M2QA: Multi-domain Multilingual Question Answering
2407.01091
0
0
Abstract
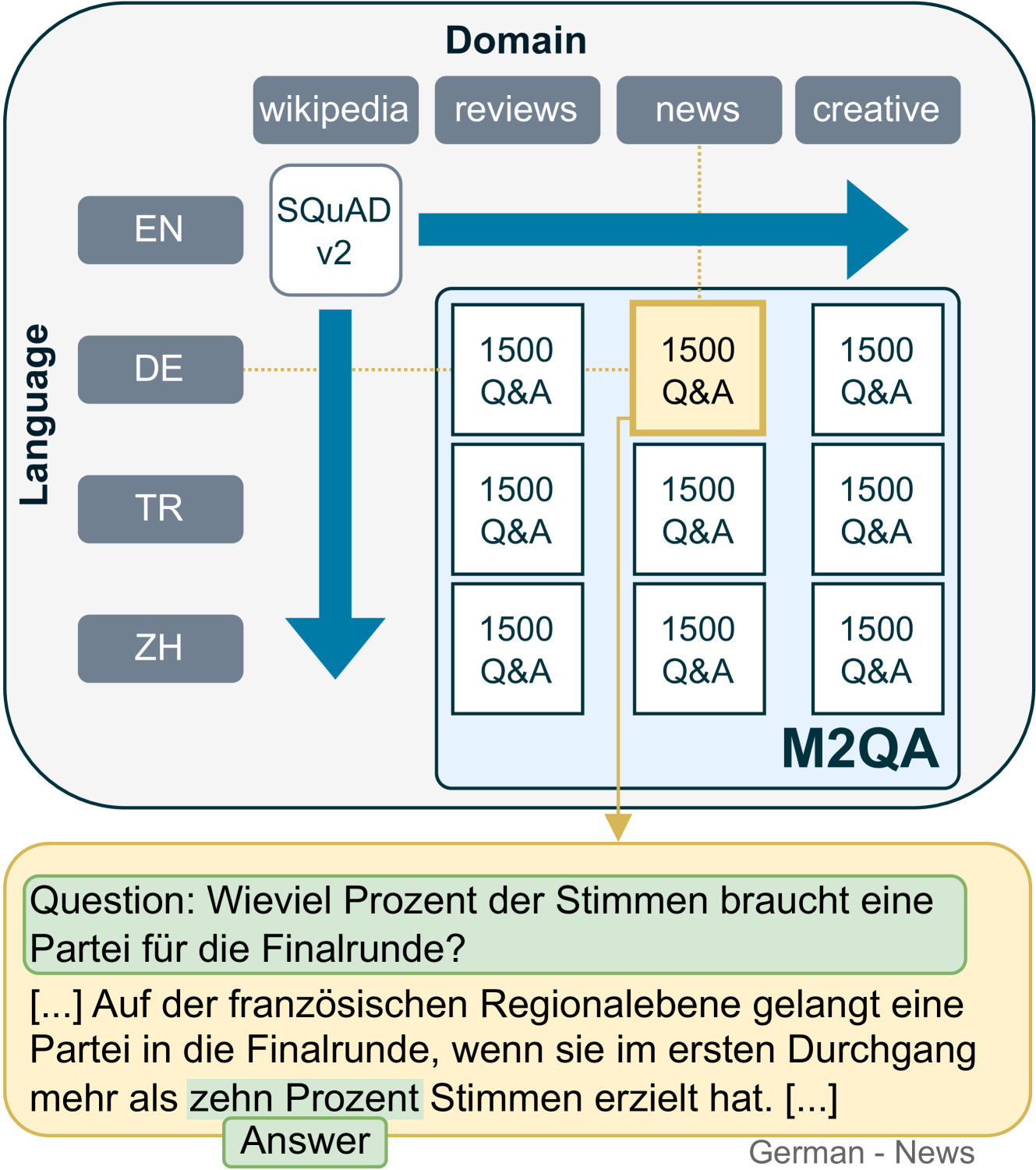
Generalization and robustness to input variation are core desiderata of machine learning research. Language varies along several axes, most importantly, language instance (e.g. French) and domain (e.g. news). While adapting NLP models to new languages within a single domain, or to new domains within a single language, is widely studied, research in joint adaptation is hampered by the lack of evaluation datasets. This prevents the transfer of NLP systems from well-resourced languages and domains to non-dominant language-domain combinations. To address this gap, we introduce M2QA, a multi-domain multilingual question answering benchmark. M2QA includes 13,500 SQuAD 2.0-style question-answer instances in German, Turkish, and Chinese for the domains of product reviews, news, and creative writing. We use M2QA to explore cross-lingual cross-domain performance of fine-tuned models and state-of-the-art LLMs and investigate modular approaches to domain and language adaptation. We witness 1) considerable performance variations across domain-language combinations within model classes and 2) considerable performance drops between source and target language-domain combinations across all model sizes. We demonstrate that M2QA is far from solved, and new methods to effectively transfer both linguistic and domain-specific information are necessary. We make M2QA publicly available at https://github.com/UKPLab/m2qa.
