Perturbation on Feature Coalition: Towards Interpretable Deep Neural Networks

0
Sign in to get full access
Overview
- Explores a perturbation-based approach to interpret deep neural networks
- Focuses on understanding how feature interactions contribute to model predictions
- Aims to provide more interpretable and trustworthy AI systems
Plain English Explanation
Deep neural networks are powerful machine learning models that can achieve impressive results, but they are often criticized for being "black boxes" - it's difficult to understand how they make their predictions. This paper presents a new method to interpret deep neural networks by analyzing how changes to the input features (pixels, text, etc.) affect the model's output.
The key idea is to systematically perturb or slightly modify the input features and observe the impact on the model's predictions. By looking at which feature changes have the biggest effect, the researchers can identify the most important feature interactions driving the model's behavior.
This provides a way to "open up the black box" and better understand how deep neural networks work under the hood. The goal is to develop more interpretable and trustworthy AI systems that can explain their reasoning in a way that humans can comprehend.
Technical Explanation
The paper proposes a perturbation-based interpretation method for deep neural networks. The core idea is to systematically perturb the input features and measure the impact on the model's output. This allows the researchers to identify the most important feature interactions that contribute to the model's predictions.
Specifically, the method involves:
- Selecting a subset of input features to perturb
- Generating perturbed versions of the input by modifying those features
- Feeding the perturbed inputs into the model and recording the changes in output
- Analyzing the feature perturbations that have the biggest impact on the model's predictions
By repeating this process for different feature subsets, the researchers can build up an understanding of the complex, higher-order feature interactions that the model has learned.
The paper demonstrates the effectiveness of this approach through experiments on image classification and text sentiment analysis tasks. The results show that the perturbation-based interpretations provide meaningful insights into the model's decision-making process, which could help build more trustworthy and explainable AI systems.
Critical Analysis
The paper presents a promising approach for interpreting deep neural networks, but there are some potential limitations and areas for further research:
- The perturbation-based method relies on the assumption that modifying individual features or feature subsets will reveal the model's underlying reasoning. However, deep neural networks can learn complex, non-linear relationships that may not be easily decomposed in this way.
- The interpretation process can be computationally intensive, as it requires generating and evaluating many perturbed inputs. This may limit the scalability of the approach, especially for large and complex models.
- The paper focuses on understanding feature interactions, but it does not address other aspects of model interpretability, such as the role of different layers or the importance of specific neurons within the network.
- The experiments in the paper are conducted on relatively simple tasks (image classification, text sentiment analysis). It remains to be seen how well the perturbation-based approach will generalize to more complex, real-world applications.
Despite these limitations, the paper makes an important contribution to the field of explainable AI by introducing a principled method for understanding the inner workings of deep neural networks. Further research and development in this area could lead to more transparent and trustworthy AI systems.
Conclusion
This paper presents a novel perturbation-based approach for interpreting deep neural networks. By systematically modifying input features and observing the impact on model outputs, the researchers can gain insights into the complex feature interactions that drive the model's decision-making process.
The proposed method represents an important step towards developing more interpretable and trustworthy AI systems. While the approach has some limitations and areas for further research, it demonstrates the potential of perturbation-based techniques to "open up the black box" of deep neural networks and make their inner workings more transparent and understandable.
