Towards Evaluating Large Language Models on Sarcasm Understanding

0

Sign in to get full access
Overview
- This paper examines how well large language models (LLMs) can understand sarcasm.
- The researchers developed a new dataset for evaluating sarcasm understanding and used it to test the capabilities of different LLMs.
- Their results provide insights into the strengths and limitations of current LLMs in this area.
Plain English Explanation
The paper is about evaluating how well large language models (LLMs) - powerful AI systems that can understand and generate human-like text - can detect and understand sarcasm. Sarcasm is a form of verbal irony where the intended meaning is the opposite of the literal meaning.
The researchers created a new dataset of sarcastic and non-sarcastic text samples, which they used to test different LLMs. They wanted to see how accurately the LLMs could identify sarcasm in the text samples. Understanding sarcasm is challenging for AI systems, as it requires grasping nuanced language and social context.
The results provide insights into the current capabilities and limitations of LLMs when it comes to sarcasm understanding. This is an important area to explore, as the ability to recognize sarcasm is crucial for natural language understanding and many real-world applications, like analyzing mental health or understanding user intent.
Technical Explanation
The paper presents a new dataset, called the Sarcasm Understanding Dataset (SUD), which the researchers used to evaluate the sarcasm understanding capabilities of different large language models (LLMs). The dataset contains 10,000 text samples, half of which are sarcastic and half non-sarcastic, drawn from online discussions.
The researchers tested several prominent LLMs, including GPT-3, BERT, and RoBERTa, on the SUD dataset. They measured the models' accuracy in correctly identifying whether each text sample was sarcastic or not. The results showed that while the LLMs performed reasonably well, there is still room for improvement in their sarcasm understanding abilities.
The paper also introduces a new sarcasm detection metric called Sarcasm F1, which combines precision and recall to provide a more comprehensive evaluation. Using this metric, the researchers found that the best-performing LLM achieved an F1 score of around 0.70, indicating there is still significant room for improvement.
Additionally, the paper explores the relationship between the LLMs' performance on the SUD dataset and their capabilities on other sarcasm-related tasks and emotion recognition. The findings suggest that sarcasm understanding is a distinct challenge that is not fully captured by existing language understanding benchmarks.
Critical Analysis
The paper provides a valuable contribution to the field of natural language understanding by introducing a new dataset and evaluation method for assessing the sarcasm understanding capabilities of large language models. The researchers have taken a rigorous and thoughtful approach, which is reflected in the quality of the dataset and the thoroughness of the experiments.
However, the paper also acknowledges several limitations and areas for further research. For example, the dataset is limited to English text, and it would be beneficial to expand the evaluation to other languages. Additionally, the researchers note that the SUD dataset may not capture the full complexity of sarcasm, as it focuses primarily on textual cues and does not incorporate multimodal or contextual information.
Another potential limitation is the reliance on existing LLMs, which may not be optimized for sarcasm understanding. It could be valuable to explore novel architectures or training approaches that are specifically designed to improve sarcasm detection and comprehension.
Overall, this paper represents an important step forward in understanding the capabilities and limitations of large language models when it comes to sarcasm understanding. The insights and methodologies presented here can serve as a foundation for future research in this area, as researchers continue to push the boundaries of natural language understanding.
Conclusion
This paper investigates the ability of large language models to understand sarcasm, a crucial aspect of natural language understanding with important real-world applications. The researchers developed a new dataset to evaluate LLM performance and found that while current models show promising results, there is still significant room for improvement.
