Is Sarcasm Detection A Step-by-Step Reasoning Process in Large Language Models?

0

Sign in to get full access
Overview
- This paper investigates whether sarcasm detection in large language models is a step-by-step reasoning process or a more holistic evaluation.
- The researchers use a novel technique called "chain-of-thought prompting" to explore the internal reasoning process of language models when detecting sarcasm.
- The findings suggest that sarcasm detection may not be a simple step-by-step process, but rather involves a more complex and nuanced understanding of context and subtext.
Plain English Explanation
The paper examines whether sarcasm detection in large language models, like the ones used in chatbots and virtual assistants, is a straightforward step-by-step process or a more sophisticated understanding of the underlying meaning. The researchers used a technique called "chain-of-thought prompting" to peek inside the language model's reasoning and see how it arrives at a sarcasm detection decision.
The results indicate that sarcasm detection is not as simple as following a set of rules or steps. Instead, the language model seems to consider the broader context and underlying meaning, rather than just looking for specific keywords or patterns. This suggests that sarcasm detection, and perhaps language understanding in general, is a more complex and nuanced process than previously thought.
The findings have important implications for the design and development of language models and artificial intelligence systems that need to accurately interpret human communication, which often involves subtext, irony, and other subtle forms of expression.
Technical Explanation
The paper explores the internal reasoning process of large language models when tasked with detecting sarcasm. The researchers use a novel technique called "chain-of-thought prompting" to elicit step-by-step reasoning from the models, in contrast to the more holistic outputs typically observed.
The study involves prompting language models with a series of questions that guide them through a multi-step reasoning process for sarcasm detection. By analyzing the intermediate steps, the researchers aim to determine whether sarcasm detection is a discrete, sequential reasoning process or a more complex, context-dependent evaluation.
The results suggest that sarcasm detection may not be a simple step-by-step process, but rather involves a more nuanced understanding of the underlying meaning and subtext. The language models' responses indicate that they consider a wide range of contextual factors, rather than relying on a predetermined set of rules or patterns.
This finding challenges the common assumption that sarcasm detection can be reduced to a series of logical steps, and instead points to a more holistic and sophisticated language understanding capability in large language models.
Critical Analysis
The paper provides a novel and insightful exploration of the internal reasoning process behind sarcasm detection in large language models. The use of chain-of-thought prompting is a clever approach to gain visibility into the models' decision-making, which is typically a black box.
However, the paper acknowledges several limitations in its methodology. The prompts used to elicit the step-by-step reasoning may not fully capture the models' true decision-making process, and the findings may be specific to the particular language models and dataset used in the study.
Additionally, the paper does not delve into the potential biases or shortcomings of the language models when it comes to sarcasm detection. It would be valuable to explore how these models might struggle with certain types of sarcasm or cultural contexts, and whether their performance aligns with human sarcasm detection abilities.
Further research in this area could investigate the generalizability of the findings, the role of different types of contextual information in sarcasm detection, and the potential for incorporating more nuanced, human-like reasoning into language models.
Conclusion
This paper provides an intriguing glimpse into the complex and nuanced internal reasoning process of large language models when it comes to sarcasm detection. The findings challenge the notion that sarcasm detection is a simple, step-by-step process, and instead suggest that it involves a more holistic understanding of context and subtext.
The implications of this research extend beyond sarcasm detection and point to the need for continued advancements in language understanding and the development of more sophisticated, context-aware artificial intelligence systems. As we strive to create machines that can communicate and interact with humans in more natural and intuitive ways, understanding the underlying reasoning processes of language models will be crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Is Sarcasm Detection A Step-by-Step Reasoning Process in Large Language Models?