Create account to get full access
Overview
- This paper introduces M2QA, a multi-domain, multilingual question answering dataset and benchmark.
- M2QA covers a diverse range of topics, including science, history, current events, and more, in 11 languages.
- The goal is to develop models that can accurately answer questions across multiple domains and languages, a challenging task that has important real-world applications.
Plain English Explanation
M2QA is a new dataset that aims to advance the field of multilingual question answering. Question answering systems are AI models that can understand questions posed in natural language and provide accurate answers. Typically, these models are trained on data in a single language and domain, like answering questions about science or history in English.
However, real-world applications require models that can handle questions across many different topics and languages. M2QA provides a benchmark to evaluate models on this more realistic and challenging task. The dataset includes questions in 11 languages, covering a diverse range of subjects like current events, arts and culture, and more.
By developing models that can excel on the M2QA benchmark, researchers can work towards building question answering assistants that are truly multilingual and multi-domain. These types of AI systems could have many practical applications, like helping people find information in their preferred language, or providing knowledgeable answers to a wide variety of questions.
Technical Explanation
The M2QA dataset was created by crawling and curating question-answer pairs from various web sources in 11 languages, including English, Russian, Hindi, and Urdu. The questions span a wide range of topics, from science and history to current events and arts and culture.
The authors evaluated several state-of-the-art multilingual question answering models on the M2QA benchmark. They found that while these models performed reasonably well on average, there was significant room for improvement, especially for lower-resource languages and more specialized domains.
To address this, the authors propose a novel model architecture that leverages both language-specific and language-agnostic components. This allows the model to better capture the nuances of each language while also learning cross-lingual representations that aid in transferring knowledge across languages.
The authors' experimental results demonstrate the effectiveness of this approach, with their model outperforming previous multilingual QA systems on the M2QA benchmark. They also provide detailed analyses of the model's strengths and weaknesses, highlighting areas for future research and development.
Critical Analysis
The M2QA dataset and benchmark represent an important step forward in the field of multilingual question answering. By focusing on a diverse range of languages and domains, the authors have created a more realistic and challenging evaluation framework than previous work.
However, the dataset is not without limitations. The authors acknowledge that the quality and coverage of the questions may vary across languages, with lower-resource languages potentially having fewer high-quality examples. This could make it more difficult for models to learn effective representations for these languages.
Additionally, the dataset does not include any audio or visual information, which could be an important modality for certain types of questions, such as those related to audiovisual content. Extending the M2QA benchmark to include multimodal inputs could be a fruitful area for future research.
Overall, the M2QA dataset and the authors' proposed model represent a significant advancement in the field of multilingual question answering. By fostering further research and development in this area, the work has the potential to enable more accessible and versatile AI-powered information assistants.
Conclusion
The M2QA dataset and benchmark introduced in this paper address an important challenge in artificial intelligence: building question answering systems that can operate effectively across multiple languages and domains. By curating a diverse set of questions in 11 languages, the authors have created a valuable resource for evaluating the capabilities of multilingual QA models.
