Investigating and Mitigating the Multimodal Hallucination Snowballing in Large Vision-Language Models
2407.00569
0
0
💬
Abstract
Though advanced in understanding visual information with human languages, Large Vision-Language Models (LVLMs) still suffer from multimodal hallucinations. A natural concern is that during multimodal interaction, the generated hallucinations could influence the LVLMs' subsequent generation. Thus, we raise a question: When presented with a query relevant to the previously generated hallucination, will LVLMs be misled and respond incorrectly, even though the ground visual information exists? To answer this, we propose a framework called MMHalSnowball to evaluate LVLMs' behaviors when encountering generated hallucinations, where LVLMs are required to answer specific visual questions within a curated hallucinatory conversation. Crucially, our experiment shows that the performance of open-source LVLMs drops by at least $31%$, indicating that LVLMs are prone to accept the generated hallucinations and make false claims that they would not have supported without distractions. We term this phenomenon Multimodal Hallucination Snowballing. To mitigate this, we further propose a training-free method called Residual Visual Decoding, where we revise the output distribution of LVLMs with the one derived from the residual visual input, providing models with direct access to the visual information. Experiments show that our method can mitigate more than $24%$ of the snowballed multimodal hallucination while maintaining capabilities.
Create account to get full access
Overview
- Large Vision-Language Models (LVLMs) are advanced in understanding visual information with human languages, but they still suffer from multimodal hallucinations.
- Multimodal hallucinations occur when LVLMs generate false or irrelevant information during multimodal interaction, which could influence their subsequent generation.
- The paper proposes a framework called MMHalSnowball to evaluate LVLMs' behaviors when encountering generated hallucinations.
- The experiment shows that the performance of open-source LVLMs drops by at least 31%, indicating they are prone to accepting generated hallucinations and making false claims.
- This phenomenon is termed "Multimodal Hallucination Snowballing".
- To mitigate this issue, the paper proposes a training-free method called Residual Visual Decoding, which can reduce the snowballed multimodal hallucination by more than 24% while maintaining the models' capabilities.
Plain English Explanation
Large Vision-Language Models (LVLMs) are powerful AI systems that can understand both visual information and human language. However, these models sometimes generate fake or irrelevant information, known as "multimodal hallucinations," during interactions that combine visual and language inputs.
The concern is that these hallucinations could then influence the model's subsequent responses, leading it to make incorrect claims or decisions, even when the correct visual information is available. To investigate this issue, the researchers developed a framework called MMHalSnowball that tests how LVLMs behave when presented with previously generated hallucinations.
The experiment found that the performance of popular open-source LVLMs dropped by at least 31% when they were confronted with their own generated hallucinations. This suggests that these models are prone to accepting and building upon the false information they create, a phenomenon the researchers call "Multimodal Hallucination Snowballing."
To address this problem, the researchers proposed a training-free method called Residual Visual Decoding. This approach revises the model's output to better align with the actual visual information, helping the LVLM stay grounded in reality and avoid being misled by its own hallucinations. Experiments show this method can mitigate more than 24% of the snowballed multimodal hallucination while maintaining the model's overall capabilities.
Technical Explanation
The paper investigates the issue of multimodal hallucinations in Large Vision-Language Models (LVLMs). Multimodal hallucinations occur when these models generate false or irrelevant information during interactions that combine visual and language inputs.
To understand how these hallucinations might influence the models' subsequent generation, the researchers developed a framework called MMHalSnowball. This framework curates a series of conversational exchanges where LVLMs are required to answer specific visual questions within a context of previously generated hallucinations.
The experiment showed that the performance of open-source LVLMs, such as CLIP and LXMERT, dropped by at least 31% when confronted with their own generated hallucinations. This indicates that the models are prone to accepting and building upon the false information they create, a phenomenon the researchers call "Multimodal Hallucination Snowballing."
To mitigate this issue, the researchers proposed a training-free method called Residual Visual Decoding. This approach revises the output distribution of the LVLMs with information derived from the residual visual input, providing the models with direct access to the actual visual information. Experiments demonstrate that this method can reduce the snowballed multimodal hallucination by more than 24% while maintaining the models' overall capabilities.
Critical Analysis
The paper provides valuable insights into the problem of multimodal hallucinations in Large Vision-Language Models (LVLMs) and proposes a promising solution to address it. However, the research also has some limitations and raises additional concerns:
-
Generalization: The experiment was conducted on a curated dataset and may not reflect how LVLMs would perform in real-world scenarios with more diverse and unpredictable inputs. Further research is needed to assess the generalizability of the findings.