Ben Yao, Yazhou Zhang, Qiuchi Li, Jing Qin
Elaborating a series of intermediate reasoning steps significantly improves the ability of large language models (LLMs) to solve complex problems, as such steps would evoke LLMs to think sequentially. However, human sarcasm understanding is often considered an intuitive and holistic cognitive process, in which various linguistic, contextual, and emotional cues are integrated to form a comprehensive understanding, in a way that does not necessarily follow a step-by-step fashion. To verify the validity of this argument, we introduce a new prompting framework (called SarcasmCue) containing four sub-methods, viz. chain of contradiction (CoC), graph of cues (GoC), bagging of cues (BoC) and tensor of cues (ToC), which elicits LLMs to detect human sarcasm by considering sequential and non-sequential prompting methods. Through a comprehensive empirical comparison on four benchmarks, we highlight three key findings: (1) CoC and GoC show superior performance with more advanced models like GPT-4 and Claude 3.5, with an improvement of 3.5%. (2) ToC significantly outperforms other methods when smaller LLMs are evaluated, boosting the F1 score by 29.7% over the best baseline. (3) Our proposed framework consistently pushes the state-of-the-art (i.e., ToT) by 4.2%, 2.0%, 29.7%, and 58.2% in F1 scores across four datasets. This demonstrates the effectiveness and stability of the proposed framework.
Read more8/27/2024

0
Towards Evaluating Large Language Models on Sarcasm Understanding
Yazhou Zhang, Chunwang Zou, Zheng Lian, Prayag Tiwari, Jing Qin
In the era of large language models (LLMs), the task of ``System I''~-~the fast, unconscious, and intuitive tasks, e.g., sentiment analysis, text classification, etc., have been argued to be successfully solved. However, sarcasm, as a subtle linguistic phenomenon, often employs rhetorical devices like hyperbole and figuration to convey true sentiments and intentions, involving a higher level of abstraction than sentiment analysis. There is growing concern that the argument about LLMs' success may not be fully tenable when considering sarcasm understanding. To address this question, we select eleven SOTA LLMs and eight SOTA pre-trained language models (PLMs) and present comprehensive evaluations on six widely used benchmark datasets through different prompting approaches, i.e., zero-shot input/output (IO) prompting, few-shot IO prompting, chain of thought (CoT) prompting. Our results highlight three key findings: (1) current LLMs underperform supervised PLMs based sarcasm detection baselines across six sarcasm benchmarks. This suggests that significant efforts are still required to improve LLMs' understanding of human sarcasm. (2) GPT-4 consistently and significantly outperforms other LLMs across various prompting methods, with an average improvement of 14.0%$uparrow$. Claude 3 and ChatGPT demonstrate the next best performance after GPT-4. (3) Few-shot IO prompting method outperforms the other two methods: zero-shot IO and few-shot CoT. The reason is that sarcasm detection, being a holistic, intuitive, and non-rational cognitive process, is argued not to adhere to step-by-step logical reasoning, making CoT less effective in understanding sarcasm compared to its effectiveness in mathematical reasoning tasks.
Read more8/27/2024
🗣️
0
CofiPara: A Coarse-to-fine Paradigm for Multimodal Sarcasm Target Identification with Large Multimodal Models
Hongzhan Lin, Zixin Chen, Ziyang Luo, Mingfei Cheng, Jing Ma, Guang Chen
Social media abounds with multimodal sarcasm, and identifying sarcasm targets is particularly challenging due to the implicit incongruity not directly evident in the text and image modalities. Current methods for Multimodal Sarcasm Target Identification (MSTI) predominantly focus on superficial indicators in an end-to-end manner, overlooking the nuanced understanding of multimodal sarcasm conveyed through both the text and image. This paper proposes a versatile MSTI framework with a coarse-to-fine paradigm, by augmenting sarcasm explainability with reasoning and pre-training knowledge. Inspired by the powerful capacity of Large Multimodal Models (LMMs) on multimodal reasoning, we first engage LMMs to generate competing rationales for coarser-grained pre-training of a small language model on multimodal sarcasm detection. We then propose fine-tuning the model for finer-grained sarcasm target identification. Our framework is thus empowered to adeptly unveil the intricate targets within multimodal sarcasm and mitigate the negative impact posed by potential noise inherently in LMMs. Experimental results demonstrate that our model far outperforms state-of-the-art MSTI methods, and markedly exhibits explainability in deciphering sarcasm as well.
