GSR-BENCH: A Benchmark for Grounded Spatial Reasoning Evaluation via Multimodal LLMs
2406.13246
0
0
Abstract
The ability to understand and reason about spatial relationships between objects in images is an important component of visual reasoning. This skill rests on the ability to recognize and localize objects of interest and determine their spatial relation. Early vision and language models (VLMs) have been shown to struggle to recognize spatial relations. We extend the previously released What'sUp dataset and propose a novel comprehensive evaluation for spatial relationship understanding that highlights the strengths and weaknesses of 27 different models. In addition to the VLMs evaluated in What'sUp, our extensive evaluation encompasses 3 classes of Multimodal LLMs (MLLMs) that vary in their parameter sizes (ranging from 7B to 110B), training/instruction-tuning methods, and visual resolution to benchmark their performances and scrutinize the scaling laws in this task.
Create account to get full access
Overview
- Presents a new benchmark called GSR-Bench for evaluating the spatial reasoning capabilities of multimodal large language models (LLMs)
- Aims to assess how well LLMs can understand and reason about spatial relationships and dynamics in the real world
- Includes a diverse dataset of visual scenes and associated questions that require grounded spatial reasoning
Plain English Explanation
The paper introduces a new benchmark called GSR-Bench that is designed to test how well large language models can understand and reason about spatial relationships and dynamics in the real world. The key idea is to create a diverse dataset of visual scenes and associated questions that require the model to combine its understanding of language and visual information to answer correctly.
This is an important challenge because many real-world tasks, like navigation or object manipulation, involve spatial reasoning that goes beyond just recognizing objects in an image. A model needs to be able to understand concepts like relative position, motion, and spatial constraints. By creating this benchmark, the researchers aim to push the boundaries of what current multimodal language models are capable of and identify areas for further improvement.
The paper on reframing spatial reasoning evaluation for language models and the EmbSPATIAL-Bench paper on benchmarking spatial understanding for embodied tasks discuss related efforts to evaluate spatial reasoning in language models. The SpatialRGPT paper and paper on evaluating spatial understanding in large language models also explore this topic. The paper on benchmarking multi-image understanding in vision-language models is another relevant work.
Technical Explanation
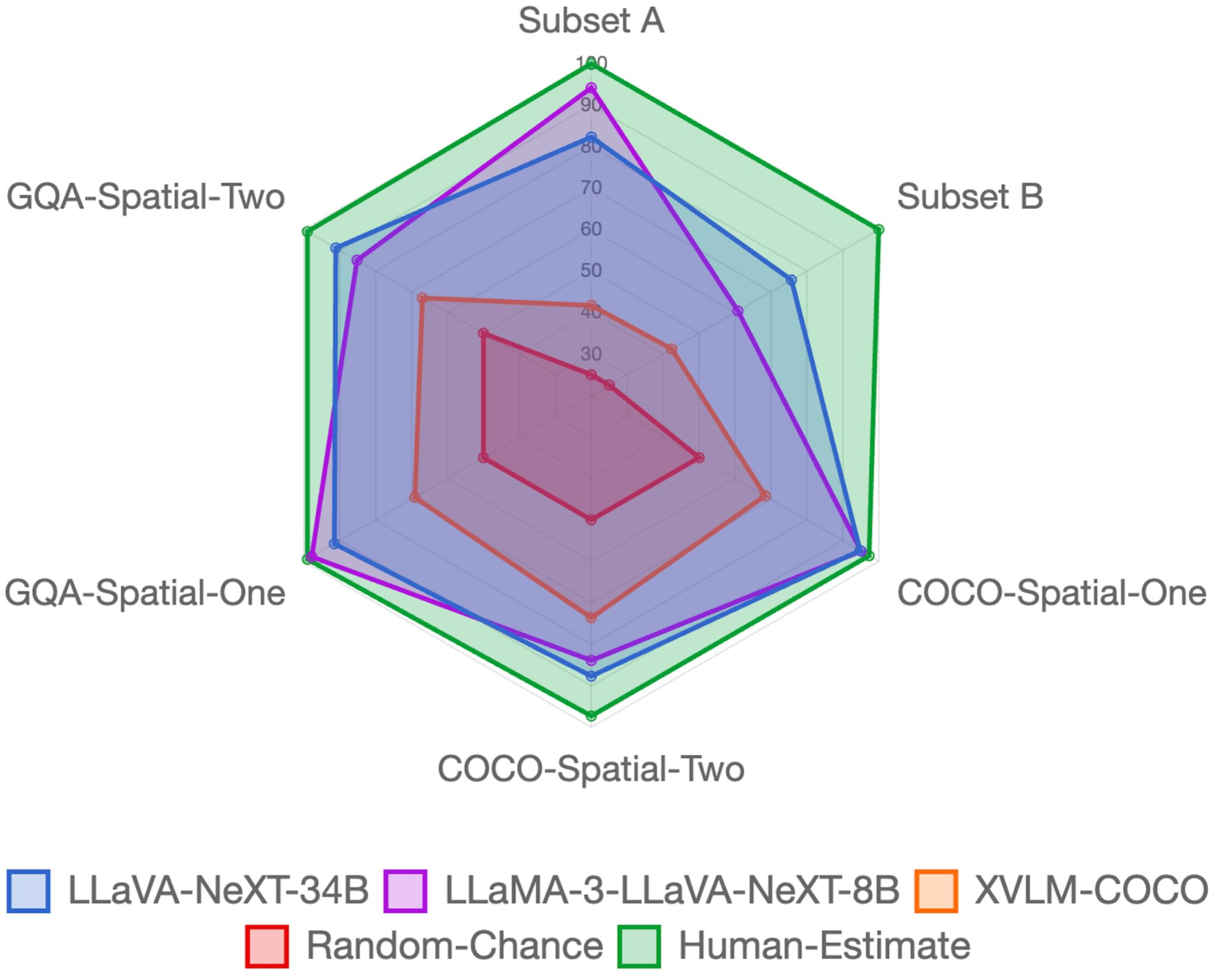
The core of GSR-Bench is a diverse dataset of visual scenes and associated questions that require grounded spatial reasoning to answer correctly. The dataset includes over 15,000 such questions spanning a wide range of spatial concepts, including relative position, motion, and spatial constraints.