-
Interpretability: The paper does not delve into the underlying mechanisms that lead to the "Multimodal Hallucination Snowballing" phenomenon. A deeper understanding of the cognitive processes involved could help develop more robust and transparent solutions.
-
Bias and Fairness: The paper does not address the potential biases that may be present in the training data or the models themselves, which could influence the generation of hallucinations and the subsequent responses. Addressing these issues is crucial for ensuring the fairness and reliability of LVLMs.
-
Broader Implications: The paper focuses on the technical aspects of the problem, but it would be valuable to explore the broader societal implications of multimodal hallucinations, especially in domains where these models are deployed, such as healthcare, education, or decision-making.
Overall, the paper presents a significant step forward in understanding and mitigating the challenges posed by multimodal hallucinations in LVLMs. However, further research and a more holistic approach are necessary to fully address the complexities and potential risks associated with these advanced AI systems.
Conclusion
The paper explores the issue of multimodal hallucinations in Large Vision-Language Models (LVLMs) and proposes a framework called MMHalSnowball to evaluate their behavior when confronted with generated hallucinations. The experiment reveals that open-source LVLMs are prone to accepting and building upon their own false information, a phenomenon termed "Multimodal Hallucination Snowballing."
To address this problem, the researchers introduce a training-free method called Residual Visual Decoding, which can mitigate more than 24% of the snowballed multimodal hallucination while maintaining the models' overall capabilities. This research highlights the importance of developing robust and reliable multimodal AI systems that can accurately integrate visual and language information to avoid the pitfalls of hallucination and maintain their grounding in reality.
As LVLMs continue to advance and be deployed in various applications, addressing the issue of multimodal hallucinations will be crucial to ensure the trustworthiness and safety of these powerful AI tools. The insights and solutions presented in this paper provide a valuable foundation for future research and development in this critical area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
0
0
This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
4/30/2024

A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
0
0
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
5/7/2024
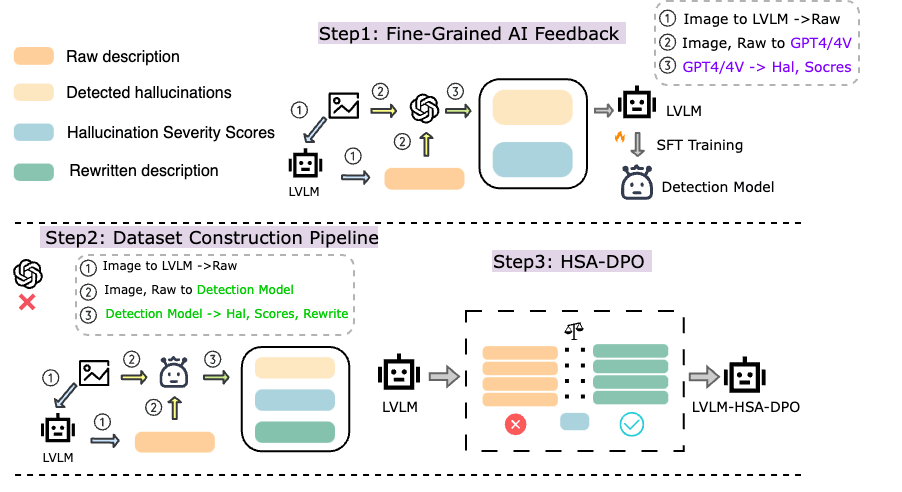
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
0
0
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
4/23/2024

Mitigating Dialogue Hallucination for Large Vision Language Models via Adversarial Instruction Tuning
Dongmin Park, Zhaofang Qian, Guangxing Han, Ser-Nam Lim
0
0
Mitigating hallucinations of Large Vision Language Models,(LVLMs) is crucial to enhance their reliability for general-purpose assistants. This paper shows that such hallucinations of LVLMs can be significantly exacerbated by preceding user-system dialogues. To precisely measure this, we first present an evaluation benchmark by extending popular multi-modal benchmark datasets with prepended hallucinatory dialogues powered by our novel Adversarial Question Generator (AQG), which can automatically generate image-related yet adversarial dialogues by adopting adversarial attacks on LVLMs. On our benchmark, the zero-shot performance of state-of-the-art LVLMs drops significantly for both the VQA and Captioning tasks. Next, we further reveal this hallucination is mainly due to the prediction bias toward preceding dialogues rather than visual content. To reduce this bias, we propose Adversarial Instruction Tuning (AIT) that robustly fine-tunes LVLMs against hallucinatory dialogues. Extensive experiments show our proposed approach successfully reduces dialogue hallucination while maintaining performance.
5/28/2024