Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models
2406.14852
0
0

Abstract
Large language models (LLMs) and vision-language models (VLMs) have demonstrated remarkable performance across a wide range of tasks and domains. Despite this promise, spatial understanding and reasoning -- a fundamental component of human cognition -- remains under-explored. We develop novel benchmarks that cover diverse aspects of spatial reasoning such as relationship understanding, navigation, and counting. We conduct a comprehensive evaluation of competitive language and vision-language models. Our findings reveal several counter-intuitive insights that have been overlooked in the literature: (1) Spatial reasoning poses significant challenges where competitive models can fall behind random guessing; (2) Despite additional visual input, VLMs often under-perform compared to their LLM counterparts; (3) When both textual and visual information is available, multi-modal language models become less reliant on visual information if sufficient textual clues are provided. Additionally, we demonstrate that leveraging redundancy between vision and text can significantly enhance model performance. We hope our study will inform the development of multimodal models to improve spatial intelligence and further close the gap with human intelligence.
Create account to get full access
Overview
- This paper investigates the role of spatial reasoning in Vision-Language Models (VLMs), which are AI systems that can interpret and describe visual content.
- The researchers explore whether VLMs can truly understand and reason about the spatial relationships between objects in images, or if they rely primarily on textual associations.
- The paper presents several experiments and analyses to assess the spatial reasoning capabilities of various VLM architectures.
Plain English Explanation
Vision-Language Models (VLMs) are AI systems that can analyze images and describe what they see in natural language. These models have become increasingly sophisticated, but it's not always clear how they truly "understand" the visual world.
One key question is whether VLMs can reason about the spatial relationships between objects in an image, or if they simply rely on textual associations learned from language data. For example, can a VLM understand that a "book" is typically "on" a "table", rather than just recognizing those individual objects?
This paper delves into this issue, running a series of experiments to test the spatial reasoning abilities of different VLM architectures. The researchers use specialized datasets and tasks to assess how well the models can grasp concepts like object positions, sizes, and interactions.
By investigating the inner workings of VLMs, the authors aim to shed light on the models' true capabilities and limitations when it comes to understanding the spatial nature of the visual world. This could have important implications for how we design and apply these powerful AI systems in the future.
Technical Explanation
The paper begins by reviewing relevant prior work in the fields of spatial reasoning and Vision-Language Models. The authors note that while VLMs have shown impressive performance on various tasks, their underlying spatial reasoning abilities are not well understood.
To investigate this, the researchers conduct several experiments using specialized datasets and benchmarks, including:
- The Minds-Eye dataset, which tests how well models can reason about the spatial relationships between objects.
- The GSR-Bench benchmark, which evaluates models' ability to localize and reason about objects in 3D scenes.
The paper analyzes the performance of different VLM architectures, including CLIP, ViLT, and LXMERT, on these spatial reasoning tasks. The results suggest that while the models can perform well on some tasks, they may still struggle with more complex spatial reasoning, particularly when the visual information is limited.
Critical Analysis
The paper provides a thoughtful and thorough investigation of the spatial reasoning capabilities of VLMs. The researchers use well-designed experiments and established benchmarks to rigorously assess the models' abilities, which gives the findings a high degree of credibility.
However, the paper also acknowledges several limitations and areas for further research. For example, the experiments focus on relatively simple spatial reasoning tasks, and it's unclear how the models would perform on more complex, real-world scenarios. Additionally, the paper does not delve into the specific reasons why some VLM architectures may struggle with spatial reasoning, which could be a fruitful area for future work.
Moreover, while the paper raises important questions about the limitations of current VLMs, it does not necessarily challenge the overall value or potential of these models. As the authors note, large language models can create new knowledge, and further advancements in spatial reasoning may unlock even more capabilities.
Conclusion
This paper makes a valuable contribution to our understanding of the spatial reasoning abilities of Vision-Language Models. By rigorously testing the performance of various VLM architectures on specialized tasks, the researchers shed light on the models' strengths and weaknesses when it comes to reasoning about the spatial relationships between objects.
The findings suggest that while VLMs can excel at many tasks, they may still struggle with more complex spatial reasoning, particularly when visual information is limited. This highlights the importance of continued research and development in this area, as improving spatial reasoning could unlock new capabilities and applications for these powerful AI systems.
