IRCoder: Intermediate Representations Make Language Models Robust Multilingual Code Generators
2403.03894
0
0
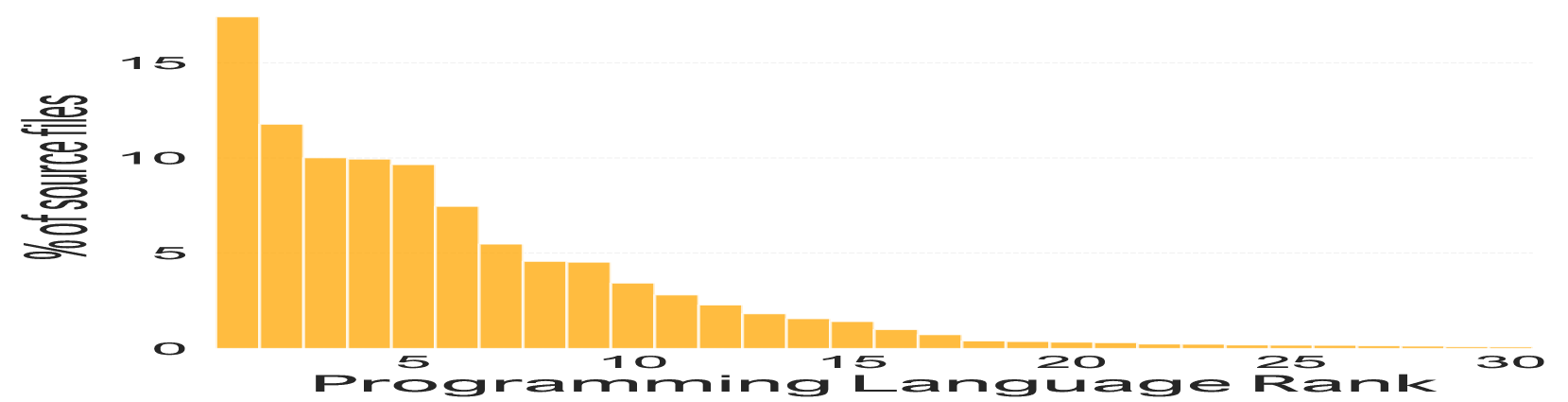
Abstract
Code understanding and generation have fast become some of the most popular applications of language models (LMs). Nonetheless, research on multilingual aspects of Code-LMs (i.e., LMs for code generation) such as cross-lingual transfer between different programming languages, language-specific data augmentation, and post-hoc LM adaptation, alongside exploitation of data sources other than the original textual content, has been much sparser than for their natural language counterparts. In particular, most mainstream Code-LMs have been pre-trained on source code files alone. In this work, we investigate the prospect of leveraging readily available compiler intermediate representations (IR) - shared across programming languages - to improve the multilingual capabilities of Code-LMs and facilitate cross-lingual transfer. To this end, we first compile SLTrans, a parallel dataset consisting of nearly 4M self-contained source code files coupled with respective intermediate representations. Next, starting from various base Code-LMs (ranging in size from 1.1B to 7.3B parameters), we carry out continued causal language modelling training on SLTrans, forcing the Code-LMs to (1) learn the IR language and (2) align the IR constructs with respective constructs of various programming languages. Our resulting models, dubbed IRCoder, display sizeable and consistent gains across a wide variety of code generation tasks and metrics, including prompt robustness, multilingual code completion, code understanding, and instruction following.
Create account to get full access
Overview
- This paper proposes a novel approach called "IRCoder" that uses intermediate representations (IRs) to make language models more robust and capable of generating code in multiple programming languages.
- The key idea is to leverage IRs, which provide a language-agnostic abstraction of code, to enable language models to produce high-quality code outputs in various languages.
- The authors demonstrate the effectiveness of their approach through extensive experiments, showing that IRCoder outperforms state-of-the-art code generation models on a range of benchmarks.
Plain English Explanation
Computers need to be able to understand and generate code in different programming languages to tackle a wide variety of tasks. However, this can be challenging for language models, as they are typically trained on text data and may struggle to generalize to the specifics of coding.
