Investigating and unmasking feature-level vulnerabilities of CNNs to adversarial perturbations

0

Sign in to get full access
Overview
- This paper investigates the feature-level vulnerabilities of Convolutional Neural Networks (CNNs) to adversarial perturbations.
- The researchers explore how different architectural modifications can impact the robustness of CNNs against adversarial attacks.
- They analyze the effect of adversarial perturbations on the internal feature representations of CNNs.
Plain English Explanation
Neural networks, like Convolutional Neural Networks (CNNs), are powerful machine learning models that can be fooled by small, carefully crafted changes to their inputs, known as adversarial perturbations. This paper dives into understanding why CNNs are vulnerable to these adversarial attacks by looking at the features the models learn.
The researchers explore how changes to the CNN architecture, such as adding new layers or modifying the network structure, can impact the model's robustness to adversarial attacks. They analyze how adversarial perturbations affect the internal representations, or features, that the CNN learns. This helps identify the specific vulnerabilities in the model's decision-making process that make it susceptible to adversarial attacks.
By understanding these feature-level vulnerabilities, the researchers aim to develop better defenses against adversarial attacks. This could lead to more secure and reliable AI systems, which is crucial as these models become more widely deployed in real-world applications, such as image recognition and text classification.
Technical Explanation
The paper begins by reviewing the related work on adversarial attacks and defenses for CNNs. The researchers then conduct experiments to investigate the feature-level vulnerabilities of CNNs to adversarial perturbations.
They use several CNN architectures, including VGG, ResNet, and DenseNet, and apply different adversarial attack methods, such as FGSM and PGD, to analyze the impact on the internal feature representations of the models.
The key insights from the experiments are:
- Adversarial perturbations can significantly alter the feature representations of CNNs, even when the models' final classifications remain unchanged.
- Certain architectural modifications, like increasing the model depth or adding skip connections, can help improve the robustness of CNNs against adversarial attacks by making the feature representations more stable.
- The researchers also identify specific features that are more vulnerable to adversarial perturbations, which could inform the development of more targeted defenses.
Critical Analysis
The paper provides valuable insights into the feature-level vulnerabilities of CNNs to adversarial attacks. However, the researchers acknowledge that their analysis is limited to the specific architectures and attack methods they investigated. Further research is needed to generalize these findings and explore the robustness of other model architectures and attack techniques.
Additionally, the paper does not address the potential trade-offs between improving adversarial robustness and model performance on standard benchmarks. It would be useful to understand how the architectural modifications that enhance robustness might impact the model's overall accuracy and efficiency.
Finally, the paper focuses on the technical aspects of the problem and does not discuss the broader implications of adversarial vulnerabilities in real-world AI applications. Exploring the societal and ethical considerations of these issues could be an important area for future research.
Conclusion
This paper offers a detailed investigation into the feature-level vulnerabilities of CNNs to adversarial perturbations. By understanding how architectural modifications can impact the robustness of these models, the researchers aim to pave the way for the development of more secure and reliable AI systems. As AI becomes increasingly prevalent in our daily lives, addressing these fundamental vulnerabilities is crucial to ensuring the trustworthiness and safety of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Investigating and unmasking feature-level vulnerabilities of CNNs to adversarial perturbations
Davide Coppola, Hwee Kuan Lee
This study explores the impact of adversarial perturbations on Convolutional Neural Networks (CNNs) with the aim of enhancing the understanding of their underlying mechanisms. Despite numerous defense methods proposed in the literature, there is still an incomplete understanding of this phenomenon. Instead of treating the entire model as vulnerable, we propose that specific feature maps learned during training contribute to the overall vulnerability. To investigate how the hidden representations learned by a CNN affect its vulnerability, we introduce the Adversarial Intervention framework. Experiments were conducted on models trained on three well-known computer vision datasets, subjecting them to attacks of different nature. Our focus centers on the effects that adversarial perturbations to a model's initial layer have on the overall behavior of the model. Empirical results revealed compelling insights: a) perturbing selected channel combinations in shallow layers causes significant disruptions; b) the channel combinations most responsible for the disruptions are common among different types of attacks; c) despite shared vulnerable combinations of channels, different attacks affect hidden representations with varying magnitudes; d) there exists a positive correlation between a kernel's magnitude and its vulnerability. In conclusion, this work introduces a novel framework to study the vulnerability of a CNN model to adversarial perturbations, revealing insights that contribute to a deeper understanding of the phenomenon. The identified properties pave the way for the development of efficient ad-hoc defense mechanisms in future applications.