Overall, the paper provides a thoughtful and well-designed exploration of an important issue in the field of Vision-Language Models, with implications for the future of AI and its ability to truly understand and reason about the visual world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
Wenshan Wu, Shaoguang Mao, Yadong Zhang, Yan Xia, Li Dong, Lei Cui, Furu Wei
0
0
Large language models (LLMs) have exhibited impressive performance in language comprehension and various reasoning tasks. However, their abilities in spatial reasoning, a crucial aspect of human cognition, remain relatively unexplored. Human possess a remarkable ability to create mental images of unseen objects and actions through a process known as the Mind's Eye, enabling the imagination of the unseen world. Inspired by this cognitive capacity, we propose Visualization-of-Thought (VoT) prompting. VoT aims to elicit spatial reasoning of LLMs by visualizing their reasoning traces, thereby guiding subsequent reasoning steps. We employed VoT for multi-hop spatial reasoning tasks, including natural language navigation, visual navigation, and visual tiling in 2D grid worlds. Experimental results demonstrated that VoT significantly enhances the spatial reasoning abilities of LLMs. Notably, VoT outperformed existing multimodal large language models (MLLMs) in these tasks. While VoT works surprisingly well on LLMs, the ability to generate mental images to facilitate spatial reasoning resembles the mind's eye process, suggesting its potential viability in MLLMs.
5/27/2024
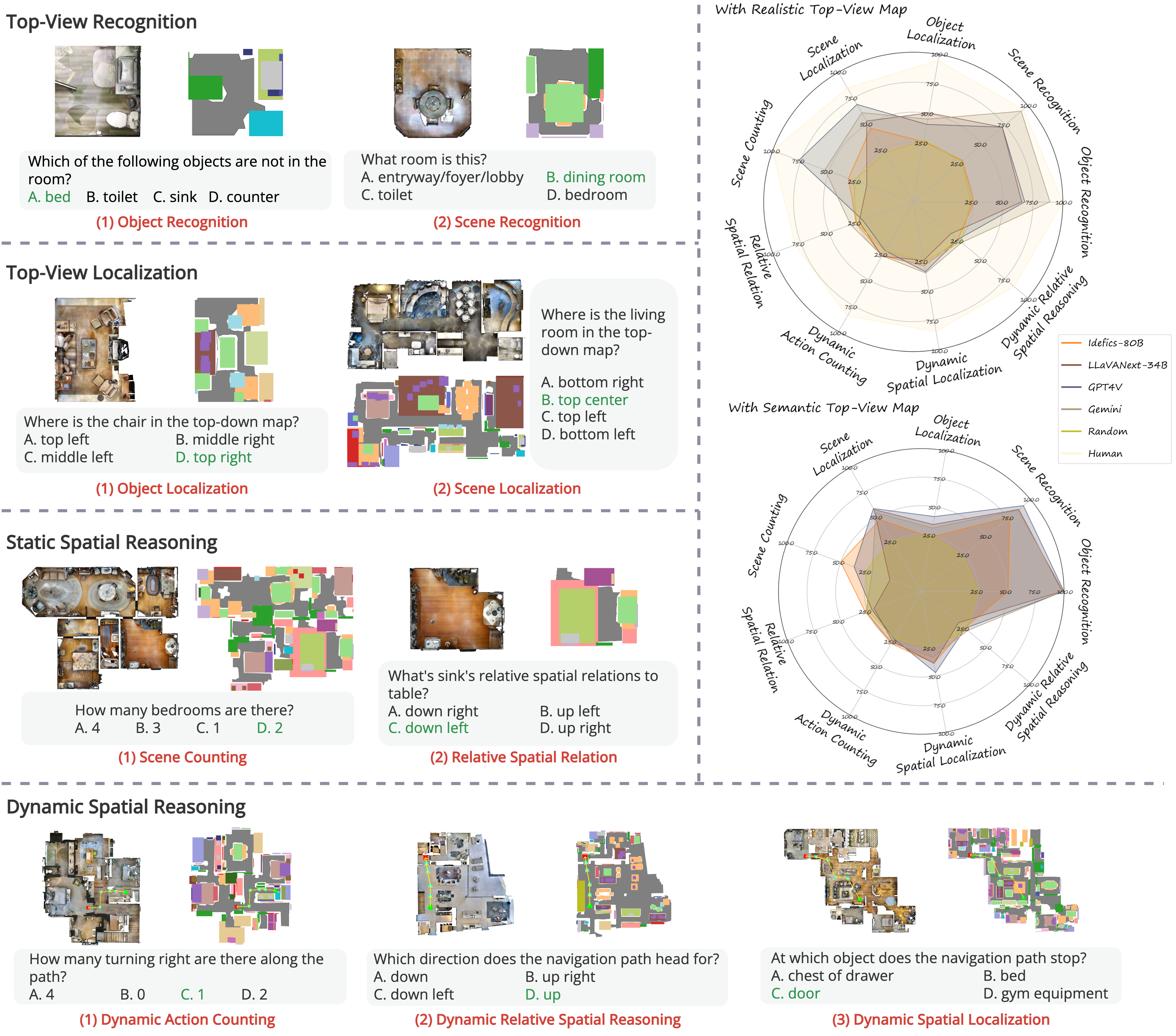
TopViewRS: Vision-Language Models as Top-View Spatial Reasoners
Chengzu Li, Caiqi Zhang, Han Zhou, Nigel Collier, Anna Korhonen, Ivan Vuli'c
0
0
Top-view perspective denotes a typical way in which humans read and reason over different types of maps, and it is vital for localization and navigation of humans as well as of `non-human' agents, such as the ones backed by large Vision-Language Models (VLMs). Nonetheless, spatial reasoning capabilities of modern VLMs remain unattested and underexplored. In this work, we thus study their capability to understand and reason over spatial relations from the top view. The focus on top view also enables controlled evaluations at different granularity of spatial