The authors' proposed model architecture, which combines language-specific and language-agnostic components, demonstrates the potential for significant improvements over existing multilingual QA systems. As research in this area continues to progress, the development of truly multilingual and multi-domain question answering assistants could have far-reaching implications, from enabling more inclusive access to information to supporting a wide range of practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
mCSQA: Multilingual Commonsense Reasoning Dataset with Unified Creation Strategy by Language Models and Humans
Yusuke Sakai, Hidetaka Kamigaito, Taro Watanabe
0
0
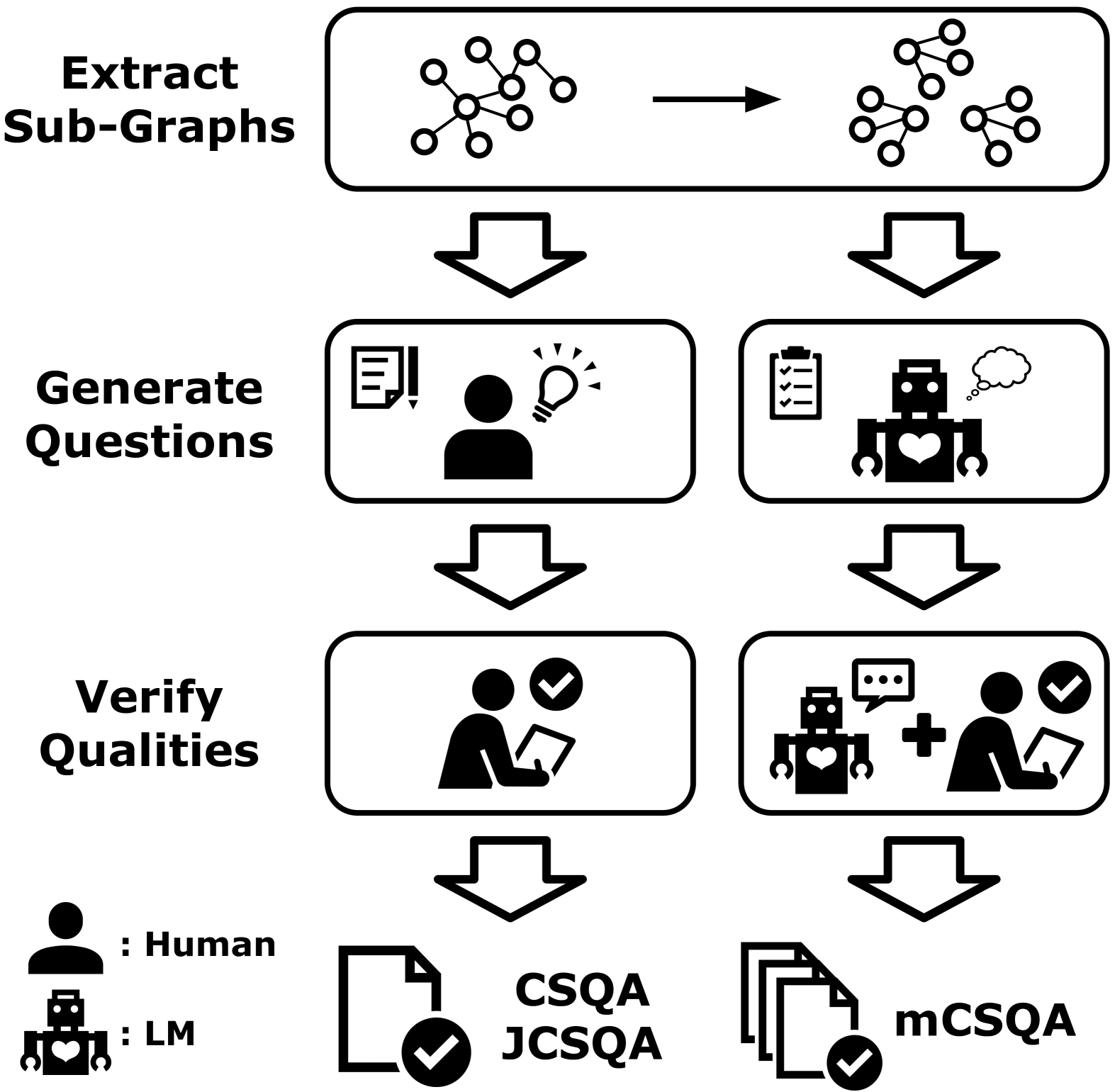
It is very challenging to curate a dataset for language-specific knowledge and common sense in order to evaluate natural language understanding capabilities of language models. Due to the limitation in the availability of annotators, most current multilingual datasets are created through translation, which cannot evaluate such language-specific aspects. Therefore, we propose Multilingual CommonsenseQA (mCSQA) based on the construction process of CSQA but leveraging language models for a more efficient construction, e.g., by asking LM to generate questions/answers, refine answers and verify QAs followed by reduced human efforts for verification. Constructed dataset is a benchmark for cross-lingual language-transfer capabilities of multilingual LMs, and experimental results showed high language-transfer capabilities for questions that LMs could easily solve, but lower transfer capabilities for questions requiring deep knowledge or commonsense. This highlights the necessity of language-specific datasets for evaluation and training. Finally, our method demonstrated that multilingual LMs could create QA including language-specific knowledge, significantly reducing the dataset creation cost compared to manual creation. The datasets are available at https://huggingface.co/datasets/yusuke1997/mCSQA.