To create the benchmark, the researchers first collected a large set of real-world images depicting various indoor and outdoor scenes. They then generated questions about these scenes that assessed different aspects of spatial reasoning, such as "Is the chair to the left of the table?" or "Where is the cat moving towards?". The questions were designed to require combining the visual information in the image with commonsense spatial knowledge to arrive at the correct answer.
The researchers evaluated several state-of-the-art multimodal language models on the GSR-Bench dataset, including VisualGPT and LXMERT. The models were tasked with answering the spatial reasoning questions based on the provided images. The results showed that while the models performed reasonably well on some types of questions, they struggled with more complex spatial reasoning tasks, particularly those involving motion and spatial constraints.
These findings suggest that current multimodal language models still have significant room for improvement when it comes to grounded spatial reasoning. The GSR-Bench dataset provides a valuable benchmark for measuring progress in this area and identifying the specific challenges that need to be addressed.
Critical Analysis
The GSR-Bench dataset and the accompanying evaluation provide a valuable contribution to the field of spatial reasoning in language models. By focusing on real-world scenes and grounded spatial concepts, the benchmark pushes beyond simpler spatial tasks that have been the focus of previous work.
However, the paper does acknowledge some limitations of the current benchmark. For example, the dataset is limited to a relatively small number of images and questions, and the spatial reasoning required is still relatively narrow in scope. Additionally, the authors note that the evaluation primarily focuses on question-answering performance, which may not fully capture the nuances of spatial reasoning.
Further research could explore expanding the dataset, incorporating more diverse spatial reasoning tasks, and developing more holistic evaluation methods. There is also an opportunity to investigate how different model architectures and training approaches might impact spatial reasoning capabilities.
Overall, the GSR-Bench benchmark represents an important step forward in the evaluation of spatial reasoning in language models. By highlighting the current limitations of these models, it provides a clear roadmap for future research and development in this critical area of multimodal AI.
Conclusion
The GSR-Bench benchmark introduced in this paper is a significant contribution to the field of spatial reasoning in language models. By creating a dataset of real-world visual scenes and associated spatial reasoning questions, the researchers have provided a valuable tool for evaluating the capabilities of current state-of-the-art multimodal models.
The results of the benchmark suggest that while these models have made progress in understanding language and visual information, they still struggle with more complex forms of spatial reasoning, particularly when it comes to motion and spatial constraints. This highlights the need for continued research and development in this area.