reasoning; we clearly disentangle different abilities (e.g., recognizing particular objects versus understanding their relative positions). We introduce the TopViewRS (Top-View Reasoning in Space) dataset, consisting of 11,384 multiple-choice questions with either realistic or semantic top-view map as visual input. We then use it to study and evaluate VLMs across 4 perception and reasoning tasks with different levels of complexity. Evaluation of 10 representative open- and closed-source VLMs reveals the gap of more than 50% compared to average human performance, and it is even lower than the random baseline in some cases. Although additional experiments show that Chain-of-Thought reasoning can boost model capabilities by 5.82% on average, the overall performance of VLMs remains limited. Our findings underscore the critical need for enhanced model capability in top-view spatial reasoning and set a foundation for further research towards human-level proficiency of VLMs in real-world multimodal tasks.
6/5/2024

Learning to Localize Objects Improves Spatial Reasoning in Visual-LLMs
Kanchana Ranasinghe, Satya Narayan Shukla, Omid Poursaeed, Michael S. Ryoo, Tsung-Yu Lin
0
0
Integration of Large Language Models (LLMs) into visual domain tasks, resulting in visual-LLMs (V-LLMs), has enabled exceptional performance in vision-language tasks, particularly for visual question answering (VQA). However, existing V-LLMs (e.g. BLIP-2, LLaVA) demonstrate weak spatial reasoning and localization awareness. Despite generating highly descriptive and elaborate textual answers, these models fail at simple tasks like distinguishing a left vs right location. In this work, we explore how image-space coordinate based instruction fine-tuning objectives could inject spatial awareness into V-LLMs. We discover optimal coordinate representations, data-efficient instruction fine-tuning objectives, and pseudo-data generation strategies that lead to improved spatial awareness in V-LLMs. Additionally, our resulting model improves VQA across image and video domains, reduces undesired hallucination, and generates better contextual object descriptions. Experiments across 5 vision-language tasks involving 14 different datasets establish the clear performance improvements achieved by our proposed framework.
