InverseCoder: Unleashing the Power of Instruction-Tuned Code LLMs with Inverse-Instruct

0

Sign in to get full access
Overview
- This paper introduces InverseCoder, a novel approach for leveraging instruction-tuned code language models (LLMs) to generate high-quality code.
- InverseCoder uses a technique called "Inverse-Instruct" to train code LLMs on a diverse set of code-related tasks and instructions, enabling them to produce code more effectively than traditional supervised learning methods.
- The paper highlights key advancements in the field of code generation, including the use of large language models and synthetic data, as well as the challenges of aligning these models with specific coding tasks and instructions.
Plain English Explanation
The paper introduces InverseCoder, a new way to train code-generating AI models. These models, known as "language models," are trained on a huge amount of text data, which allows them to understand and generate human-like language. However, when it comes to generating code, traditional training methods have limitations.
InverseCoder uses a novel approach called "Inverse-Instruct" to train the code language models. Instead of just showing the models examples of code and expecting them to learn, InverseCoder gives the models specific instructions and tasks related to coding, like "Write a function to calculate the factorial of a number." By training the models on these kinds of instructions, they learn to generate code that is more closely aligned with the intended task or goal.
This approach builds on recent advancements in the field of code generation, such as using large language models and creating synthetic data to supplement the training process. However, the paper highlights that aligning these powerful models with specific coding tasks and instructions has been an ongoing challenge. InverseCoder aims to address this by explicitly training the models on code-related instructions and tasks.
Technical Explanation
The paper introduces InverseCoder, a novel approach for training instruction-tuned code language models (LLMs) using a technique called "Inverse-Instruct." This builds upon recent advancements in the field, including the use of large language models (CodeCLM) and the development of contrastive instruction-tuning methods (ContrastiveIT).
The key idea behind InverseCoder is to train code LLMs on a diverse set of code-related tasks and instructions, rather than just supervised examples of code. This "Inverse-Instruct" approach aims to better align the models with the specific goals and requirements of coding tasks, overcoming the limitations of traditional supervised learning.
The paper also discusses related work on scaling code LLMs (UniCoder) and using intermediate representations to make these models more robust (IRCoder).
Critical Analysis
The paper presents a novel and promising approach for training more effective code generation models. By explicitly incorporating code-related instructions and tasks into the training process, InverseCoder aims to address a key challenge in the field: aligning powerful language models with the specific requirements of coding tasks.
However, the paper does not provide a detailed evaluation of the InverseCoder approach, nor does it address potential limitations or areas for further research. For example, the paper does not discuss the scalability of the Inverse-Instruct training process, the generalizability of the resulting models to a wide range of coding tasks, or the potential for negative societal impacts (e.g., the use of such models for automated code generation in sensitive domains).
Additionally, the paper does not compare InverseCoder to other state-of-the-art approaches, such as the MagiCoder system, which also aims to leverage instruction-based training for code generation. A more thorough benchmarking and analysis of the InverseCoder approach would help to better understand its strengths, weaknesses, and potential impact on the field.
Conclusion
The InverseCoder paper introduces a novel approach for training code language models that aims to better align them with the specific requirements of coding tasks. By incorporating code-related instructions and tasks into the training process, the Inverse-Instruct technique seeks to overcome the limitations of traditional supervised learning methods.