6/7/2024
↗️
UQA: Corpus for Urdu Question Answering
Samee Arif, Sualeha Farid, Awais Athar, Agha Ali Raza
0
0
This paper introduces UQA, a novel dataset for question answering and text comprehension in Urdu, a low-resource language with over 70 million native speakers. UQA is generated by translating the Stanford Question Answering Dataset (SQuAD2.0), a large-scale English QA dataset, using a technique called EATS (Enclose to Anchor, Translate, Seek), which preserves the answer spans in the translated context paragraphs. The paper describes the process of selecting and evaluating the best translation model among two candidates: Google Translator and Seamless M4T. The paper also benchmarks several state-of-the-art multilingual QA models on UQA, including mBERT, XLM-RoBERTa, and mT5, and reports promising results. For XLM-RoBERTa-XL, we have an F1 score of 85.99 and 74.56 EM. UQA is a valuable resource for developing and testing multilingual NLP systems for Urdu and for enhancing the cross-lingual transferability of existing models. Further, the paper demonstrates the effectiveness of EATS for creating high-quality datasets for other languages and domains. The UQA dataset and the code are publicly available at www.github.com/sameearif/UQA.
5/3/2024
Pre-training Cross-lingual Open Domain Question Answering with Large-scale Synthetic Supervision
Fan Jiang, Tom Drummond, Trevor Cohn
0
0
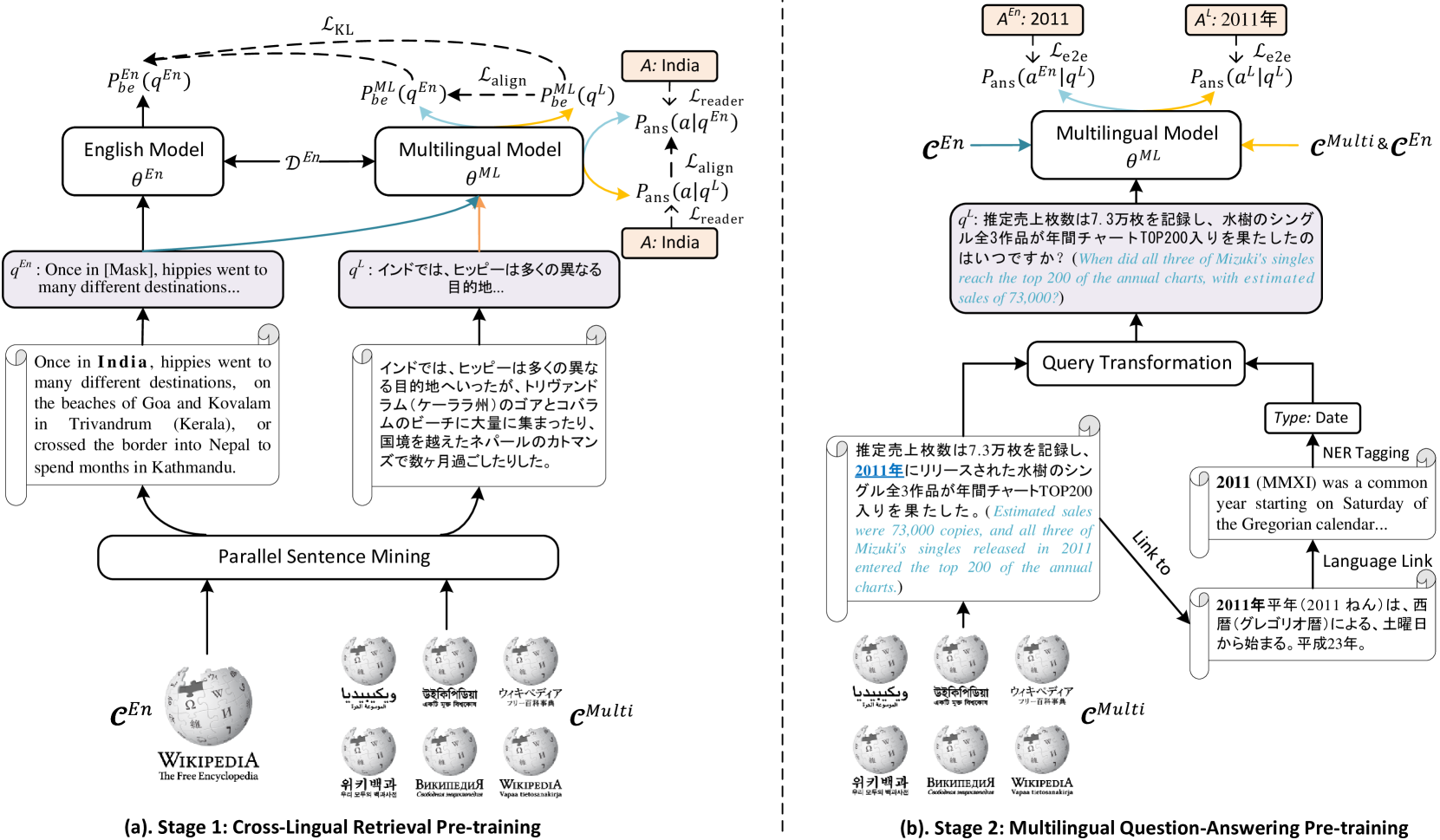
Cross-lingual open domain question answering (CLQA) is a complex problem, comprising cross-lingual retrieval from a multilingual knowledge base, followed by answer generation in the query language. Both steps are usually tackled by separate models, requiring substantial annotated datasets, and typically auxiliary resources, like machine translation systems to bridge between languages. In this paper, we show that CLQA can be addressed using a single encoder-decoder model. To effectively train this model, we propose a self-supervised method based on exploiting the cross-lingual link structure within Wikipedia. We demonstrate how linked