Inverted Activations

0

Sign in to get full access
Overview
- This research paper introduces a novel method called "Inverted Activations" for reading information from neural networks.
- The method aims to provide a general-purpose way to understand the inner workings and decision-making process of neural networks.
- Key ideas include using the network's own architecture to invert the activation functions and recover information about the input.
Plain English Explanation
Neural networks are powerful machine learning models that can learn complex patterns in data. However, understanding how these models make their decisions can be challenging. The Inverted Activations method proposes a way to "look inside" the network and see what information it is using to make its predictions.
The core idea is to "invert" the activation functions used in the network. Activation functions are the mathematical operations that transform the inputs to the neurons in a neural network. By inverting these functions, the researchers were able to recover information about the original inputs that led to certain activations in the network.
This allows us to see what features or patterns the network is focusing on when making its decisions. For example, if the network is classifying images, the inverted activations could reveal which parts of the image were most important for the classification.
The Inverted Activations method is designed to be a general-purpose tool that can be applied to many different types of neural networks, not just image classification. This makes it a potentially valuable tool for understanding and interpreting the inner workings of these complex models.
Technical Explanation
The Inverted Activations method works by treating the neural network as a function that maps inputs to outputs. The researchers show that under certain conditions, it is possible to invert this function and recover information about the inputs from the activations in the hidden layers of the network.
Specifically, the method relies on the network having 1-Lipschitz activations, which means the activations satisfy a certain mathematical property that ensures they do not "stretch" the inputs too much. This allows the inversion process to be well-defined and stable.
The researchers also introduce a technique called "tilt activation," which can be used to enhance the spatial invariance of the network's activations, making the inversion process more effective. This is described in the Tilt Your Head paper.
The Inverted Activations method is evaluated on a range of tasks, including image classification, language modeling, and reinforcement learning. The results show that the method can effectively recover information about the inputs and provide insights into the decision-making process of the neural networks.
Critical Analysis
The Inverted Activations method is a promising approach for understanding neural networks, but it does have some limitations.
One key limitation is that the method relies on the network having 1-Lipschitz activations, which may not always be the case in practice. The researchers address this by introducing the "tilt activation" technique, but this still may not be sufficient for all types of neural networks.
Additionally, the method may be computationally expensive, especially for large and complex models. This could limit its practicality for real-world applications.
It would also be valuable to see the method applied to more diverse datasets and tasks beyond the ones explored in the paper. This could help validate the generality of the approach and uncover any potential biases or limitations.
Overall, the Inverted Activations method is an important step towards better understanding the inner workings of neural networks. However, further research and development may be needed to make it a truly robust and practical tool for interpreting these complex models.
Conclusion
The Inverted Activations method introduces a novel approach for reading information from neural networks. By inverting the activation functions, the method can provide insights into the decision-making process of the network and help users better understand how these powerful models work.
While the method has some limitations, it represents an important step forward in the field of neural network interpretability. As AI systems become more prevalent in our lives, tools like Inverted Activations will be crucial for building trust and transparency in these technologies. Continued research and development in this area could lead to significant advancements in our ability to understand and interpret the inner workings of complex machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Inverted Activations
Georgii Novikov, Ivan Oseledets
The scaling of neural networks with increasing data and model sizes necessitates more efficient deep learning algorithms. This paper addresses the memory footprint challenge in neural network training by proposing a modification to the handling of activation tensors in pointwise nonlinearity layers. Traditionally, these layers save the entire input tensor for the backward pass, leading to substantial memory use. Our method involves saving the output tensor instead, reducing the memory required when the subsequent layer also saves its input tensor. This approach is particularly beneficial for transformer-based architectures like GPT, BERT, Mistral, and Llama. Application of our method involves taken an inverse function of nonlinearity. To the best of our knowledge, that can not be done analitically and instead we buid an accurate approximations using simpler functions. Experimental results confirm that our method significantly reduces memory usage without affecting training accuracy. The implementation is available at https://github.com/PgLoLo/optiacts.
Read more7/23/2024
✨
0
Batchless Normalization: How to Normalize Activations Across Instances with Minimal Memory Requirements
Benjamin Berger (Leibniz Universitat Hannover), Victor Uc Cetina (Universidad Aut'onoma de Yucat'an)
In training neural networks, batch normalization has many benefits, not all of them entirely understood. But it also has some drawbacks. Foremost is arguably memory consumption, as computing the batch statistics requires all instances within the batch to be processed simultaneously, whereas without batch normalization it would be possible to process them one by one while accumulating the weight gradients. Another drawback is that that distribution parameters (mean and standard deviation) are unlike all other model parameters in that they are not trained using gradient descent but require special treatment, complicating implementation. In this paper, I show a simple and straightforward way to address these issues. The idea, in short, is to add terms to the loss that, for each activation, cause the minimization of the negative log likelihood of a Gaussian distribution that is used to normalize the activation. Among other benefits, this will hopefully contribute to the democratization of AI research by means of lowering the hardware requirements for training larger models.
Read more7/26/2024

