Invariant Subspace Decomposition

0

Sign in to get full access
Overview
- Provides a framework for decomposing high-dimensional data into a low-dimensional invariant subspace and a complementary high-dimensional residual subspace
- Enables identification of the most important underlying patterns and features in complex datasets
- Potential applications in areas like dimensionality reduction, feature extraction, and anomaly detection
Plain English Explanation
The paper presents a method for decomposing high-dimensional data into two key components: a low-dimensional "invariant" subspace that captures the most important patterns, and a high-dimensional "residual" subspace that contains the remaining, less significant variation. This technique can be useful for identifying the core features and structures within complex datasets, which has applications in areas like dimensionality reduction, feature extraction, and anomaly detection.
The core idea is to find a lower-dimensional subspace that remains "invariant" or unchanged under certain transformations of the data, while the remaining variation is relegated to the high-dimensional residual subspace. This allows the method to focus on the most salient aspects of the data, which can be particularly helpful when dealing with large, complex datasets.
Technical Explanation
The paper introduces a framework for invariant subspace decomposition, which aims to decompose high-dimensional data into a low-dimensional invariant subspace and a complementary high-dimensional residual subspace. The key steps are:
-
Invariant and residual subspaces: The method identifies an invariant subspace that remains unchanged under certain transformations of the data, and a residual subspace that captures the remaining variation.
-
Subspace projection: Data points are then projected onto the invariant and residual subspaces, respectively, allowing the most important patterns to be extracted.
-
Optimization: An optimization problem is formulated to find the invariant subspace that best captures the essential features of the data while minimizing the residual subspace.
The authors demonstrate the effectiveness of the approach through experiments on various datasets, showing its advantages for tasks like dimensionality reduction, feature extraction, and anomaly detection.
Critical Analysis
The paper presents a well-designed and theoretically-grounded approach for decomposing high-dimensional data. However, some potential limitations and areas for further research are:
- The method assumes the existence of a low-dimensional invariant subspace, which may not always be the case, especially for highly complex or noisy datasets.
- The optimization problem can be computationally expensive, particularly for large-scale applications, and the authors do not address scalability in depth.
- The paper focuses on the mathematical framework and theoretical properties, but more empirical evaluation on real-world problems could help validate the practical utility of the approach.
- Exploring potential synergies with other dimensionality reduction or feature extraction techniques could further enhance the method's capabilities.
Conclusion
The invariant subspace decomposition framework presented in this paper offers a principled approach for extracting the most important patterns and features from complex, high-dimensional data. By separating the data into a low-dimensional invariant subspace and a high-dimensional residual subspace, the method can focus on the essential aspects of the data, with potential applications in areas like dimensionality reduction, feature engineering, and anomaly detection. While the technique shows promise, further research is needed to address scalability, robustness, and synergies with other methods in order to unlock its full potential for real-world data analysis challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Invariant Subspace Decomposition
Margherita Lazzaretto, Jonas Peters, Niklas Pfister
We consider the task of predicting a response Y from a set of covariates X in settings where the conditional distribution of Y given X changes over time. For this to be feasible, assumptions on how the conditional distribution changes over time are required. Existing approaches assume, for example, that changes occur smoothly over time so that short-term prediction using only the recent past becomes feasible. In this work, we propose a novel invariance-based framework for linear conditionals, called Invariant Subspace Decomposition (ISD), that splits the conditional distribution into a time-invariant and a residual time-dependent component. As we show, this decomposition can be utilized both for zero-shot and time-adaptation prediction tasks, that is, settings where either no or a small amount of training data is available at the time points we want to predict Y at, respectively. We propose a practical estimation procedure, which automatically infers the decomposition using tools from approximate joint matrix diagonalization. Furthermore, we provide finite sample guarantees for the proposed estimator and demonstrate empirically that it indeed improves on approaches that do not use the additional invariant structure.
Read more4/16/2024

