting where a predicted answer is evaluated in terms of accuracy and informativeness against a set of multi-granularity answers. We present a simple methodology for enriching existing datasets with multi-granularity answers, and create GRANOLA-EQ, a multi-granularity version of the EntityQuestions dataset. We evaluate a range of decoding methods on GRANOLA-EQ, including a new algorithm, called Decoding with Response Aggregation (DRAG), that is geared towards aligning the response granularity with the model's uncertainty. Our experiments show that large language models with standard decoding tend to generate specific answers, which are often incorrect. In contrast, when evaluated on multi-granularity answers, DRAG yields a nearly 20 point increase in accuracy on average, which further increases for rare entities. Overall, this reveals that standard evaluation and decoding schemes may significantly underestimate the knowledge encapsulated in LMs.
Read more8/2/2024