0
InversionView: A General-Purpose Method for Reading Information from Neural Activations
Xinting Huang, Madhur Panwar, Navin Goyal, Michael Hahn
The inner workings of neural networks can be better understood if we can fully decipher the information encoded in neural activations. In this paper, we argue that this information is embodied by the subset of inputs that give rise to similar activations. Computing such subsets is nontrivial as the input space is exponentially large. We propose InversionView, which allows us to practically inspect this subset by sampling from a trained decoder model conditioned on activations. This helps uncover the information content of activation vectors, and facilitates understanding of the algorithms implemented by transformer models. We present four case studies where we investigate models ranging from small transformers to GPT-2. In these studies, we demonstrate the characteristics of our method, show the distinctive advantages it offers, and provide causally verified circuits.
Read more7/16/2024
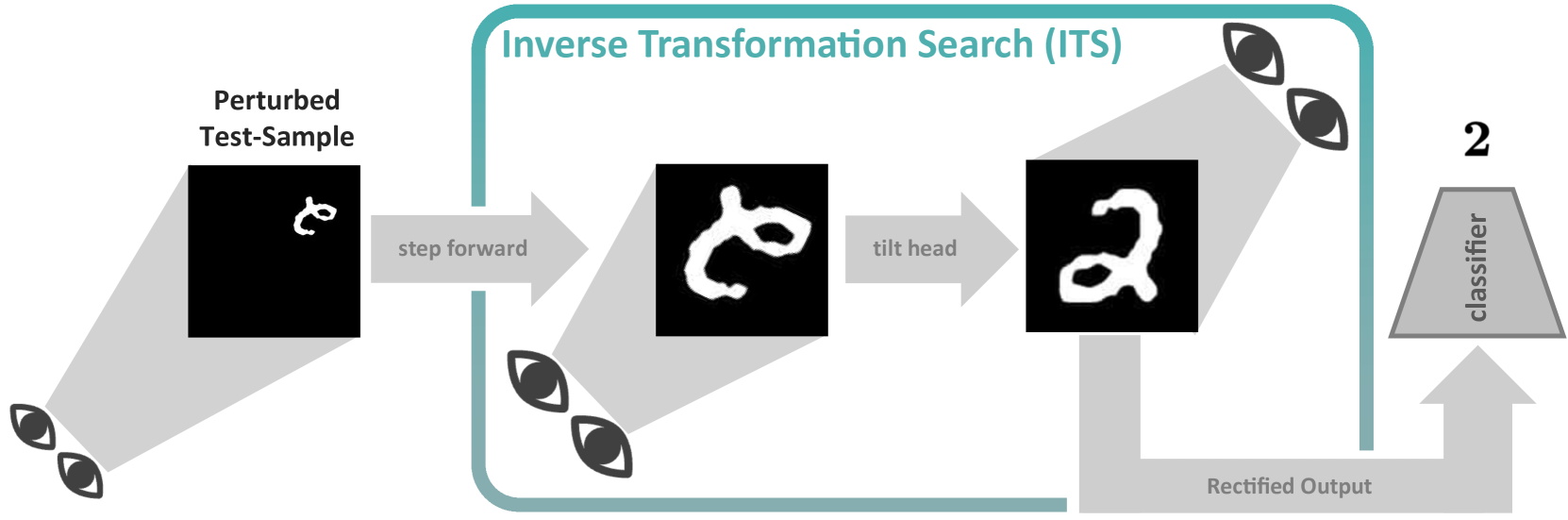
0
Tilt your Head: Activating the Hidden Spatial-Invariance of Classifiers
Johann Schmidt, Sebastian Stober
Deep neural networks are applied in more and more areas of everyday life. However, they still lack essential abilities, such as robustly dealing with spatially transformed input signals. Approaches to mitigate this severe robustness issue are limited to two pathways: Either models are implicitly regularised by increased sample variability (data augmentation) or explicitly constrained by hard-coded inductive biases. The limiting factor of the former is the size of the data space, which renders sufficient sample coverage intractable. The latter is limited by the engineering effort required to develop such inductive biases for every possible scenario. Instead, we take inspiration from human behaviour, where percepts are modified by mental or physical actions during inference. We propose a novel technique to emulate such an inference process for neural nets. This is achieved by traversing a sparsified inverse transformation tree during inference using parallel energy-based evaluations. Our proposed inference algorithm, called Inverse Transformation Search (ITS), is model-agnostic and equips the model with zero-shot pseudo-invariance to spatially transformed inputs. We evaluated our method on several benchmark datasets, including a synthesised ImageNet test set. ITS outperforms the utilised baselines on all zero-shot test scenarios.
Read more5/28/2024