Read more6/3/2024
🧠
0
Fight Perturbations with Perturbations: Defending Adversarial Attacks via Neuron Influence
Ruoxi Chen, Haibo Jin, Haibin Zheng, Jinyin Chen, Zhenguang Liu
The vulnerabilities of deep learning models towards adversarial attacks have attracted increasing attention, especially when models are deployed in security-critical domains. Numerous defense methods, including reactive and proactive ones, have been proposed for model robustness improvement. Reactive defenses, such as conducting transformations to remove perturbations, usually fail to handle large perturbations. The proactive defenses that involve retraining, suffer from the attack dependency and high computation cost. In this paper, we consider defense methods from the general effect of adversarial attacks that take on neurons inside the model. We introduce the concept of neuron influence, which can quantitatively measure neurons' contribution to correct classification. Then, we observe that almost all attacks fool the model by suppressing neurons with larger influence and enhancing those with smaller influence. Based on this, we propose emph{Neuron-level Inverse Perturbation} (NIP), a novel defense against general adversarial attacks. It calculates neuron influence from benign examples and then modifies input examples by generating inverse perturbations that can in turn strengthen neurons with larger influence and weaken those with smaller influence.
Read more8/21/2024
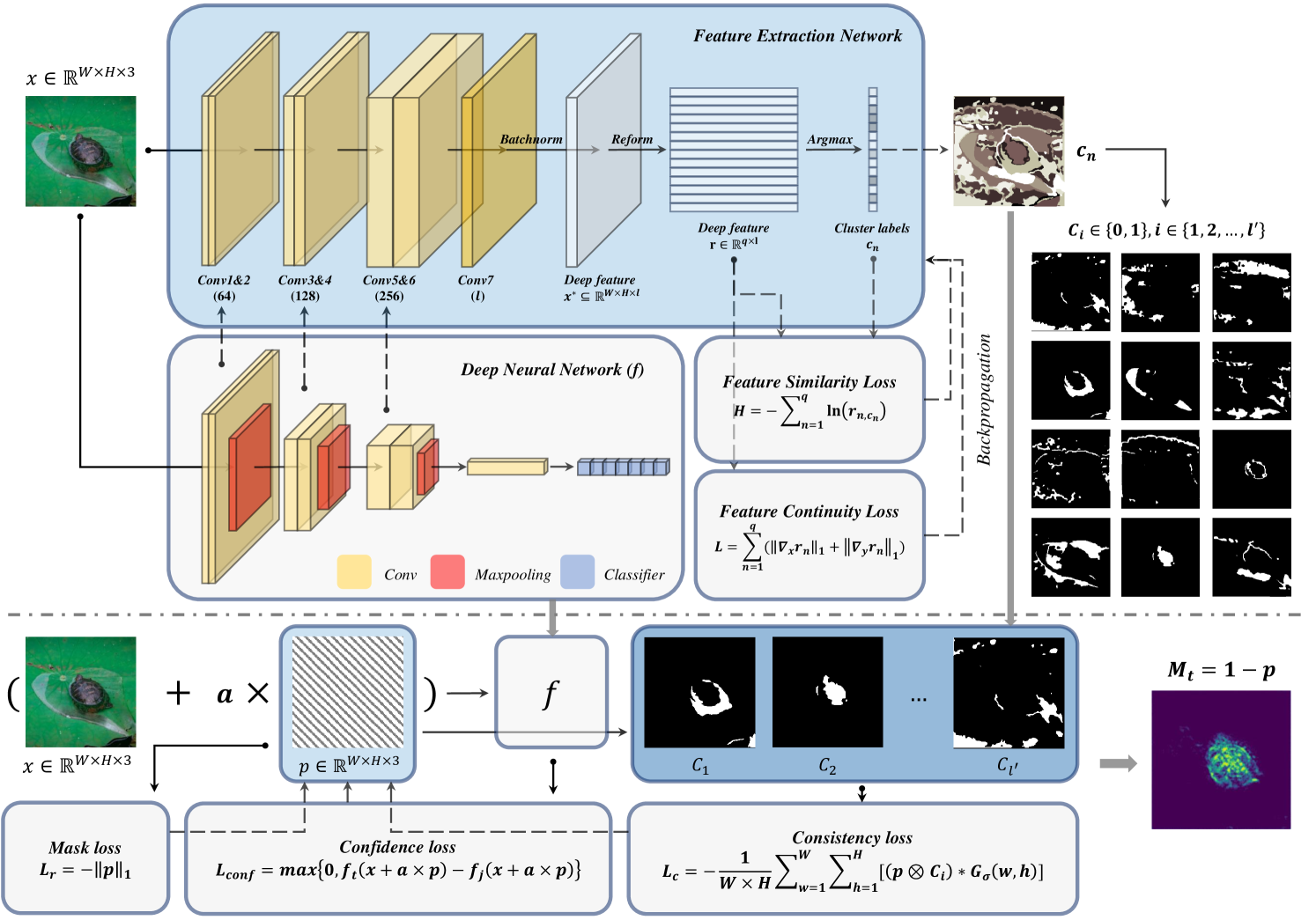
0
Perturbation on Feature Coalition: Towards Interpretable Deep Neural Networks
Xuran Hu, Mingzhe Zhu, Zhenpeng Feng, Milov{s} Dakovi'c, Ljubiv{s}a Stankovi'c