By providing a standardized benchmark and identifying specific challenges, the GSR-Bench paper lays the groundwork for future advancements in grounded spatial reasoning for language models. As these models become increasingly important for real-world applications, the ability to reason about spatial relationships and dynamics will be crucial. The insights gained from this work can help drive the field towards more capable and reliable multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Reframing Spatial Reasoning Evaluation in Language Models: A Real-World Simulation Benchmark for Qualitative Reasoning
Fangjun Li, David C. Hogg, Anthony G. Cohn
0
0
Spatial reasoning plays a vital role in both human cognition and machine intelligence, prompting new research into language models' (LMs) capabilities in this regard. However, existing benchmarks reveal shortcomings in evaluating qualitative spatial reasoning (QSR). These benchmarks typically present oversimplified scenarios or unclear natural language descriptions, hindering effective evaluation. We present a novel benchmark for assessing QSR in LMs, which is grounded in realistic 3D simulation data, offering a series of diverse room layouts with various objects and their spatial relationships. This approach provides a more detailed and context-rich narrative for spatial reasoning evaluation, diverging from traditional, toy-task-oriented scenarios. Our benchmark encompasses a broad spectrum of qualitative spatial relationships, including topological, directional, and distance relations. These are presented with different viewing points, varied granularities, and density of relation constraints to mimic real-world complexities. A key contribution is our logic-based consistency-checking tool, which enables the assessment of multiple plausible solutions, aligning with real-world scenarios where spatial relationships are often open to interpretation. Our benchmark evaluation of advanced LMs reveals their strengths and limitations in spatial reasoning. They face difficulties with multi-hop spatial reasoning and interpreting a mix of different view descriptions, pointing to areas for future improvement.
5/27/2024

EmbSpatial-Bench: Benchmarking Spatial Understanding for Embodied Tasks with Large Vision-Language Models
Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, Zhongyu Wei
0
0
The recent rapid development of Large Vision-Language Models (LVLMs) has indicated their potential for embodied tasks.However, the critical skill of spatial understanding in embodied environments has not been thoroughly evaluated, leaving the gap between current LVLMs and qualified embodied intelligence unknown. Therefore, we construct EmbSpatial-Bench, a benchmark for evaluating embodied spatial understanding of LVLMs.The benchmark is automatically derived from embodied scenes and covers 6 spatial relationships from an egocentric perspective.Experiments expose the insufficient capacity of current LVLMs (even GPT-4V). We further present EmbSpatial-SFT, an instruction-tuning dataset designed to improve LVLMs' embodied spatial understanding.
6/11/2024

Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Neel Joshi
0
0
Large language models (LLMs) and vision-language models (VLMs) have demonstrated remarkable performance across a wide range of tasks and domains. Despite this promise, spatial understanding and reasoning -- a fundamental component of human cognition -- remains under-explored. We develop novel benchmarks that cover diverse aspects of spatial reasoning such as relationship understanding, navigation, and counting. We conduct a comprehensive evaluation of competitive language and vision-language models. Our findings reveal several counter-intuitive insights that have been overlooked in the literature: (1) Spatial reasoning poses significant challenges where competitive models can fall behind random guessing; (2) Despite additional visual input, VLMs often under-perform compared to their LLM counterparts; (3) When both textual and visual information is available, multi-modal language models become less reliant on visual information if sufficient textual clues are provided. Additionally, we demonstrate that leveraging redundancy between vision and text can significantly enhance model performance. We hope our study will inform the development of multimodal models to improve spatial intelligence and further close the gap with human intelligence.
6/24/2024

SpatialRGPT: Grounded Spatial Reasoning in Vision Language Model
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, Sifei Liu
0
0
Vision Language Models (VLMs) have demonstrated remarkable performance in 2D vision and language tasks. However, their ability to reason about spatial arrangements remains limited. In this work, we introduce Spatial Region GPT (SpatialRGPT) to enhance VLMs' spatial perception and reasoning capabilities. SpatialRGPT advances VLMs' spatial understanding through two key innovations: (1) a data curation pipeline that enables effective learning of regional representation from 3D scene graphs, and (2) a flexible plugin module for integrating depth information into the visual encoder of existing VLMs. During inference, when provided with user-specified region proposals, SpatialRGPT can accurately perceive their relative directions and distances. Additionally, we propose SpatialRGBT-Bench, a benchmark with ground-truth 3D annotations encompassing indoor, outdoor, and simulated environments, for evaluating 3D spatial cognition in VLMs. Our results demonstrate that SpatialRGPT significantly enhances performance in spatial reasoning tasks, both with and without local region prompts. The model also exhibits strong generalization capabilities, effectively reasoning about complex spatial relations and functioning as a region-aware dense reward annotator for robotic tasks. Code, dataset, and benchmark will be released at https://www.anjiecheng.me/SpatialRGPT
6/21/2024