STYLE: Improving Domain Transferability of Asking Clarification Questions in Large Language Model Powered Conversational Agents

0

Sign in to get full access
Overview
- This paper explores improving the domain transferability of asking clarification questions in large language model (LLM) powered conversational agents.
- The researchers conducted experiments to investigate different approaches for enhancing the ability of LLMs to ask relevant clarification questions across diverse domains.
- The goal is to make conversational agents more capable of handling ambiguous or incomplete user inputs by proactively seeking clarification, which can improve the overall quality of the interaction.
Plain English Explanation
Conversational AI systems, such as chatbots and virtual assistants, often struggle to understand complex or ambiguous user queries, especially when they involve topics outside the system's training data. This paper explores ways to improve these systems' ability to ask clarifying questions when they're unsure about what the user is asking.
The researchers tested different techniques to help large language models (LLMs), the powerful AI systems that power many conversational agents, become better at recognizing when they need more information and then formulating appropriate clarifying questions. This is similar to the approach used in the Power of Question Translation paper, which focused on improving question-asking in a multilingual context.
By enabling conversational agents to proactively seek clarification, the researchers aim to make these systems more robust and capable of handling a wider range of user queries, even in domains they weren't specifically trained for. This builds on work on interpreting answers to yes/no questions and enhancing QA systems through domain-specific fine-tuning.
The ultimate goal is to create conversational AI that can engage in more natural, human-like dialogs by being able to identify when they need more information and then asking the right clarifying questions to better understand the user's intent. This could significantly improve the overall user experience and the effectiveness of conversational AI systems.
Technical Explanation
The researchers conducted a series of experiments to investigate different approaches for improving the domain transferability of asking clarification questions in LLM-powered conversational agents.
One key aspect of their approach was to fine-tune the LLMs on a dataset of human-human conversations, where the goal was to learn patterns of when and how humans ask clarifying questions. The researchers hypothesized that by exposing the models to these natural examples of clarification-seeking behavior, they would be better able to recognize situations where clarification is needed and generate appropriate follow-up questions.
Additionally, the researchers experimented with incorporating external knowledge sources, such as domain-specific ontologies or databases, to provide the LLMs with a richer contextual understanding of the conversational domain. This was intended to help the models better identify relevant information gaps and formulate more targeted clarification questions.
The researchers also explored techniques for explicitly training the LLMs to recognize when their confidence in responding to a user query is low, and to then generate clarification questions proactively rather than attempting to provide a potentially inaccurate response.
Through these various experimental approaches, the researchers aimed to develop conversational agents that can more effectively engage in a dialog with users by actively seeking clarification when needed, rather than simply providing a best-guess response that may miss the mark.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in this work. For example, they note that the effectiveness of their approaches may be highly dependent on the specific domain and the quality of the training data used for fine-tuning the LLMs.
Additionally, the researchers highlight the challenge of scaling these techniques to handle the wide range of topics and contexts that modern conversational agents are expected to cover. Developing a truly "universal" clarification-seeking capability that can adapt to any domain may require more advanced few-shot or meta-learning techniques.
Another potential issue is the potential for these clarification-seeking mechanisms to become overly intrusive or disruptive to the user experience, if not implemented carefully. The researchers emphasize the need to strike the right balance between proactively seeking clarification and maintaining a natural, conversational flow.
Further research may also be needed to understand how users perceive and respond to clarification questions from conversational agents, and how to optimize the phrasing and timing of these questions to maximize their effectiveness.
Overall, while this work represents an important step forward in enhancing the capabilities of conversational AI, there are still significant challenges to be addressed before these systems can truly match the nuanced, context-aware clarification-seeking behaviors of humans.
Conclusion
This paper presents an experimental investigation into improving the domain transferability of asking clarification questions in large language model-powered conversational agents. The researchers explored various techniques, including fine-tuning on human-human dialog data and incorporating external knowledge sources, to enable these systems to more effectively recognize when clarification is needed and generate appropriate follow-up questions.
