InversionView: A General-Purpose Method for Reading Information from Neural Activations

0

Sign in to get full access
InversionView: A General-Purpose Method for Reading Information from Neural Activations
Overview
- This paper introduces InversionView, a method for extracting information from the hidden activations of neural networks.
- The technique allows researchers to better understand what information is represented in a neural network's internal representations.
- InversionView can be applied to a wide range of neural network architectures and tasks, making it a general-purpose tool for network analysis.
Plain English Explanation
Neural networks are powerful machine learning models that can learn to perform a variety of tasks, from image recognition to language processing. However, it can be challenging to understand exactly what information these models are learning and representing in their internal layers.
The InversionView method provides a way to peek inside the "black box" of a neural network and better understand the information encoded in its hidden activations. By inverting the network's layers, the researchers can map the hidden representations back to the original inputs, revealing the specific features and patterns the network has learned to detect.
This approach is useful for a number of applications, such as visualizing neural network imagination, explaining concept activation vectors, and understanding inductive biases in transformer models. By shedding light on the inner workings of neural networks, InversionView can help researchers and developers build more interpretable and trustworthy AI systems.
Technical Explanation
The InversionView method works by training an "inversion network" to map the hidden activations of the target neural network back to the original input. This is done by defining a loss function that encourages the inversion network to reproduce the original inputs as accurately as possible.
The researchers demonstrate the versatility of InversionView by applying it to a variety of neural network architectures, including convolutional networks, recurrent networks, and transformers. They show that the inversion network is able to successfully recover meaningful representations from the hidden activations, such as the spatial patterns in image data or the semantic concepts in text embeddings.
One key insight from the paper is that the quality of the inversion is affected by the "spatial invariance" of the neural network. Models that tilt their head to activate hidden spatial invariance, such as convolutional networks, tend to have more disentangled and interpretable hidden representations that are easier to invert.
The researchers also explore the use of Activator-GLU activations to improve the performance of the inversion network, demonstrating the flexibility and generality of the InversionView approach.
Critical Analysis
The InversionView method represents a significant advance in the field of neural network interpretability, providing a general-purpose tool for probing the inner workings of complex models. However, the paper does acknowledge some limitations and areas for future research.
One potential concern is the computational cost of training the inversion network, which may limit the practicality of the approach for very large or complex neural networks. The researchers suggest that further improvements to the inversion algorithm or the use of more efficient network architectures could help address this issue.
Additionally, the paper does not explore the potential for adversarial attacks or other security vulnerabilities that may arise from the ability to invert neural network activations. As AI systems become more widely deployed, it will be important to carefully consider the implications of techniques like InversionView for the robustness and trustworthiness of these models.
Overall, the InversionView method represents an important step forward in our understanding of neural networks and our ability to interpret their inner workings. By shedding light on the representations learned by these models, this research can help drive the development of more transparent and accountable AI systems.
Conclusion
The InversionView method introduced in this paper provides a powerful and general-purpose approach for extracting information from the hidden activations of neural networks. By training an inversion network to map these internal representations back to the original inputs, researchers can gain valuable insights into what these models are learning and how they are processing information.
This technique has broad applications in areas such as network visualization, concept activation analysis, and understanding model biases. As AI systems become more complex and widely deployed, tools like InversionView will be increasingly important for ensuring the transparency and trustworthiness of these systems.
While the paper acknowledges some limitations and areas for further research, the InversionView method represents a significant advance in the field of neural network interpretability. By empowering researchers and developers to better understand the "black box" of neural networks, this work can help drive the development of more robust and accountable AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
InversionView: A General-Purpose Method for Reading Information from Neural Activations
Xinting Huang, Madhur Panwar, Navin Goyal, Michael Hahn
The inner workings of neural networks can be better understood if we can fully decipher the information encoded in neural activations. In this paper, we argue that this information is embodied by the subset of inputs that give rise to similar activations. Computing such subsets is nontrivial as the input space is exponentially large. We propose InversionView, which allows us to practically inspect this subset by sampling from a trained decoder model conditioned on activations. This helps uncover the information content of activation vectors, and facilitates understanding of the algorithms implemented by transformer models. We present four case studies where we investigate models ranging from small transformers to GPT-2. In these studies, we demonstrate the characteristics of our method, show the distinctive advantages it offers, and provide causally verified circuits.
Read more7/16/2024