The inherent black box nature of deep neural networks (DNNs) compromises their transparency and reliability. Recently, explainable AI (XAI) has garnered increasing attention from researchers. Several perturbation-based interpretations have emerged. However, these methods often fail to adequately consider feature dependencies. To solve this problem, we introduce a perturbation-based interpretation guided by feature coalitions, which leverages deep information of network to extract correlated features. Then, we proposed a carefully-designed consistency loss to guide network interpretation. Both quantitative and qualitative experiments are conducted to validate the effectiveness of our proposed method. Code is available at github.com/Teriri1999/Perturebation-on-Feature-Coalition.
Read more8/27/2024

0
From Feature Visualization to Visual Circuits: Effect of Adversarial Model Manipulation
Geraldin Nanfack, Michael Eickenberg, Eugene Belilovsky
Understanding the inner working functionality of large-scale deep neural networks is challenging yet crucial in several high-stakes applications. Mechanistic inter- pretability is an emergent field that tackles this challenge, often by identifying human-understandable subgraphs in deep neural networks known as circuits. In vision-pretrained models, these subgraphs are usually interpreted by visualizing their node features through a popular technique called feature visualization. Recent works have analyzed the stability of different feature visualization types under the adversarial model manipulation framework. This paper starts by addressing limitations in existing works by proposing a novel attack called ProxPulse that simultaneously manipulates the two types of feature visualizations. Surprisingly, when analyzing these attacks under the umbrella of visual circuits, we find that visual circuits show some robustness to ProxPulse. We, therefore, introduce a new attack based on ProxPulse that unveils the manipulability of visual circuits, shedding light on their lack of robustness. The effectiveness of these attacks is validated using pre-trained AlexNet and ResNet-50 models on ImageNet.
Read more6/4/2024