The ultimate goal is to create conversational AI that can engage in more natural, human-like dialogs by being able to identify information gaps and proactively seek clarification from users. This could significantly enhance the overall user experience and the effectiveness of conversational agents across a wide range of domains.
While the researchers acknowledge several limitations and areas for further research, this work represents an important step forward in advancing the state of the art in conversational AI systems, with potential implications for a variety of applications, from customer service chatbots to virtual personal assistants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
STYLE: Improving Domain Transferability of Asking Clarification Questions in Large Language Model Powered Conversational Agents
Yue Chen, Chen Huang, Yang Deng, Wenqiang Lei, Dingnan Jin, Jia Liu, Tat-Seng Chua
Equipping a conversational search engine with strategies regarding when to ask clarification questions is becoming increasingly important across various domains. Attributing to the context understanding capability of LLMs and their access to domain-specific sources of knowledge, LLM-based clarification strategies feature rapid transfer to various domains in a post-hoc manner. However, they still struggle to deliver promising performance on unseen domains, struggling to achieve effective domain transferability. We take the first step to investigate this issue and existing methods tend to produce one-size-fits-all strategies across diverse domains, limiting their search effectiveness. In response, we introduce a novel method, called Style, to achieve effective domain transferability. Our experimental results indicate that Style bears strong domain transferability, resulting in an average search performance improvement of ~10% on four unseen domains.
Read more6/4/2024
0
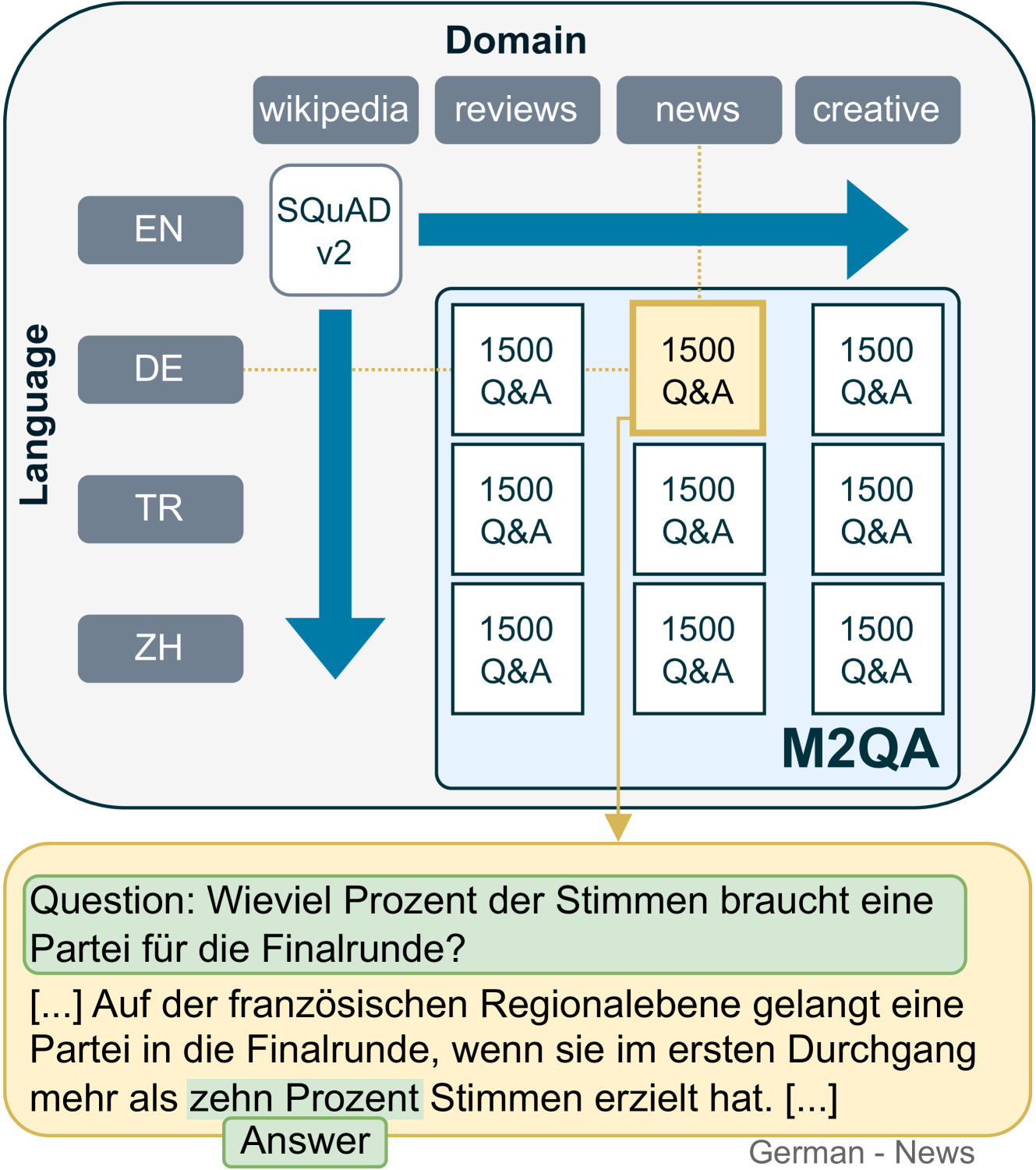
M2QA: Multi-domain Multilingual Question Answering
Leon Englander, Hannah Sterz, Clifton Poth, Jonas Pfeiffer, Ilia Kuznetsov, Iryna Gurevych
Generalization and robustness to input variation are core desiderata of machine learning research. Language varies along several axes, most importantly, language instance (e.g. French) and domain (e.g. news). While adapting NLP models to new languages within a single domain, or to new domains within a single language, is widely studied, research in joint adaptation is hampered by the lack of evaluation datasets. This prevents the transfer of NLP systems from well-resourced languages and domains to non-dominant language-domain combinations. To address this