As the adoption of AI systems continues to grow, the ability to explain and justify their decisions will become increasingly crucial. The work presented in this paper contributes to the ongoing efforts to make AI more explainable and reliable, which could have significant implications for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Perturbation on Feature Coalition: Towards Interpretable Deep Neural Networks
Xuran Hu, Mingzhe Zhu, Zhenpeng Feng, Milov{s} Dakovi'c, Ljubiv{s}a Stankovi'c
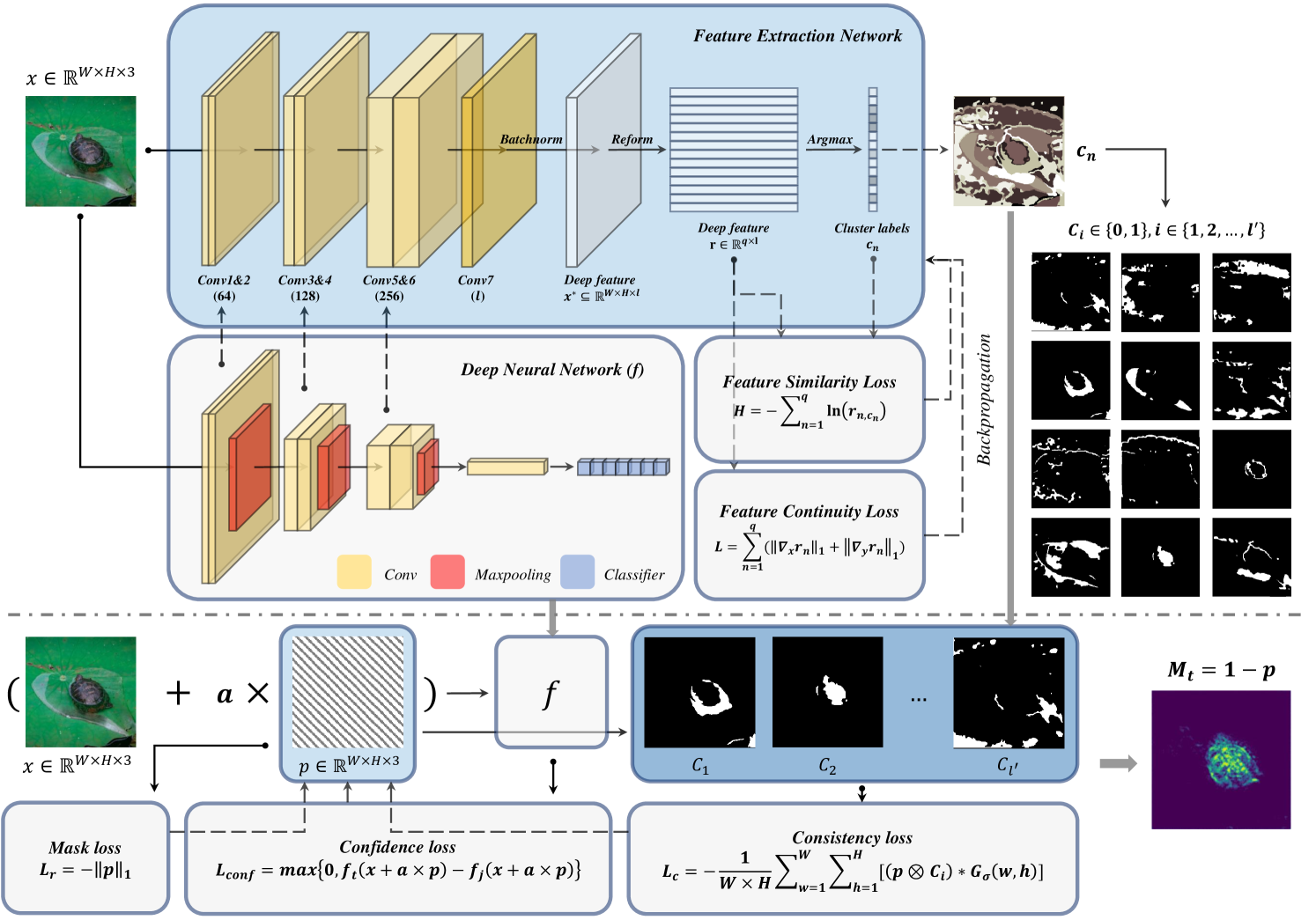
The inherent black box nature of deep neural networks (DNNs) compromises their transparency and reliability. Recently, explainable AI (XAI) has garnered increasing attention from researchers. Several perturbation-based interpretations have emerged. However, these methods often fail to adequately consider feature dependencies. To solve this problem, we introduce a perturbation-based interpretation guided by feature coalitions, which leverages deep information of network to extract correlated features. Then, we proposed a carefully-designed consistency loss to guide network interpretation. Both quantitative and qualitative experiments are conducted to validate the effectiveness of our proposed method. Code is available at github.com/Teriri1999/Perturebation-on-Feature-Coalition.