The researchers behind this paper have developed a new approach called "IRCoder" that aims to address this problem. The key insight is to use an intermediate representation (IR), which is a way of representing code in a language-agnostic format. By training their model on this IR, IRCoder is able to generate high-quality code in multiple programming languages, rather than being limited to a single language.
The researchers demonstrate that IRCoder outperforms other state-of-the-art code generation models on a range of benchmarks. This suggests that the use of IRs can make language models more robust and capable of cross-lingual transfer, which is an important capability for real-world applications.
Technical Explanation
The IRCoder model proposed in this paper is based on the idea of using an intermediate representation (IR) to enable language models to generate code in multiple programming languages.
The authors first define an IR schema that captures the essential features of code, such as data types, control flow, and function calls. They then train their language model to generate this IR representation, rather than directly generating code in a specific language.
During inference, the model first generates the IR, and then transforms it into the target programming language using a set of language-specific rules. This approach allows the model to leverage the cross-lingual transfer learning capabilities of the IR, while still producing code that is tailored to the specific requirements of the target language.
The authors evaluate IRCoder on a range of code generation benchmarks, including tasks that require cross-lingual generalization and mathematical reasoning. The results demonstrate that IRCoder outperforms other state-of-the-art models, particularly on more challenging tasks that require robust and flexible code generation capabilities.
Critical Analysis
The key strength of the IRCoder approach is its ability to leverage intermediate representations to enable language models to generate high-quality code in multiple programming languages. This is a significant advancement over previous approaches that were limited to a single language.
However, the paper does not address some potential limitations of the IRCoder approach. For example, the authors do not discuss how the performance of the model might scale with the complexity of the IR schema or the number of target programming languages. Additionally, the paper does not explore the tradeoffs between the flexibility of the IR and the fidelity of the generated code.
It would also be interesting to see how IRCoder compares to other approaches that leverage cross-lingual transfer learning or mathematical reasoning for code generation. Further research in these areas could provide valuable insights into the strengths and limitations of the IRCoder approach.
Conclusion
The IRCoder model proposed in this paper represents an exciting advancement in the field of code generation. By leveraging intermediate representations, the authors have developed a language model that is capable of generating high-quality code in multiple programming languages, with demonstrated cross-lingual transfer learning capabilities.
This work has important implications for a wide range of applications, from automated programming to mathematical reasoning and beyond. As the field of code generation continues to evolve, approaches like IRCoder will be crucial for enabling language models to tackle increasingly complex and diverse coding tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

UniCoder: Scaling Code Large Language Model via Universal Code
Tao Sun, Linzheng Chai, Jian Yang, Yuwei Yin, Hongcheng Guo, Jiaheng Liu, Bing Wang, Liqun Yang, Zhoujun Li
0
0
Intermediate reasoning or acting steps have successfully improved large language models (LLMs) for handling various downstream natural language processing (NLP) tasks. When applying LLMs for code generation, recent works mainly focus on directing the models to articulate intermediate natural-language reasoning steps, as in chain-of-thought (CoT) prompting, and then output code with the natural language or other structured intermediate steps. However, such output is not suitable for code translation or generation tasks since the standard CoT has different logical structures and forms of expression with the code. In this work, we introduce the universal code (UniCode) as the intermediate representation. It is a description of algorithm steps using a mix of conventions of programming languages, such as assignment operator, conditional operator, and loop. Hence, we collect an instruction dataset UniCoder-Instruct to train our model UniCoder on multi-task learning objectives. UniCoder-Instruct comprises natural-language questions, code solutions, and the corresponding universal code. The alignment between the intermediate universal code representation and the final code solution significantly improves the quality of the generated code. The experimental results demonstrate that UniCoder with the universal code significantly outperforms the previous prompting methods by a large margin, showcasing the effectiveness of the structural clues in pseudo-code.
