Can I understand what I create? Self-Knowledge Evaluation of Large Language Models
2406.06140
0
0
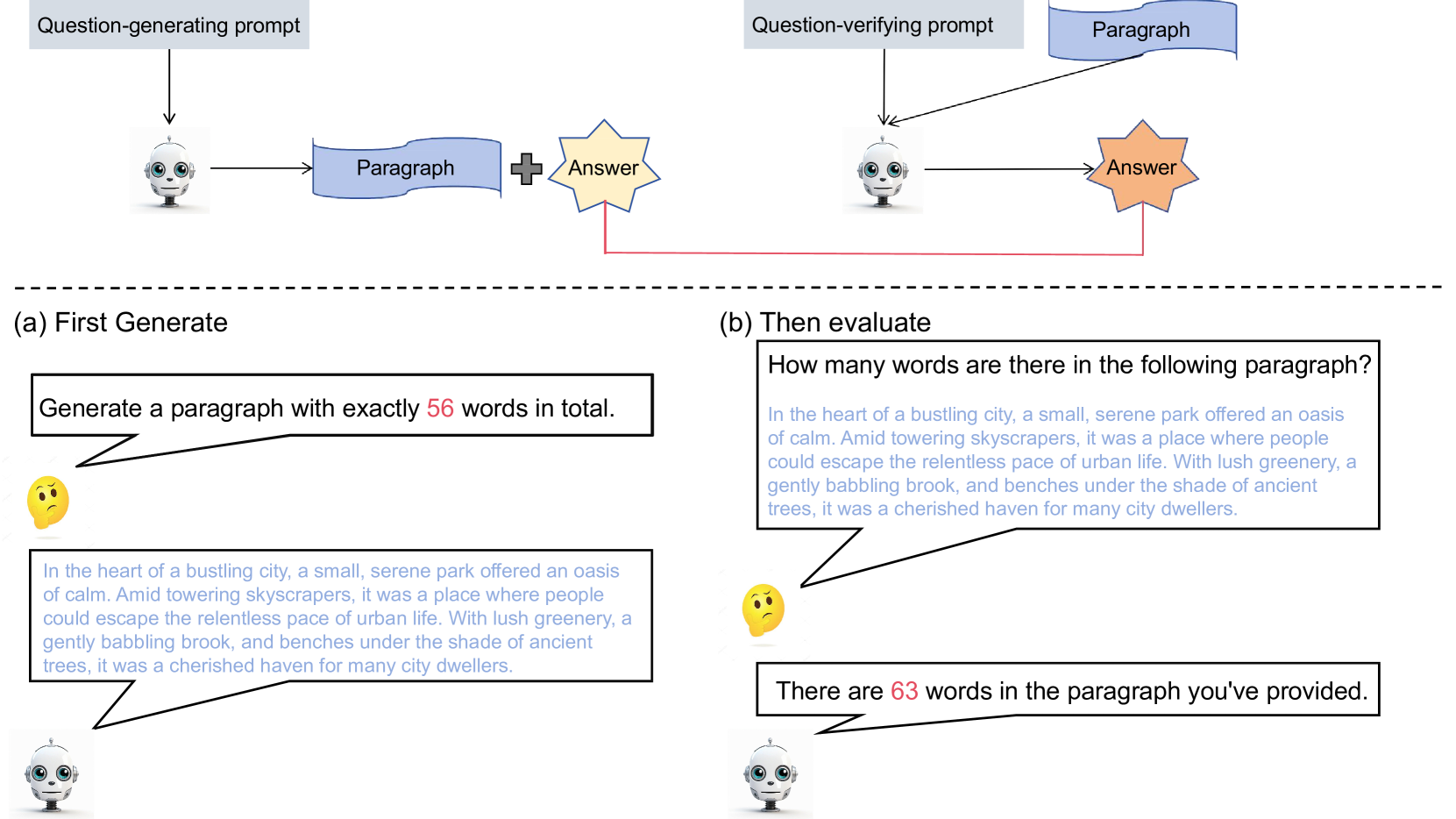
Abstract
Large language models (LLMs) have achieved remarkable progress in linguistic tasks, necessitating robust evaluation frameworks to understand their capabilities and limitations. Inspired by Feynman's principle of understanding through creation, we introduce a self-knowledge evaluation framework that is easy to implement, evaluating models on their ability to comprehend and respond to self-generated questions. Our findings, based on testing multiple models across diverse tasks, reveal significant gaps in the model's self-knowledge ability. Further analysis indicates these gaps may be due to misalignment with human attention mechanisms. Additionally, fine-tuning on self-generated math task may enhance the model's math performance, highlighting the potential of the framework for efficient and insightful model evaluation and may also contribute to the improvement of LLMs.
