An Investigation of Noise Robustness for Flow-Matching-Based Zero-Shot TTS

0
💬
Sign in to get full access
Overview
- This paper investigates the noise robustness of a flow-matching-based zero-shot text-to-speech (TTS) system.
- Zero-shot TTS aims to generate high-quality speech for new speakers without requiring any speaker-specific training data.
- The proposed approach leverages flow-matching, a technique for generating audio from text, to enable zero-shot TTS.
- The paper examines how this flow-matching-based zero-shot TTS system performs in the presence of various types of noise, which is an important real-world consideration for practical deployment.
Plain English Explanation
The paper looks at a type of text-to-speech (TTS) system that can generate high-quality speech for new speakers without needing any special training data for those speakers. This is known as "zero-shot" TTS, and it works by using a technique called "flow-matching" to convert text into audio.
The researchers wanted to see how well this zero-shot TTS system holds up when there is background noise, like in a real-world environment. They tested it with different kinds of noise to see how robust the system is and where it might struggle. This is an important consideration for making these TTS systems practical and usable in the real world, where noise is often a problem.
Technical Explanation
The paper investigates the noise robustness of a flow-matching-based zero-shot text-to-speech (TTS) system. Zero-shot TTS aims to generate high-quality speech for new speakers without requiring any speaker-specific training data, which is achieved by leveraging flow-matching techniques.
The proposed approach utilizes a flow-matching network to convert text into audio, enabling zero-shot TTS capabilities. The authors evaluate the noise robustness of this flow-matching-based zero-shot TTS system by assessing its performance in the presence of various types of noise, including additive white Gaussian noise, music, and babble noise.
The experiments demonstrate the impact of these different noise conditions on the zero-shot TTS system's ability to generate intelligible and natural-sounding speech. The findings provide insights into the strengths and limitations of the flow-matching-based approach for zero-shot TTS in real-world, noisy environments.
Critical Analysis
The paper provides a thorough investigation into the noise robustness of a flow-matching-based zero-shot TTS system, which is a crucial consideration for practical deployment. However, the authors acknowledge that the study is limited to a specific set of noise conditions and does not explore the system's performance under more complex, real-world environmental factors.
Additionally, the paper does not delve into potential strategies for improving the noise robustness of the flow-matching-based zero-shot TTS approach. Further research could explore techniques such as data augmentation, multi-task learning, or adaptive normalization to enhance the system's resilience to various noise conditions.
Conclusion
This paper provides a valuable investigation into the noise robustness of a flow-matching-based zero-shot TTS system. The findings offer insights into the strengths and limitations of this approach, highlighting the importance of considering real-world noise conditions for practical TTS applications. While the study is limited in scope, it sets the stage for further research into improving the noise resilience of zero-shot TTS systems, which could lead to more robust and reliable speech synthesis solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
An Investigation of Noise Robustness for Flow-Matching-Based Zero-Shot TTS
Xiaofei Wang, Sefik Emre Eskimez, Manthan Thakker, Hemin Yang, Zirun Zhu, Min Tang, Yufei Xia, Jinzhu Li, Sheng Zhao, Jinyu Li, Naoyuki Kanda
Recently, zero-shot text-to-speech (TTS) systems, capable of synthesizing any speaker's voice from a short audio prompt, have made rapid advancements. However, the quality of the generated speech significantly deteriorates when the audio prompt contains noise, and limited research has been conducted to address this issue. In this paper, we explored various strategies to enhance the quality of audio generated from noisy audio prompts within the context of flow-matching-based zero-shot TTS. Our investigation includes comprehensive training strategies: unsupervised pre-training with masked speech denoising, multi-speaker detection and DNSMOS-based data filtering on the pre-training data, and fine-tuning with random noise mixing. The results of our experiments demonstrate significant improvements in intelligibility, speaker similarity, and overall audio quality compared to the approach of applying speech enhancement to the audio prompt.
Read more6/11/2024

0
Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
Read more4/10/2024
🗣️
0
Mega-TTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
Ziyue Jiang, Jinglin Liu, Yi Ren, Jinzheng He, Zhenhui Ye, Shengpeng Ji, Qian Yang, Chen Zhang, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun Ma, Zhou Zhao
Zero-shot text-to-speech (TTS) aims to synthesize voices with unseen speech prompts, which significantly reduces the data and computation requirements for voice cloning by skipping the fine-tuning process. However, the prompting mechanisms of zero-shot TTS still face challenges in the following aspects: 1) previous works of zero-shot TTS are typically trained with single-sentence prompts, which significantly restricts their performance when the data is relatively sufficient during the inference stage. 2) The prosodic information in prompts is highly coupled with timbre, making it untransferable to each other. This paper introduces Mega-TTS 2, a generic prompting mechanism for zero-shot TTS, to tackle the aforementioned challenges. Specifically, we design a powerful acoustic autoencoder that separately encodes the prosody and timbre information into the compressed latent space while providing high-quality reconstructions. Then, we propose a multi-reference timbre encoder and a prosody latent language model (P-LLM) to extract useful information from multi-sentence prompts. We further leverage the probabilities derived from multiple P-LLM outputs to produce transferable and controllable prosody. Experimental results demonstrate that Mega-TTS 2 could not only synthesize identity-preserving speech with a short prompt of an unseen speaker from arbitrary sources but consistently outperform the fine-tuning method when the volume of data ranges from 10 seconds to 5 minutes. Furthermore, our method enables to transfer various speaking styles to the target timbre in a fine-grained and controlled manner. Audio samples can be found in https://boostprompt.github.io/boostprompt/.