Read more8/27/2024

0
Unified Explanations in Machine Learning Models: A Perturbation Approach
Jacob Dineen, Don Kridel, Daniel Dolk, David Castillo
A high-velocity paradigm shift towards Explainable Artificial Intelligence (XAI) has emerged in recent years. Highly complex Machine Learning (ML) models have flourished in many tasks of intelligence, and the questions have started to shift away from traditional metrics of validity towards something deeper: What is this model telling me about my data, and how is it arriving at these conclusions? Inconsistencies between XAI and modeling techniques can have the undesirable effect of casting doubt upon the efficacy of these explainability approaches. To address these problems, we propose a systematic, perturbation-based analysis against a popular, model-agnostic method in XAI, SHapley Additive exPlanations (Shap). We devise algorithms to generate relative feature importance in settings of dynamic inference amongst a suite of popular machine learning and deep learning methods, and metrics that allow us to quantify how well explanations generated under the static case hold. We propose a taxonomy for feature importance methodology, measure alignment, and observe quantifiable similarity amongst explanation models across several datasets.
Read more5/31/2024

0
Investigating and unmasking feature-level vulnerabilities of CNNs to adversarial perturbations
Davide Coppola, Hwee Kuan Lee
This study explores the impact of adversarial perturbations on Convolutional Neural Networks (CNNs) with the aim of enhancing the understanding of their underlying mechanisms. Despite numerous defense methods proposed in the literature, there is still an incomplete understanding of this phenomenon. Instead of treating the entire model as vulnerable, we propose that specific feature maps learned during training contribute to the overall vulnerability. To investigate how the hidden representations learned by a CNN affect its vulnerability, we introduce the Adversarial Intervention framework. Experiments were conducted on models trained on three well-known computer vision datasets, subjecting them to attacks of different nature. Our focus centers on the effects that adversarial perturbations to a model's initial layer have on the overall behavior of the model. Empirical results revealed compelling insights: a) perturbing selected channel combinations in shallow layers causes significant disruptions; b) the channel combinations most responsible for the disruptions are common among different types of attacks; c) despite shared vulnerable combinations of channels, different attacks affect hidden representations with varying magnitudes; d) there exists a positive correlation between a kernel's magnitude and its vulnerability. In conclusion, this work introduces a novel framework to study the vulnerability of a CNN model to adversarial perturbations, revealing insights that contribute to a deeper understanding of the phenomenon. The identified properties pave the way for the development of efficient ad-hoc defense mechanisms in future applications.
Read more6/3/2024

0
Can you trust your explanations? A robustness test for feature attribution methods
Ilaria Vascotto, Alex Rodriguez, Alessandro Bonaita, Luca Bortolussi
The increase of legislative concerns towards the usage of Artificial Intelligence (AI) has recently led to a series of regulations striving for a more transparent, trustworthy and accountable AI. Along with these proposals, the field of Explainable AI (XAI) has seen a rapid growth but the usage of its techniques has at times led to unexpected results. The robustness of the approaches is, in fact, a key property often overlooked: it is necessary to evaluate the stability of an explanation (to random and adversarial perturbations) to ensure that the results are trustable. To this end, we propose a test to evaluate the robustness to non-adversarial perturbations and an ensemble approach to analyse more in depth the robustness of XAI methods applied to neural networks and tabular datasets. We will show how leveraging manifold hypothesis and ensemble approaches can be beneficial to an in-depth analysis of the robustness.
Read more6/21/2024