Create account to get full access
Overview
- This paper investigates the ability of large language models (LLMs) to understand and evaluate their own outputs, a crucial capability for their safe and trustworthy deployment.
- The researchers propose a comprehensive evaluation framework to assess LLMs' self-knowledge, including tasks that probe their understanding of their own capabilities and limitations.
- The findings shed light on the current state of self-knowledge in LLMs and highlight areas for further research and development to enhance their self-awareness and accountability.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, as these models become more advanced, it's important to understand how well they can comprehend and evaluate their own outputs. This is known as self-knowledge, and it's a crucial capability for ensuring the safe and trustworthy deployment of LLMs.
The researchers in this paper have developed a comprehensive evaluation framework to assess the self-knowledge of LLMs. This framework includes a variety of tasks that probe the models' understanding of their own capabilities and limitations. For example, the models might be asked to predict how well they would perform on a certain task or to identify potential biases or errors in their own outputs.
By applying this evaluation framework to different LLMs, the researchers were able to shed light on the current state of self-knowledge in these models. The findings suggest that while some LLMs have a basic understanding of their own capabilities, there is still room for improvement in their self-awareness and accountability.
The paper highlights the importance of continued research and development in this area, as enhancing the self-knowledge of LLMs could lead to significant advancements in their safe and responsible use. By understanding the limitations and biases of these models, developers can work to improve them and ensure that they are more trustworthy and transparent in their decision-making.
Technical Explanation
The paper proposes a comprehensive evaluation framework to assess the self-knowledge of large language models (LLMs). The framework includes a variety of tasks that probe the models' understanding of their own capabilities and limitations, such as:
-
Self-Evaluation Tasks: These tasks ask the LLMs to predict their own performance on a given task or to identify potential biases or errors in their outputs.
-
Self-Explanation Tasks: These tasks require the LLMs to explain their reasoning and decision-making processes, revealing their level of self-understanding.
-
Self-Calibration Tasks: These tasks assess the models' ability to accurately calibrate their confidence in their own outputs, indicating their self-awareness.
-
Self-Monitoring Tasks: These tasks evaluate the LLMs' ability to detect and correct their own mistakes, demonstrating their capacity for self-reflection and improvement.
The researchers applied this evaluation framework to several state-of-the-art LLMs, including GPT-3, BERT, and RoBERTa. The results suggest that while some models exhibit a basic understanding of their own capabilities, there are significant gaps in their self-knowledge. For example, the models often struggle to accurately predict their own performance or to identify biases and errors in their outputs.
The paper also highlights the importance of continued research and development in this area. Enhancing the self-knowledge of LLMs could lead to significant advancements in their safe and responsible use, as developers would be better equipped to understand and mitigate the models' limitations and biases. The authors suggest that future work should focus on developing training strategies and architectural designs that foster more robust self-knowledge in LLMs.
Critical Analysis
The paper's comprehensive evaluation framework represents a significant contribution to the field, as it provides a structured approach to assessing the self-knowledge of large language models. By probing various aspects of self-understanding, the framework offers valuable insights into the current limitations of these models and highlights areas for future improvement.
One potential limitation of the study is the scope of the evaluation. While the framework covers a broad range of self-knowledge tasks, it may not capture the full complexity of how LLMs understand and reason about themselves. Additionally, the specific tasks and metrics used in the evaluation may not fully capture all the nuances of self-knowledge.
Furthermore, the paper acknowledges that the evaluation was conducted on a limited set of LLMs, and the authors encourage further research to explore self-knowledge in a wider range of models and architectures. As the field of AI continues to rapidly evolve, it will be crucial to maintain a dynamic and comprehensive approach to evaluating the self-knowledge capabilities of these increasingly powerful systems.
Despite these caveats, the paper's findings serve as an important wake-up call for the AI research community. The apparent gaps in self-knowledge observed in current LLMs underscore the pressing need for more robust and accountable AI systems that can reliably understand and communicate the limitations of their own capabilities. Addressing these challenges will be crucial for ensuring the safe and responsible deployment of large language models in real-world applications.
Conclusion
This paper presents a comprehensive evaluation framework for assessing the self-knowledge of large language models (LLMs). The findings suggest that while some LLMs exhibit a basic understanding of their own capabilities, there are significant gaps in their self-knowledge that need to be addressed.