Read more5/21/2024
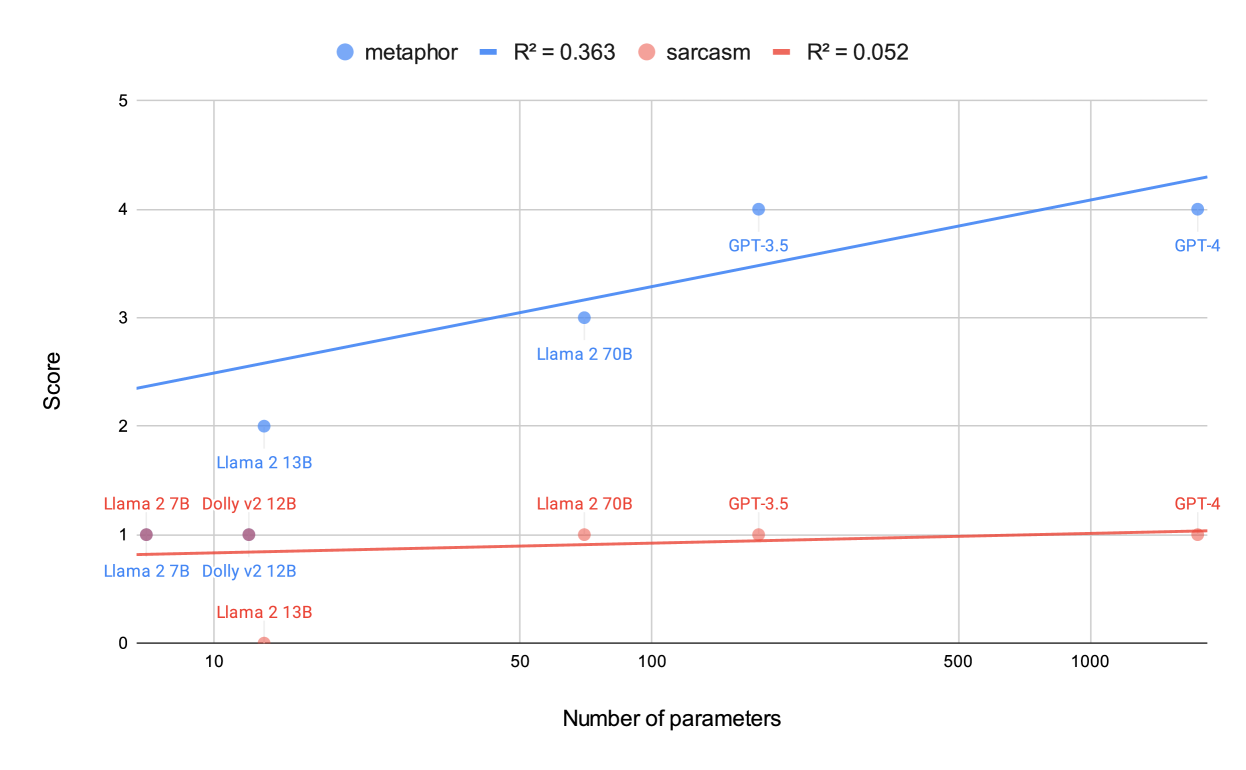
0
Evaluating Large Language Models' Ability Using a Psychiatric Screening Tool Based on Metaphor and Sarcasm Scenarios
Hiromu Yakura
Metaphors and sarcasm are precious fruits of our highly evolved social communication skills. However, children with the condition then known as Asperger syndrome are known to have difficulties in comprehending sarcasm, even if they possess adequate verbal IQs for understanding metaphors. Accordingly, researchers had employed a screening test that assesses metaphor and sarcasm comprehension to distinguish Asperger syndrome from other conditions with similar external behaviors (e.g., attention-deficit/hyperactivity disorder). This study employs a standardized test to evaluate recent large language models' (LLMs) understanding of nuanced human communication. The results indicate improved metaphor comprehension with increased model parameters; however, no similar improvement was observed for sarcasm comprehension. Considering that a human's ability to grasp sarcasm has been associated with the amygdala, a pivotal cerebral region for emotional learning, a distinctive strategy for training LLMs would be imperative to imbue them with the ability in a cognitively grounded manner.
Read more7/23/2024