0
Network Inversion of Convolutional Neural Nets
Pirzada Suhail, Amit Sethi
Neural networks have emerged as powerful tools across various applications, yet their decision-making process often remains opaque, leading to them being perceived as black boxes. This opacity raises concerns about their interpretability and reliability, especially in safety-critical scenarios. Network inversion techniques offer a solution by allowing us to peek inside these black boxes, revealing the features and patterns learned by the networks behind their decision-making processes and thereby provide valuable insights into how neural networks arrive at their conclusions, making them more interpretable and trustworthy. This paper presents a simple yet effective approach to network inversion using a carefully conditioned generator that learns the data distribution in the input space of the trained neural network, enabling the reconstruction of inputs that would most likely lead to the desired outputs. To capture the diversity in the input space for a given output, instead of simply revealing the conditioning labels to the generator, we hideously encode the conditioning label information into vectors, further exemplified by heavy dropout in the generation process and minimisation of cosine similarity between the features corresponding to the generated images. The paper concludes with immediate applications of Network Inversion including in interpretability, explainability and generation of adversarial samples.
Read more7/26/2024
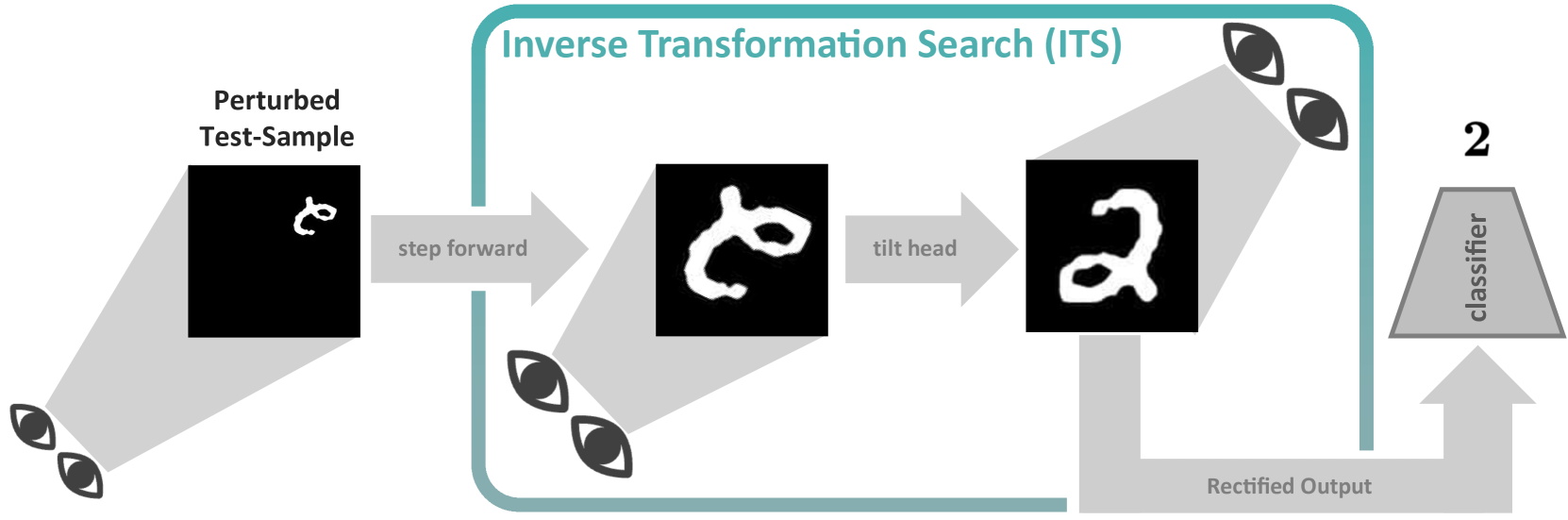
0
Tilt your Head: Activating the Hidden Spatial-Invariance of Classifiers
Johann Schmidt, Sebastian Stober
Deep neural networks are applied in more and more areas of everyday life. However, they still lack essential abilities, such as robustly dealing with spatially transformed input signals. Approaches to mitigate this severe robustness issue are limited to two pathways: Either models are implicitly regularised by increased sample variability (data augmentation) or explicitly constrained by hard-coded inductive biases. The limiting factor of the former is the size of the data space, which renders sufficient sample coverage intractable. The latter is limited by the engineering effort required to develop such inductive biases for every possible scenario. Instead, we take inspiration from human behaviour, where percepts are modified by mental or physical actions during inference. We propose a novel technique to emulate such an inference process for neural nets. This is achieved by traversing a sparsified inverse transformation tree during inference using parallel energy-based evaluations. Our proposed inference algorithm, called Inverse Transformation Search (ITS), is model-agnostic and equips the model with zero-shot pseudo-invariance to spatially transformed inputs. We evaluated our method on several benchmark datasets, including a synthesised ImageNet test set. ITS outperforms the utilised baselines on all zero-shot test scenarios.
Read more5/28/2024

0
Inverted Activations
Georgii Novikov, Ivan Oseledets
The scaling of neural networks with increasing data and model sizes necessitates more efficient deep learning algorithms. This paper addresses the memory footprint challenge in neural network training by proposing a modification to the handling of activation tensors in pointwise nonlinearity layers. Traditionally, these layers save the entire input tensor for the backward pass, leading to substantial memory use. Our method involves saving the output tensor instead, reducing the memory required when the subsequent layer also saves its input tensor. This approach is particularly beneficial for transformer-based architectures like GPT, BERT, Mistral, and Llama. Application of our method involves taken an inverse function of nonlinearity. To the best of our knowledge, that can not be done analitically and instead we buid an accurate approximations using simpler functions. Experimental results confirm that our method significantly reduces memory usage without affecting training accuracy. The implementation is available at https://github.com/PgLoLo/optiacts.
Read more7/23/2024