By developing a structured approach to evaluating self-knowledge, the researchers have laid the groundwork for further advancements in this critical area of AI development. Enhancing the self-knowledge of LLMs could lead to significant improvements in their safety, transparency, and trustworthiness, ultimately paving the way for more responsible and accountable AI systems. As the field of AI continues to evolve, this paper serves as an important reminder of the need for continued research and innovation in the realm of self-knowledge and self-awareness.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Knowledge of Knowledge: Exploring Known-Unknowns Uncertainty with Large Language Models
Alfonso Amayuelas, Liangming Pan, Wenhu Chen, William Wang
0
0
This paper investigates the capabilities of Large Language Models (LLMs) in the context of understanding their knowledge and uncertainty over questions. Specifically, we focus on addressing known-unknown questions, characterized by high uncertainty due to the absence of definitive answers. To facilitate our study, we collect a new dataset with Known-Unknown Questions (KUQ) and establish a categorization framework to clarify the origins of uncertainty in such queries. Subsequently, we examine the performance of open-source LLMs, fine-tuned using this dataset, in distinguishing between known and unknown queries within open-ended question-answering scenarios. The fine-tuned models demonstrated a significant improvement, achieving a considerable increase in F1-score relative to their pre-fine-tuning state. Through a comprehensive analysis, we reveal insights into the models' improved uncertainty articulation and their consequent efficacy in multi-agent debates. These findings help us understand how LLMs can be trained to identify and express uncertainty, improving our knowledge of how they understand and express complex or unclear information.
6/24/2024
💬
Into the Unknown: Self-Learning Large Language Models
Teddy Ferdinan, Jan Koco'n, Przemys{l}aw Kazienko
0
0
We address the main problem of self-learning LLM: the question of what to learn. We propose a self-learning LLM framework that enables an LLM to independently learn previously unknown knowledge through selfassessment of their own hallucinations. Using the hallucination score, we introduce a new concept of Points in the Unknown (PiUs), along with one extrinsic and three intrinsic methods for automatic PiUs identification. It facilitates the creation of a self-learning loop that focuses exclusively on the knowledge gap in Points in the Unknown, resulting in a reduced hallucination score. We also developed evaluation metrics for gauging an LLM's self-learning capability. Our experiments revealed that 7B-Mistral models that have been finetuned or aligned and RWKV5-Eagle are capable of self-learning considerably well. Our self-learning concept allows more efficient LLM updates and opens new perspectives for knowledge exchange. It may also increase public trust in AI.
6/5/2024
💬
Mind's Mirror: Distilling Self-Evaluation Capability and Comprehensive Thinking from Large Language Models
Weize Liu, Guocong Li, Kai Zhang, Bang Du, Qiyuan Chen, Xuming Hu, Hongxia Xu, Jintai Chen, Jian Wu
0
0
Large language models (LLMs) have achieved remarkable advancements in natural language processing. However, the massive scale and computational demands of these models present formidable challenges when considering their practical deployment in resource-constrained environments. While techniques such as chain-of-thought (CoT) distillation have displayed promise in distilling LLMs into small language models (SLMs), there is a risk that distilled SLMs may still inherit flawed reasoning and hallucinations from LLMs. To address these issues, we propose a twofold methodology: First, we introduce a novel method for distilling the self-evaluation capability from LLMs into SLMs, aiming to mitigate the adverse effects of flawed reasoning and hallucinations inherited from LLMs. Second, we advocate for distilling more comprehensive thinking by incorporating multiple distinct CoTs and self-evaluation outputs, to ensure a more thorough and robust knowledge transfer into SLMs. Experiments on three NLP benchmarks demonstrate that our method significantly improves the performance of distilled SLMs, offering a new perspective for developing more effective and efficient SLMs in resource-constrained environments.
4/9/2024
🤔
Understanding Understanding: A Pragmatic Framework Motivated by Large Language Models
Kevin Leyton-Brown, Yoav Shoham
0
0
Motivated by the rapid ascent of Large Language Models (LLMs) and debates about the extent to which they possess human-level qualities, we propose a framework for testing whether any agent (be it a machine or a human) understands a subject matter. In Turing-test fashion, the framework is based solely on the agent's performance, and specifically on how well it answers questions. Elements of the framework include circumscribing the set of questions (the scope of understanding), requiring general competence (passing grade), avoiding ridiculous answers, but still allowing wrong and I don't know answers to some questions. Reaching certainty about these conditions requires exhaustive testing of the questions which is impossible for nontrivial scopes, but we show how high confidence can be achieved via random sampling and the application of probabilistic confidence bounds. We also show that accompanying answers with explanations can improve the sample complexity required to achieve acceptable bounds, because an explanation of an answer implies the ability to answer many similar questions. According to our framework, current LLMs cannot be said to understand nontrivial domains, but as the framework provides a practical recipe for testing understanding, it thus also constitutes a tool for building AI agents that do understand.
6/21/2024