Is Learning in Biological Neural Networks based on Stochastic Gradient Descent? An analysis using stochastic processes
2309.05102
0
0
🧠
Abstract
In recent years, there has been an intense debate about how learning in biological neural networks (BNNs) differs from learning in artificial neural networks. It is often argued that the updating of connections in the brain relies only on local information, and therefore a stochastic gradient-descent type optimization method cannot be used. In this paper, we study a stochastic model for supervised learning in BNNs. We show that a (continuous) gradient step occurs approximately when each learning opportunity is processed by many local updates. This result suggests that stochastic gradient descent may indeed play a role in optimizing BNNs.
Create account to get full access
Overview
- This paper explores the differences between how learning occurs in biological neural networks (BNNs) and artificial neural networks (ANNs).
- It is often argued that the brain's learning process relies on local information only, and cannot use the global optimization method of stochastic gradient descent.
- The paper presents a stochastic model for supervised learning in BNNs and shows that a gradient-like step occurs when many local updates are processed.
- This suggests that stochastic gradient descent may indeed play a role in optimizing learning in BNNs.
Plain English Explanation
The human brain is often compared to artificial neural networks (ANNs), which are computer systems inspired by the brain's structure and function. However, there are important differences in how learning occurs in biological neural networks (BNNs) and ANNs.
One key difference is that the brain's learning process is thought to rely on local information only, meaning the connections between neurons are updated based on information available within a small, localized area. In contrast, ANNs use a global optimization method called stochastic gradient descent, which requires information about the entire network to update the connections.
This paper explores whether stochastic gradient descent could still play a role in learning within BNNs, despite the apparent reliance on local information. The researchers developed a stochastic model for supervised learning in BNNs and found that a gradient-like step can occur when many local updates are processed. This suggests that the brain may be able to approximate the effects of stochastic gradient descent through its local learning mechanisms.
This is an important finding because it helps bridge the gap between how learning happens in biological and artificial neural networks. It indicates that the brain's learning process may be more similar to the optimization methods used in machine learning than previously thought. This could have implications for understanding the brain and for the development of more biologically inspired artificial intelligence systems.
Technical Explanation
The paper presents a stochastic model for supervised learning in biological neural networks (BNNs). The key premise is that while it is often argued that BNN learning relies only on local information and cannot use global optimization methods like stochastic gradient descent, the authors hypothesize that gradient-like steps may still emerge through the accumulation of many local updates.
To test this, the researchers developed a stochastic model of BNN learning, where each "learning opportunity" involves a sequence of many local updates to the connections between neurons. They show that under certain conditions, these local updates can approximately generate a (continuous) gradient step, similar to what is observed in stochastic gradient descent optimization in artificial neural networks (ANNs).
The key insight is that while individual local updates in the BNN model may not directly correspond to a gradient step, the aggregate effect of processing many learning opportunities can converge towards a gradient-like update. This suggests that the brain's learning mechanisms may be able to approximate the optimization behavior of stochastic gradient descent, even if the underlying process relies entirely on local information.
The authors validate their model through numerical simulations and provide theoretical analysis to characterize the conditions under which this gradient-like behavior emerges. This work contributes to our understanding of learning in biological systems and may inform the design of more biologically plausible artificial intelligence systems.
Critical Analysis
The paper presents a compelling argument that stochastic gradient descent-like behavior can emerge from the local learning mechanisms of biological neural networks (BNNs). However, there are some important caveats and limitations to consider.
Firstly, the model makes several simplifying assumptions, such as having a relatively simple learning rule and considering only supervised learning scenarios. In the real brain, the learning process is likely much more complex, involving various neuromodulatory signals, unsupervised learning, and more intricate synaptic update rules.
Additionally, the authors acknowledge that their analysis focuses on the average or expected behavior of the system, rather than the dynamics of individual learning events. The extent to which the brain's learning truly approximates stochastic gradient descent on a case-by-case basis remains an open question.
It's also worth noting that even if the brain's learning process can be shown to have gradient-like properties, this does not necessarily imply that the same optimization techniques used in artificial neural networks would be optimal for biological neural networks. The brain may have evolved specialized learning mechanisms that diverge from the standard approaches in machine learning.