While the paper presents a promising direction for advancing the state of the art in code generation, further research is needed to fully evaluate the approach, address potential limitations, and compare it to other cutting-edge methods in the field. Nonetheless, the work highlights the continued importance of developing more effective and versatile code generation tools, which could have significant implications for software development, education, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
InverseCoder: Unleashing the Power of Instruction-Tuned Code LLMs with Inverse-Instruct
Yutong Wu, Di Huang, Wenxuan Shi, Wei Wang, Lingzhe Gao, Shihao Liu, Ziyuan Nan, Kaizhao Yuan, Rui Zhang, Xishan Zhang, Zidong Du, Qi Guo, Yewen Pu, Dawei Yin, Xing Hu, Yunji Chen
Recent advancements in open-source code large language models (LLMs) have demonstrated remarkable coding abilities by fine-tuning on the data generated from powerful closed-source LLMs such as GPT-3.5 and GPT-4 for instruction tuning. This paper explores how to further improve an instruction-tuned code LLM by generating data from itself rather than querying closed-source LLMs. Our key observation is the misalignment between the translation of formal and informal languages: translating formal language (i.e., code) to informal language (i.e., natural language) is more straightforward than the reverse. Based on this observation, we propose INVERSE-INSTRUCT, which summarizes instructions from code snippets instead of the reverse. Specifically, given an instruction tuning corpus for code and the resulting instruction-tuned code LLM, we ask the code LLM to generate additional high-quality instructions for the original corpus through code summarization and self-evaluation. Then, we fine-tune the base LLM on the combination of the original corpus and the self-generated one, which yields a stronger instruction-tuned LLM. We present a series of code LLMs named InverseCoder, which surpasses the performance of the original code LLMs on a wide range of benchmarks, including Python text-to-code generation, multilingual coding, and data-science code generation.
Read more7/9/2024
1
CodecLM: Aligning Language Models with Tailored Synthetic Data
Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister
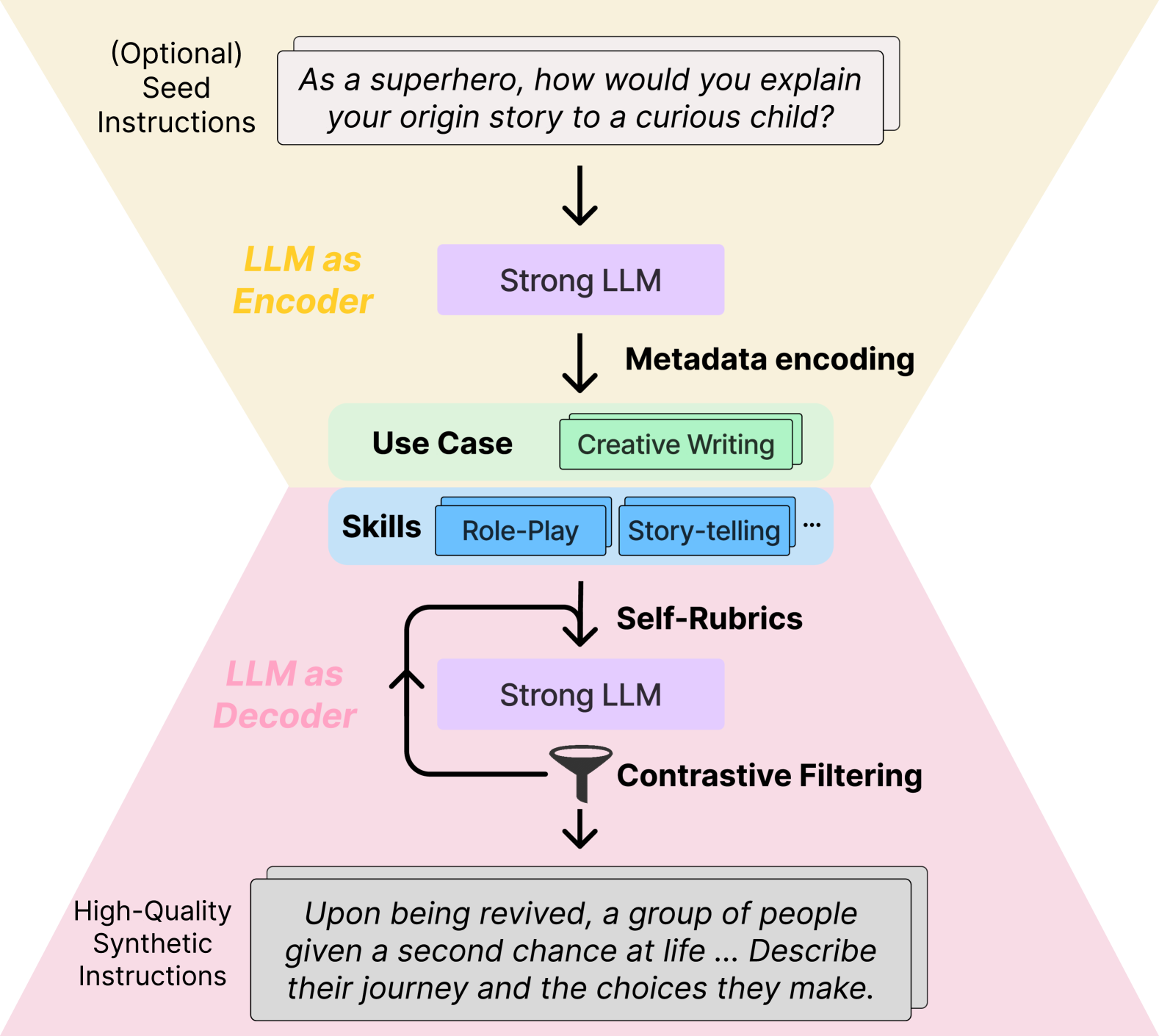
Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
Read more4/10/2024

0
Contrastive Instruction Tuning
Tianyi Lorena Yan, Fei Wang, James Y. Huang, Wenxuan Zhou, Fan Yin, Aram Galstyan, Wenpeng Yin, Muhao Chen