Read more4/11/2024
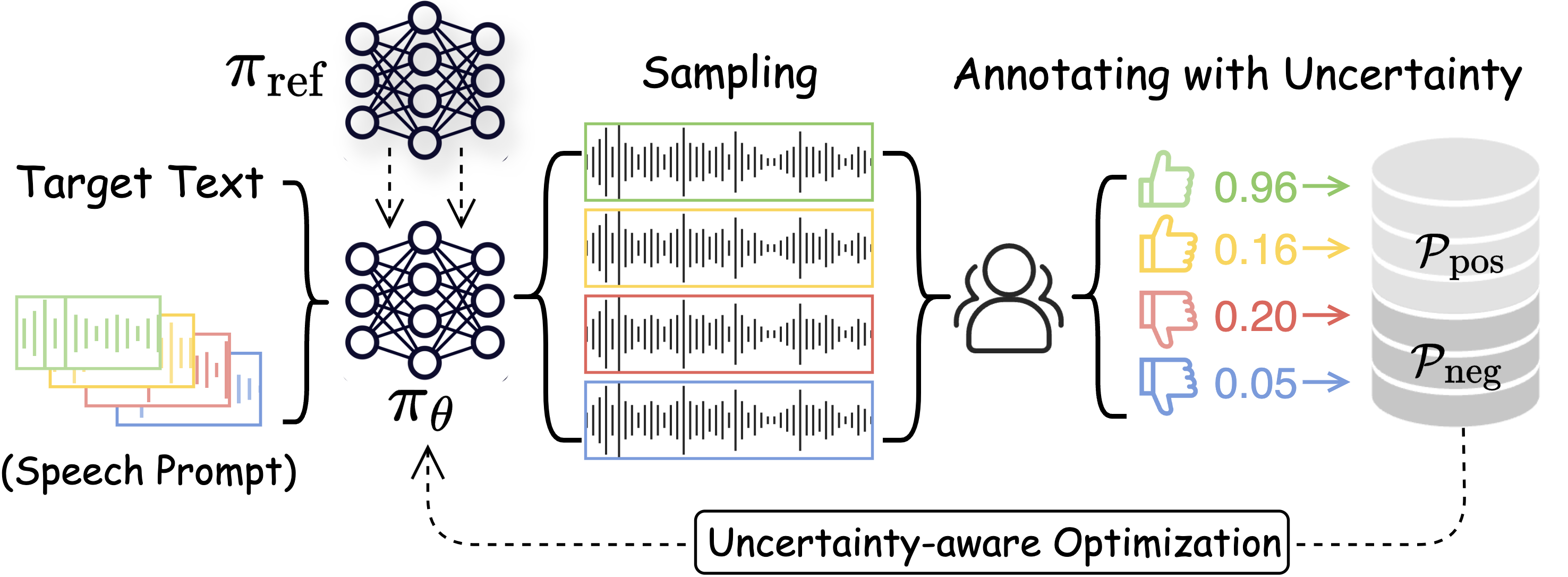
0
Enhancing Zero-shot Text-to-Speech Synthesis with Human Feedback
Chen Chen, Yuchen Hu, Wen Wu, Helin Wang, Eng Siong Chng, Chao Zhang
In recent years, text-to-speech (TTS) technology has witnessed impressive advancements, particularly with large-scale training datasets, showcasing human-level speech quality and impressive zero-shot capabilities on unseen speakers. However, despite human subjective evaluations, such as the mean opinion score (MOS), remaining the gold standard for assessing the quality of synthetic speech, even state-of-the-art TTS approaches have kept human feedback isolated from training that resulted in mismatched training objectives and evaluation metrics. In this work, we investigate a novel topic of integrating subjective human evaluation into the TTS training loop. Inspired by the recent success of reinforcement learning from human feedback, we propose a comprehensive sampling-annotating-learning framework tailored to TTS optimization, namely uncertainty-aware optimization (UNO). Specifically, UNO eliminates the need for a reward model or preference data by directly maximizing the utility of speech generations while considering the uncertainty that lies in the inherent variability in subjective human speech perception and evaluations. Experimental results of both subjective and objective evaluations demonstrate that UNO considerably improves the zero-shot performance of TTS models in terms of MOS, word error rate, and speaker similarity. Additionally, we present a remarkable ability of UNO that it can adapt to the desired speaking style in emotional TTS seamlessly and flexibly.
Read more6/4/2024