Despite these limitations, this work represents an important step towards bridging the gap between biological and artificial neural networks. By exploring the commonalities and differences in their learning processes, we can gain deeper insights into the principles of intelligence and potentially inspire new approaches to artificial intelligence.
Conclusion
This paper presents a stochastic model for supervised learning in biological neural networks (BNNs) that suggests the brain's learning process may be able to approximate the effects of stochastic gradient descent, despite the common belief that BNN learning relies only on local information.
The key finding is that while individual local updates in the BNN model may not directly correspond to a gradient step, the aggregate effect of processing many learning opportunities can converge towards a gradient-like update. This implies that the brain's learning mechanisms may be more similar to the optimization techniques used in artificial neural networks than previously thought.
This work contributes to our understanding of learning in biological systems and may inform the design of more biologically plausible artificial intelligence systems. However, it also highlights the need for further research to fully characterize the complexity of learning in the brain and how it compares to the methods used in machine learning.
Overall, this paper represents an important step towards bridging the gap between biological and artificial neural networks, and encourages us to think more deeply about the principles of intelligence and how they may be reflected in both natural and artificial systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
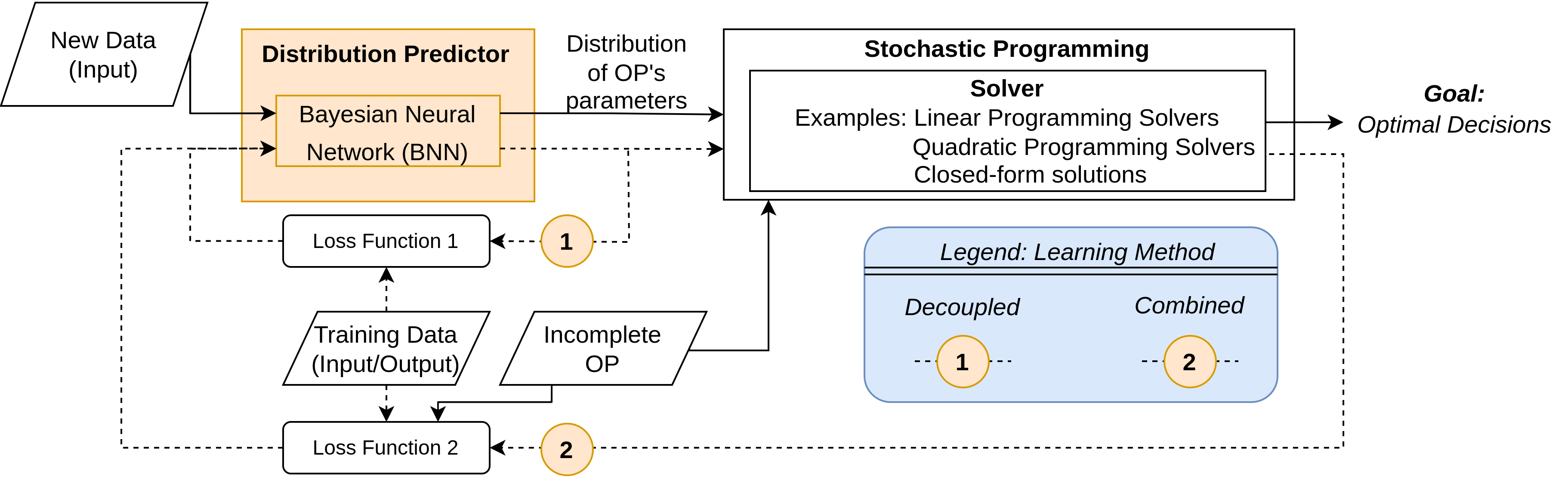
Learning Solutions of Stochastic Optimization Problems with Bayesian Neural Networks
Alan A. Lahoud, Erik Schaffernicht, Johannes A. Stork
0
0
Mathematical solvers use parametrized Optimization Problems (OPs) as inputs to yield optimal decisions. In many real-world settings, some of these parameters are unknown or uncertain. Recent research focuses on predicting the value of these unknown parameters using available contextual features, aiming to decrease decision regret by adopting end-to-end learning approaches. However, these approaches disregard prediction uncertainty and therefore make the mathematical solver susceptible to provide erroneous decisions in case of low-confidence predictions. We propose a novel framework that models prediction uncertainty with Bayesian Neural Networks (BNNs) and propagates this uncertainty into the mathematical solver with a Stochastic Programming technique. The differentiable nature of BNNs and differentiable mathematical solvers allow for two different learning approaches: In the Decoupled learning approach, we update the BNN weights to increase the quality of the predictions' distribution of the OP parameters, while in the Combined learning approach, we update the weights aiming to directly minimize the expected OP's cost function in a stochastic end-to-end fashion. We do an extensive evaluation using synthetic data with various noise properties and a real dataset, showing that decisions regret are generally lower (better) with both proposed methods.