gap, we introduce M2QA, a multi-domain multilingual question answering benchmark. M2QA includes 13,500 SQuAD 2.0-style question-answer instances in German, Turkish, and Chinese for the domains of product reviews, news, and creative writing. We use M2QA to explore cross-lingual cross-domain performance of fine-tuned models and state-of-the-art LLMs and investigate modular approaches to domain and language adaptation. We witness 1) considerable performance variations across domain-language combinations within model classes and 2) considerable performance drops between source and target language-domain combinations across all model sizes. We demonstrate that M2QA is far from solved, and new methods to effectively transfer both linguistic and domain-specific information are necessary. We make M2QA publicly available at https://github.com/UKPLab/m2qa.
Read more7/2/2024
🛸
0
Retrieval Augmented Generation for Domain-specific Question Answering
Sanat Sharma, David Seunghyun Yoon, Franck Dernoncourt, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, Varun Kotte
Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
Read more5/30/2024

0
The Power of Question Translation Training in Multilingual Reasoning: Broadened Scope and Deepened Insights
Wenhao Zhu, Shujian Huang, Fei Yuan, Cheng Chen, Jiajun Chen, Alexandra Birch
Bridging the significant gap between large language model's English and non-English performance presents a great challenge. While some previous studies attempt to mitigate this gap with translated training data, the recently proposed question alignment approach leverages the model's English expertise to improve multilingual performance with minimum usage of expensive, error-prone translation. In this paper, we explore how broadly this method can be applied by examining its effects in reasoning with executable code and reasoning with common sense. We also explore how to apply this approach efficiently to extremely large language models using proxy-tuning. Experiment results on multilingual reasoning benchmarks mGSM, mSVAMP and xCSQA demonstrate that the question alignment approach can be used to boost multilingual performance across diverse reasoning scenarios, model families, and sizes. For instance, when applied to the LLaMA2 models, our method brings an average accuracy improvements of 12.2% on mGSM even with the 70B model. To understand the mechanism of its success, we analyze representation space, chain-of-thought and translation data scales, which reveals how question translation training strengthens language alignment within LLMs and shapes their working patterns.
Read more5/3/2024