6/26/2024
💬
Exploring and Unleashing the Power of Large Language Models in Automated Code Translation
Zhen Yang, Fang Liu, Zhongxing Yu, Jacky Wai Keung, Jia Li, Shuo Liu, Yifan Hong, Xiaoxue Ma, Zhi Jin, Ge Li
0
0
Code translation tools (transpilers) are developed for automatic source-to-source translation. Although learning-based transpilers have shown impressive enhancement against rule-based counterparts, owing to their task-specific pre-training on extensive monolingual corpora. Their current performance still remains unsatisfactory for practical deployment, and the associated training resources are also prohibitively expensive. LLMs pre-trained on huge amounts of human-written code/text have shown remarkable performance in many code intelligence tasks due to their powerful generality, even without task-specific training. Thus, LLMs can potentially circumvent the above limitations, but they have not been exhaustively explored yet. This paper investigates diverse LLMs and learning-based transpilers for automated code translation tasks, finding that: although certain LLMs have outperformed current transpilers, they still have some accuracy issues, where most of the failures are induced by a lack of comprehension of source programs, missing clear instructions on I/O types in translation, and ignoring discrepancies between source and target programs. Enlightened by the above findings, we further propose UniTrans, a Unified code Translation framework, applicable to various LLMs, for unleashing their power in this field. Specifically, UniTrans first crafts a series of test cases for target programs with the assistance of source programs. Next, it harnesses the above auto-generated test cases to augment the code translation and then evaluate their correctness via execution. Afterward, UniTrans further (iteratively) repairs incorrectly translated programs prompted by test case execution results. Extensive experiments are conducted on six settings of translation datasets between Python, Java, and C++. Three recent LLMs of diverse sizes are tested with UniTrans, and all achieve substantial improvements.
5/14/2024

Eliciting Better Multilingual Structured Reasoning from LLMs through Code
Bryan Li, Tamer Alkhouli, Daniele Bonadiman, Nikolaos Pappas, Saab Mansour
0
0
The development of large language models (LLM) has shown progress on reasoning, though studies have largely considered either English or simple reasoning tasks. To address this, we introduce a multilingual structured reasoning and explanation dataset, termed xSTREET, that covers four tasks across six languages. xSTREET exposes a gap in base LLM performance between English and non-English reasoning tasks. We then propose two methods to remedy this gap, building on the insight that LLMs trained on code are better reasoners. First, at training time, we augment a code dataset with multilingual comments using machine translation while keeping program code as-is. Second, at inference time, we bridge the gap between training and inference by employing a prompt structure that incorporates step-by-step code primitives to derive new facts and find a solution. Our methods show improved multilingual performance on xSTREET, most notably on the scientific commonsense reasoning subtask. Furthermore, the models show no regression on non-reasoning tasks, thus demonstrating our techniques maintain general-purpose abilities.
6/13/2024
🏋️
SemCoder: Training Code Language Models with Comprehensive Semantics
Yangruibo Ding, Jinjun Peng, Marcus J. Min, Gail Kaiser, Junfeng Yang, Baishakhi Ray
0
0
Code Large Language Models (Code LLMs) have excelled at tasks like code completion but often miss deeper semantics such as execution effects and dynamic states. This paper aims to bridge the gap between Code LLMs' reliance on static text data and the need for thorough semantic understanding for complex tasks like debugging and program repair. We introduce a novel strategy to train Code LLMs with comprehensive semantics, encompassing high-level functional descriptions, local execution effects of individual statements, and overall input/output behavior, thereby linking static code text with dynamic execution states. We begin by collecting PyX, a clean code corpus of fully executable samples with functional descriptions and execution tracing. We propose training Code LLMs to write code and represent and reason about execution behaviors using natural language, mimicking human verbal debugging. This approach led to the development of SemCoder, a Code LLM with only 6.7B parameters, which shows competitive performance with GPT-3.5-turbo on code generation and execution reasoning tasks. SemCoder achieves 81.1% on HumanEval (GPT-3.5-turbo: 76.8%) and 54.5% on CRUXEval-I (GPT-3.5-turbo: 50.3%). We also study the effectiveness of SemCoder's monologue-style execution reasoning compared to concrete scratchpad reasoning, showing that our approach integrates semantics from multiple dimensions more smoothly. Finally, we demonstrate the potential of applying learned semantics to improve Code LLMs' debugging and self-refining capabilities.
6/4/2024