6/6/2024
🧠
A Study of Bayesian Neural Network Surrogates for Bayesian Optimization
Yucen Lily Li, Tim G. J. Rudner, Andrew Gordon Wilson
0
0
Bayesian optimization is a highly efficient approach to optimizing objective functions which are expensive to query. These objectives are typically represented by Gaussian process (GP) surrogate models which are easy to optimize and support exact inference. While standard GP surrogates have been well-established in Bayesian optimization, Bayesian neural networks (BNNs) have recently become practical function approximators, with many benefits over standard GPs such as the ability to naturally handle non-stationarity and learn representations for high-dimensional data. In this paper, we study BNNs as alternatives to standard GP surrogates for optimization. We consider a variety of approximate inference procedures for finite-width BNNs, including high-quality Hamiltonian Monte Carlo, low-cost stochastic MCMC, and heuristics such as deep ensembles. We also consider infinite-width BNNs, linearized Laplace approximations, and partially stochastic models such as deep kernel learning. We evaluate this collection of surrogate models on diverse problems with varying dimensionality, number of objectives, non-stationarity, and discrete and continuous inputs. We find: (i) the ranking of methods is highly problem dependent, suggesting the need for tailored inductive biases; (ii) HMC is the most successful approximate inference procedure for fully stochastic BNNs; (iii) full stochasticity may be unnecessary as deep kernel learning is relatively competitive; (iv) deep ensembles perform relatively poorly; (v) infinite-width BNNs are particularly promising, especially in high dimensions.
5/9/2024
🧠
Toward stochastic neural computing
Yang Qi, Zhichao Zhu, Yiming Wei, Lu Cao, Zhigang Wang, Jie Zhang, Wenlian Lu, Jianfeng Feng
0
0
The highly irregular spiking activity of cortical neurons and behavioral variability suggest that the brain could operate in a fundamentally probabilistic way. Mimicking how the brain implements and learns probabilistic computation could be a key to developing machine intelligence that can think more like humans. In this work, we propose a theory of stochastic neural computing (SNC) in which streams of noisy inputs are transformed and processed through populations of nonlinearly coupled spiking neurons. To account for the propagation of correlated neural variability, we derive from first principles a moment embedding for spiking neural network (SNN). This leads to a new class of deep learning model called the moment neural network (MNN) which naturally generalizes rate-based neural networks to second order. As the MNN faithfully captures the stationary statistics of spiking neural activity, it can serve as a powerful proxy for training SNN with zero free parameters. Through joint manipulation of mean firing rate and noise correlations in a task-driven way, the model is able to learn inference tasks while simultaneously minimizing prediction uncertainty, resulting in enhanced inference speed. We further demonstrate the application of our method to Intel's Loihi neuromorphic hardware. The proposed theory of SNC may open up new opportunities for developing machine intelligence capable of computing uncertainty and for designing unconventional computing architectures.
4/23/2024
Towards Learning Stochastic Population Models by Gradient Descent
Justin N. Kreikemeyer, Philipp Andelfinger, Adelinde M. Uhrmacher
0
0
Increasing effort is put into the development of methods for learning mechanistic models from data. This task entails not only the accurate estimation of parameters but also a suitable model structure. Recent work on the discovery of dynamical systems formulates this problem as a linear equation system. Here, we explore several simulation-based optimization approaches, which allow much greater freedom in the objective formulation and weaker conditions on the available data. We show that even for relatively small stochastic population models, simultaneous estimation of parameters and structure poses major challenges for optimization procedures. Particularly, we investigate the application of the local stochastic gradient descent method, commonly used for training machine learning models. We demonstrate accurate estimation of models but find that enforcing the inference of parsimonious, interpretable models drastically increases the difficulty. We give an outlook on how this challenge can be overcome.
7/1/2024