Wikipedia pages can be used to synthesise supervisory signals for cross-lingual retrieval, through a form of cloze query, and generate more natural questions to supervise answer generation. Together, we show our approach, texttt{CLASS}, outperforms comparable methods on both supervised and zero-shot language adaptation settings, including those using machine translation.
6/18/2024

GeMQuAD : Generating Multilingual Question Answering Datasets from Large Language Models using Few Shot Learning
Amani Namboori, Shivam Mangale, Andy Rosenbaum, Saleh Soltan
0
0
The emergence of Large Language Models (LLMs) with capabilities like In-Context Learning (ICL) has ushered in new possibilities for data generation across various domains while minimizing the need for extensive data collection and modeling techniques. Researchers have explored ways to use this generated synthetic data to optimize smaller student models for reduced deployment costs and lower latency in downstream tasks. However, ICL-generated data often suffers from low quality as the task specificity is limited with few examples used in ICL. In this paper, we propose GeMQuAD - a semi-supervised learning approach, extending the WeakDAP framework, applied to a dataset generated through ICL with just one example in the target language using AlexaTM 20B Seq2Seq LLM. Through our approach, we iteratively identify high-quality data to enhance model performance, especially for low-resource multilingual setting in the context of Extractive Question Answering task. Our framework outperforms the machine translation-augmented model by 0.22/1.68 F1/EM (Exact Match) points for Hindi and 0.82/1.37 F1/EM points for Spanish on the MLQA dataset, and it surpasses the performance of model trained on an English-only dataset by 5.05/6.50 F1/EM points for Hindi and 3.81/3.69 points F1/EM for Spanish on the same dataset. Notably, our approach uses a pre-trained LLM for generation with no fine-tuning (FT), utilizing just a single annotated example in ICL to generate data, providing a cost-effective development process.
4/16/2024