Instruction tuning has been used as a promising approach to improve the performance of large language models (LLMs) on unseen tasks. However, current LLMs exhibit limited robustness to unseen instructions, generating inconsistent outputs when the same instruction is phrased with slightly varied forms or language styles. This behavior indicates LLMs' lack of robustness to textual variations and generalizability to unseen instructions, potentially leading to trustworthiness issues. Accordingly, we propose Contrastive Instruction Tuning, which maximizes the similarity between the hidden representations of semantically equivalent instruction-instance pairs while minimizing the similarity between semantically different ones. To facilitate this approach, we augment the existing FLAN collection by paraphrasing task instructions. Experiments on the PromptBench benchmark show that CoIN consistently improves LLMs' robustness to unseen instructions with variations across character, word, sentence, and semantic levels by an average of +2.5% in accuracy. Code is available at https://github.com/luka-group/CoIN.
Read more6/7/2024

0
UniCoder: Scaling Code Large Language Model via Universal Code
Tao Sun, Linzheng Chai, Jian Yang, Yuwei Yin, Hongcheng Guo, Jiaheng Liu, Bing Wang, Liqun Yang, Zhoujun Li
Intermediate reasoning or acting steps have successfully improved large language models (LLMs) for handling various downstream natural language processing (NLP) tasks. When applying LLMs for code generation, recent works mainly focus on directing the models to articulate intermediate natural-language reasoning steps, as in chain-of-thought (CoT) prompting, and then output code with the natural language or other structured intermediate steps. However, such output is not suitable for code translation or generation tasks since the standard CoT has different logical structures and forms of expression with the code. In this work, we introduce the universal code (UniCode) as the intermediate representation. It is a description of algorithm steps using a mix of conventions of programming languages, such as assignment operator, conditional operator, and loop. Hence, we collect an instruction dataset UniCoder-Instruct to train our model UniCoder on multi-task learning objectives. UniCoder-Instruct comprises natural-language questions, code solutions, and the corresponding universal code. The alignment between the intermediate universal code representation and the final code solution significantly improves the quality of the generated code. The experimental results demonstrate that UniCoder with the universal code significantly outperforms the previous prompting methods by a large margin, showcasing the effectiveness of the structural clues in pseudo-code.
Read more6/26/2024