The findings of this study highlight the need for continued research and innovation in the field of sarcasm understanding, as the ability to accurately detect and comprehend sarcasm is essential for building more intelligent and human-like language systems. By advancing our understanding of sarcasm processing in LLMs, we can pave the way for more robust and versatile natural language AI that can better engage with and understand human communication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Evaluating Large Language Models on Sarcasm Understanding
Yazhou Zhang, Chunwang Zou, Zheng Lian, Prayag Tiwari, Jing Qin
In the era of large language models (LLMs), the task of ``System I''~-~the fast, unconscious, and intuitive tasks, e.g., sentiment analysis, text classification, etc., have been argued to be successfully solved. However, sarcasm, as a subtle linguistic phenomenon, often employs rhetorical devices like hyperbole and figuration to convey true sentiments and intentions, involving a higher level of abstraction than sentiment analysis. There is growing concern that the argument about LLMs' success may not be fully tenable when considering sarcasm understanding. To address this question, we select eleven SOTA LLMs and eight SOTA pre-trained language models (PLMs) and present comprehensive evaluations on six widely used benchmark datasets through different prompting approaches, i.e., zero-shot input/output (IO) prompting, few-shot IO prompting, chain of thought (CoT) prompting. Our results highlight three key findings: (1) current LLMs underperform supervised PLMs based sarcasm detection baselines across six sarcasm benchmarks. This suggests that significant efforts are still required to improve LLMs' understanding of human sarcasm. (2) GPT-4 consistently and significantly outperforms other LLMs across various prompting methods, with an average improvement of 14.0%$uparrow$. Claude 3 and ChatGPT demonstrate the next best performance after GPT-4. (3) Few-shot IO prompting method outperforms the other two methods: zero-shot IO and few-shot CoT. The reason is that sarcasm detection, being a holistic, intuitive, and non-rational cognitive process, is argued not to adhere to step-by-step logical reasoning, making CoT less effective in understanding sarcasm compared to its effectiveness in mathematical reasoning tasks.
Read more8/27/2024

0
Is Sarcasm Detection A Step-by-Step Reasoning Process in Large Language Models?
Ben Yao, Yazhou Zhang, Qiuchi Li, Jing Qin
Elaborating a series of intermediate reasoning steps significantly improves the ability of large language models (LLMs) to solve complex problems, as such steps would evoke LLMs to think sequentially. However, human sarcasm understanding is often considered an intuitive and holistic cognitive process, in which various linguistic, contextual, and emotional cues are integrated to form a comprehensive understanding, in a way that does not necessarily follow a step-by-step fashion. To verify the validity of this argument, we introduce a new prompting framework (called SarcasmCue) containing four sub-methods, viz. chain of contradiction (CoC), graph of cues (GoC), bagging of cues (BoC) and tensor of cues (ToC), which elicits LLMs to detect human sarcasm by considering sequential and non-sequential prompting methods. Through a comprehensive empirical comparison on four benchmarks, we highlight three key findings: (1) CoC and GoC show superior performance with more advanced models like GPT-4 and Claude 3.5, with an improvement of 3.5%. (2) ToC significantly outperforms other methods when smaller LLMs are evaluated, boosting the F1 score by 29.7% over the best baseline. (3) Our proposed framework consistently pushes the state-of-the-art (i.e., ToT) by 4.2%, 2.0%, 29.7%, and 58.2% in F1 scores across four datasets. This demonstrates the effectiveness and stability of the proposed framework.