0
Probabilistic Decomposed Linear Dynamical Systems for Robust Discovery of Latent Neural Dynamics
Yenho Chen, Noga Mudrik, Kyle A. Johnsen, Sankaraleengam Alagapan, Adam S. Charles, Christopher J. Rozell
Time-varying linear state-space models are powerful tools for obtaining mathematically interpretable representations of neural signals. For example, switching and decomposed models describe complex systems using latent variables that evolve according to simple locally linear dynamics. However, existing methods for latent variable estimation are not robust to dynamical noise and system nonlinearity due to noise-sensitive inference procedures and limited model formulations. This can lead to inconsistent results on signals with similar dynamics, limiting the model's ability to provide scientific insight. In this work, we address these limitations and propose a probabilistic approach to latent variable estimation in decomposed models that improves robustness against dynamical noise. Additionally, we introduce an extended latent dynamics model to improve robustness against system nonlinearities. We evaluate our approach on several synthetic dynamical systems, including an empirically-derived brain-computer interface experiment, and demonstrate more accurate latent variable inference in nonlinear systems with diverse noise conditions. Furthermore, we apply our method to a real-world clinical neurophysiology dataset, illustrating the ability to identify interpretable and coherent structure where previous models cannot.
Read more9/2/2024
0
Learning Sparse High-Dimensional Matrix-Valued Graphical Models From Dependent Data
Jitendra K Tugnait
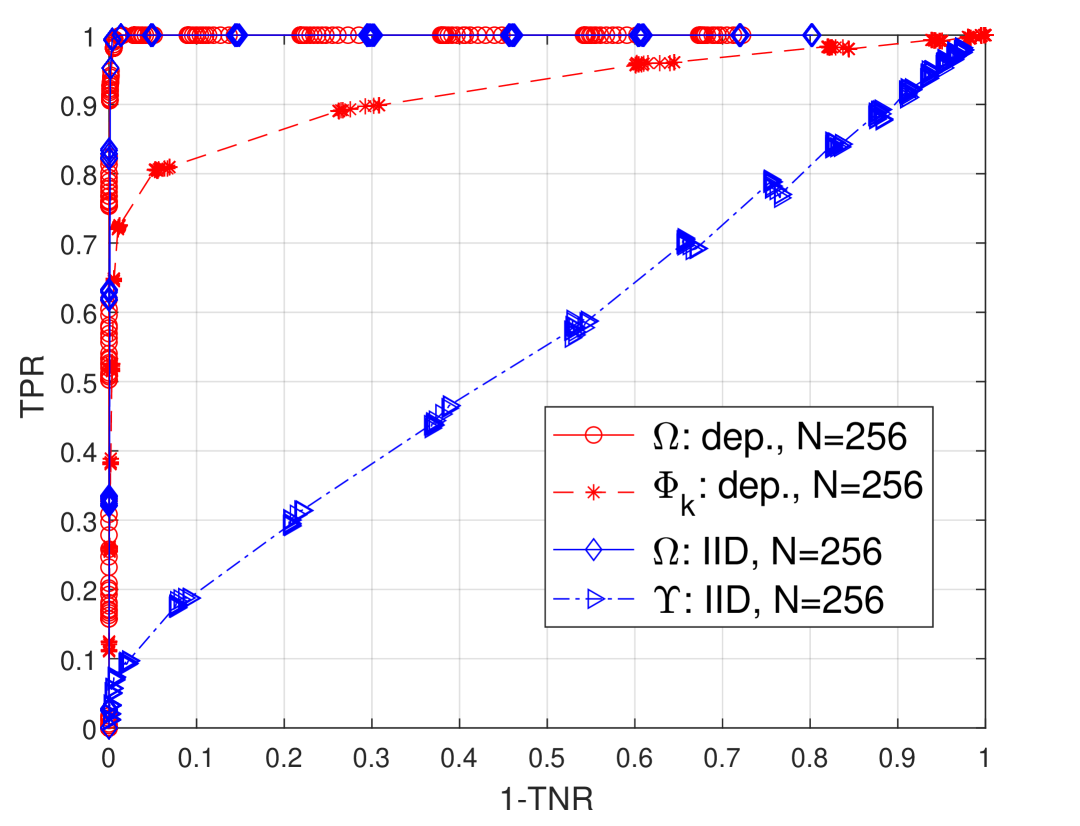
We consider the problem of inferring the conditional independence graph (CIG) of a sparse, high-dimensional, stationary matrix-variate Gaussian time series. All past work on high-dimensional matrix graphical models assumes that independent and identically distributed (i.i.d.) observations of the matrix-variate are available. Here we allow dependent observations. We consider a sparse-group lasso-based frequency-domain formulation of the problem with a Kronecker-decomposable power spectral density (PSD), and solve it via an alternating direction method of multipliers (ADMM) approach. The problem is bi-convex which is solved via flip-flop optimization. We provide sufficient conditions for local convergence in the Frobenius norm of the inverse PSD estimators to the true value. This result also yields a rate of convergence. We illustrate our approach using numerical examples utilizing both synthetic and real data.
Read more5/1/2024
0
Memory-Efficient LLM Training with Online Subspace Descent
Kaizhao Liang, Bo Liu, Lizhang Chen, Qiang Liu
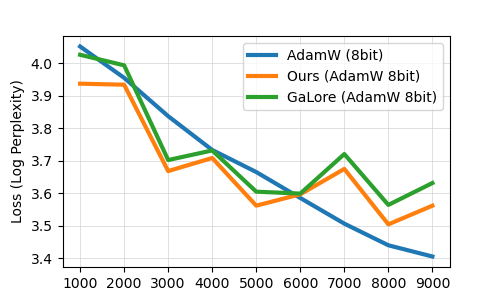
Recently, a wide range of memory-efficient LLM training algorithms have gained substantial popularity. These methods leverage the low-rank structure of gradients to project optimizer states into a subspace using projection matrix found by singular value decomposition (SVD). However, convergence of these algorithms is highly dependent on the update rules of their projection matrix. In this work, we provide the emph{first} convergence guarantee for arbitrary update rules of projection matrix. This guarantee is generally applicable to optimizers that can be analyzed with Hamiltonian Descent, including most common ones, such as LION, Adam. Inspired by our theoretical understanding, we propose Online Subspace Descent, a new family of subspace descent optimizer without SVD. Instead of updating the projection matrix with eigenvectors, Online Subspace Descent updates the projection matrix with online PCA. Online Subspace Descent is flexible and introduces only minimum overhead to training. We show that for the task of pretraining LLaMA models ranging from 60M to 7B parameters on the C4 dataset, Online Subspace Descent achieves lower perplexity and better downstream tasks performance than state-of-the-art low-rank training methods across different settings and narrows the gap with full-rank baselines.
Read more8/26/2024