4/12/2024
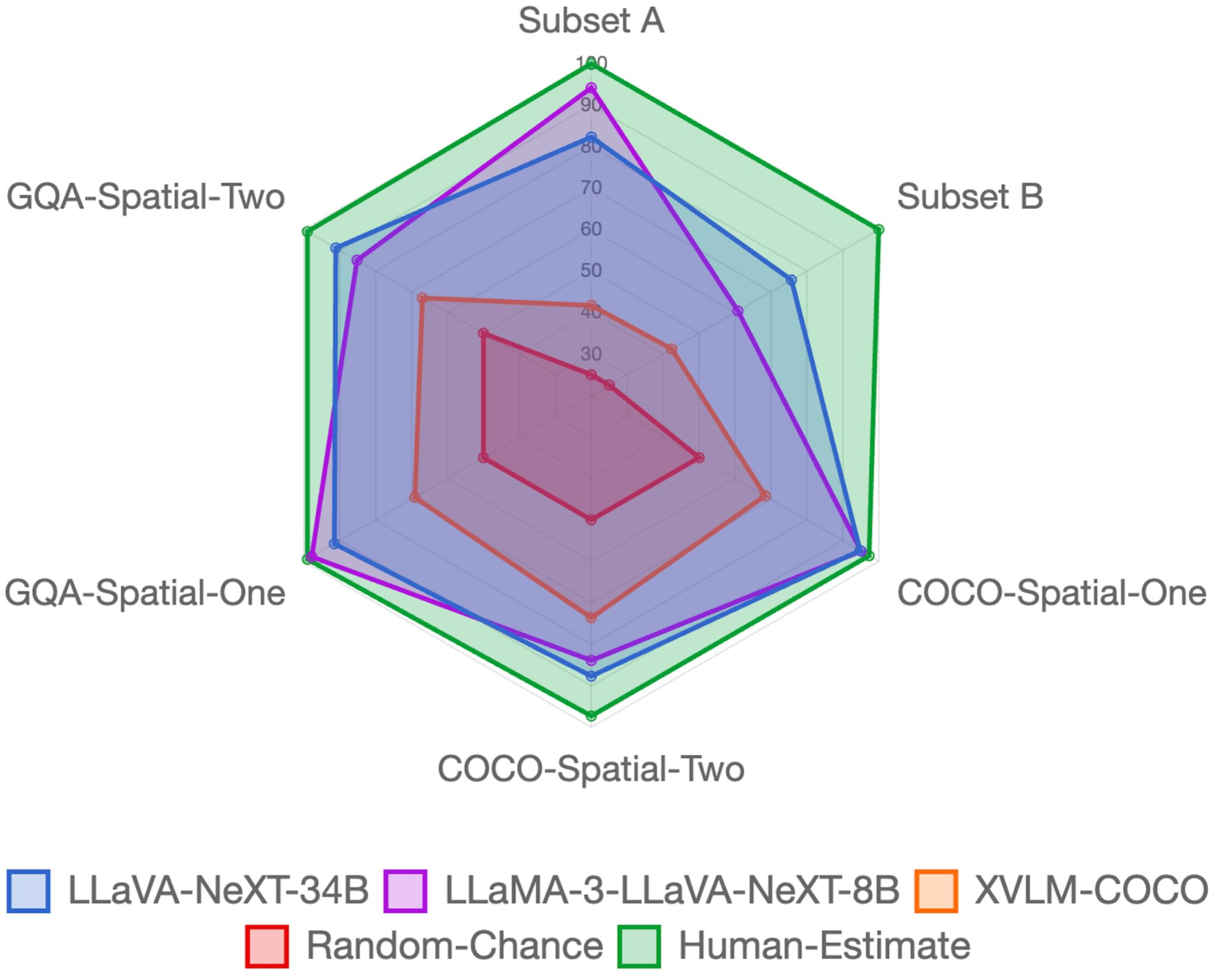
GSR-BENCH: A Benchmark for Grounded Spatial Reasoning Evaluation via Multimodal LLMs
Navid Rajabi, Jana Kosecka
0
0
The ability to understand and reason about spatial relationships between objects in images is an important component of visual reasoning. This skill rests on the ability to recognize and localize objects of interest and determine their spatial relation. Early vision and language models (VLMs) have been shown to struggle to recognize spatial relations. We extend the previously released What'sUp dataset and propose a novel comprehensive evaluation for spatial relationship understanding that highlights the strengths and weaknesses of 27 different models. In addition to the VLMs evaluated in What'sUp, our extensive evaluation encompasses 3 classes of Multimodal LLMs (MLLMs) that vary in their parameter sizes (ranging from 7B to 110B), training/instruction-tuning methods, and visual resolution to benchmark their performances and scrutinize the scaling laws in this task.
6/21/2024