Read more8/27/2024
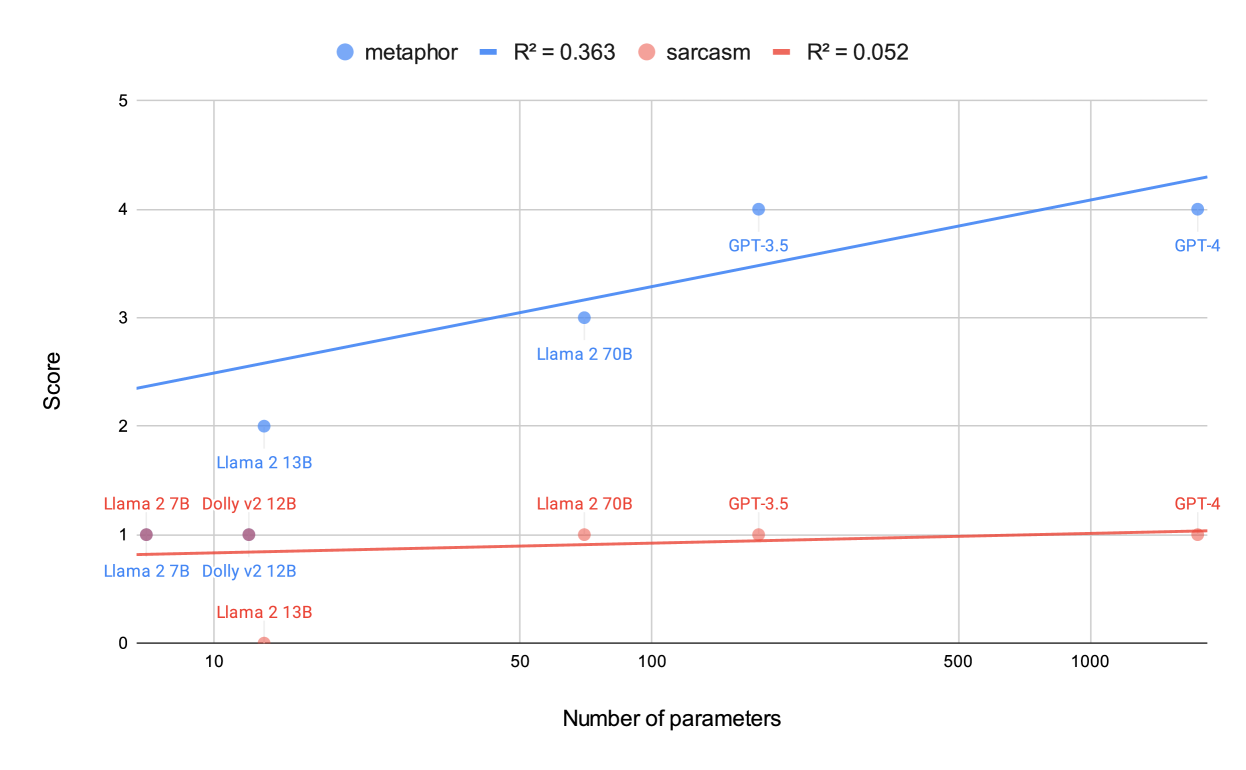
0
Evaluating Large Language Models' Ability Using a Psychiatric Screening Tool Based on Metaphor and Sarcasm Scenarios
Hiromu Yakura
Metaphors and sarcasm are precious fruits of our highly evolved social communication skills. However, children with the condition then known as Asperger syndrome are known to have difficulties in comprehending sarcasm, even if they possess adequate verbal IQs for understanding metaphors. Accordingly, researchers had employed a screening test that assesses metaphor and sarcasm comprehension to distinguish Asperger syndrome from other conditions with similar external behaviors (e.g., attention-deficit/hyperactivity disorder). This study employs a standardized test to evaluate recent large language models' (LLMs) understanding of nuanced human communication. The results indicate improved metaphor comprehension with increased model parameters; however, no similar improvement was observed for sarcasm comprehension. Considering that a human's ability to grasp sarcasm has been associated with the amygdala, a pivotal cerebral region for emotional learning, a distinctive strategy for training LLMs would be imperative to imbue them with the ability in a cognitively grounded manner.
Read more7/23/2024

0
Reading with Intent
Benjamin Reichman, Kartik Talamadupula, Toshish Jawale, Larry Heck
Retrieval augmented generation (RAG) systems augment how knowledge language models are by integrating external information sources such as Wikipedia, internal documents, scientific papers, or the open internet. RAG systems that rely on the open internet as their knowledge source have to contend with the complexities of human-generated content. Human communication extends much deeper than just the words rendered as text. Intent, tonality, and connotation can all change the meaning of what is being conveyed. Recent real-world deployments of RAG systems have shown some difficulty in understanding these nuances of human communication. One significant challenge for these systems lies in processing sarcasm. Though the Large Language Models (LLMs) that make up the backbone of these RAG systems are able to detect sarcasm, they currently do not always use these detections for the subsequent processing of text. To address these issues, in this paper, we synthetically generate sarcastic passages from Natural Question's Wikipedia retrieval corpus. We then test the impact of these passages on the performance of both the retriever and reader portion of the RAG pipeline. We introduce a prompting system designed to enhance the model's ability to interpret and generate responses in the presence of sarcasm, thus improving overall system performance. Finally, we conduct ablation studies to validate the effectiveness of our approach, demonstrating improvements in handling sarcastic content within RAG systems.
Read more8/22/2024