Mind the Gap Between Synthetic and Real: Utilizing Transfer Learning to Probe the Boundaries of Stable Diffusion Generated Data
2405.03243
0
0
🔄
Abstract
Generative foundation models like Stable Diffusion comprise a diverse spectrum of knowledge in computer vision with the potential for transfer learning, e.g., via generating data to train student models for downstream tasks. This could circumvent the necessity of collecting labeled real-world data, thereby presenting a form of data-free knowledge distillation. However, the resultant student models show a significant drop in accuracy compared to models trained on real data. We investigate possible causes for this drop and focus on the role of the different layers of the student model. By training these layers using either real or synthetic data, we reveal that the drop mainly stems from the model's final layers. Further, we briefly investigate other factors, such as differences in data-normalization between synthetic and real, the impact of data augmentations, texture vs. shape learning, and assuming oracle prompts. While we find that some of those factors can have an impact, they are not sufficient to close the gap towards real data. Building upon our insights that mainly later layers are responsible for the drop, we investigate the data-efficiency of fine-tuning a synthetically trained model with real data applied to only those last layers. Our results suggest an improved trade-off between the amount of real training data used and the model's accuracy. Our findings contribute to the understanding of the gap between synthetic and real data and indicate solutions to mitigate the scarcity of labeled real data.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers investigate the use of generative foundation models like Stable Diffusion to generate synthetic data for training student models on downstream tasks.
- While this approach could circumvent the need for collecting labeled real-world data, the resulting student models show a significant drop in accuracy compared to those trained on real data.
- The paper explores potential causes for this performance gap and focuses on the role of different layers within the student model.
Plain English Explanation
Generative models like Stable Diffusion are powerful AI systems that can create synthetic images. The researchers wanted to see if they could use these synthetic images to train other AI models (called "student" models) for specific tasks, like recognizing objects in images.
The idea is that generating synthetic data could be more efficient than collecting labeled real-world data, which can be time-consuming and expensive. However, the researchers found that the student models trained on synthetic data performed significantly worse than those trained on real data.
To understand why this performance gap exists, the researchers looked closely at the different parts or "layers" of the student models. They discovered that the problem mainly comes from the final layers of the models, which struggle to learn from the synthetic data.
The researchers also explored other factors, like differences in how the synthetic and real data are normalized, the impact of data augmentation (adding noise or transformations to the data), and the model's focus on texture vs. shape. While these factors can play a role, they aren't enough on their own to fully close the gap between synthetic and real data performance.
Building on their insights, the researchers investigated a technique called "fine-tuning," where they took a model trained on synthetic data and further trained just the final layers on a smaller amount of real data. This approach helped improve the trade-off between the amount of real data used and the model's accuracy, suggesting a potential solution to the challenge of scarce labeled real-world data.
Technical Explanation
The researchers investigated the use of generative foundation models, such as Stable Diffusion, to generate synthetic data for training student models on downstream tasks. This approach could potentially circumvent the need for collecting labeled real-world data, a process that can be time-consuming and expensive.
However, the resulting student models showed a significant drop in accuracy compared to those trained on real data. To understand the reasons for this performance gap, the researchers focused on the role of the different layers within the student model.
By training these layers using either real or synthetic data, the researchers revealed that the drop in accuracy mainly stems from the model's final layers. They also briefly investigated other factors, such as differences in data normalization between synthetic and real data, the impact of data augmentations, texture vs. shape learning, and the use of "oracle" prompts (highly curated synthetic data).
While some of these factors were found to have an impact, they were not sufficient to close the gap towards real data performance. Building on the insight that the final layers are primarily responsible for the drop, the researchers investigated the data-efficiency of fine-tuning a synthetically trained model with real data, applying this fine-tuning only to the last layers. Their results suggest an improved trade-off between the amount of real training data used and the model's accuracy.
These findings contribute to the understanding of the gap between synthetic and real data and indicate potential solutions to mitigate the scarcity of labeled real-world data, such as the use of data-free knowledge distillation and iterative retraining of generative models.
Critical Analysis
The paper provides valuable insights into the challenges of using synthetic data generated by foundation models like Stable Diffusion for training student models. The researchers' focus on the role of different model layers is a thoughtful approach to understanding the root causes of the performance gap between synthetic and real data.
While the researchers explored several factors that may contribute to this gap, they acknowledge that these factors alone are not sufficient to fully close the gap. Additional research is needed to further investigate other potential causes, such as the fidelity of the synthetic data generation process or the inherent differences between synthetic and real-world data distributions.
Another limitation of the study is the relatively narrow scope of the experiments, which focused on a single downstream task and a specific student model architecture. It would be interesting to see if the findings hold true across a wider range of tasks and model architectures, as well as to explore the generalizability of the fine-tuning approach to other domains.
Furthermore, the researchers briefly mention the impact of "oracle" prompts, but do not delve deeply into the role of prompt engineering in synthetic data generation. As research on diffusion-based deepfakes has shown, the quality of prompts can significantly affect the fidelity of the generated data. Exploring this aspect more thoroughly could provide additional insights into the challenges of using synthetic data for training.
Overall, the paper makes a valuable contribution to the understanding of the trade-offs between synthetic and real data for transfer learning and highlights the need for continued research in this area to unlock the full potential of foundation models for data-efficient learning.
Conclusion
This research investigates the use of generative foundation models, such as Stable Diffusion, to generate synthetic data for training student models on downstream tasks. While this approach could circumvent the need for collecting labeled real-world data, the resulting student models show a significant drop in accuracy compared to those trained on real data.
The paper's key finding is that the performance gap mainly stems from the student model's final layers, which struggle to learn effectively from the synthetic data. The researchers also explored other factors, such as data normalization, data augmentation, and texture vs. shape learning, but found that these factors alone are not sufficient to close the gap.
Building on these insights, the researchers investigated a fine-tuning approach that applies real data training only to the final layers of a synthetically trained model. This technique showed an improved trade-off between the amount of real training data used and the model's accuracy, suggesting a potential solution to the challenge of scarce labeled real-world data.
These findings contribute to the understanding of the limitations and opportunities in using synthetic data for transfer learning and highlight the need for continued research to unlock the full potential of foundation models for data-efficient learning across a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
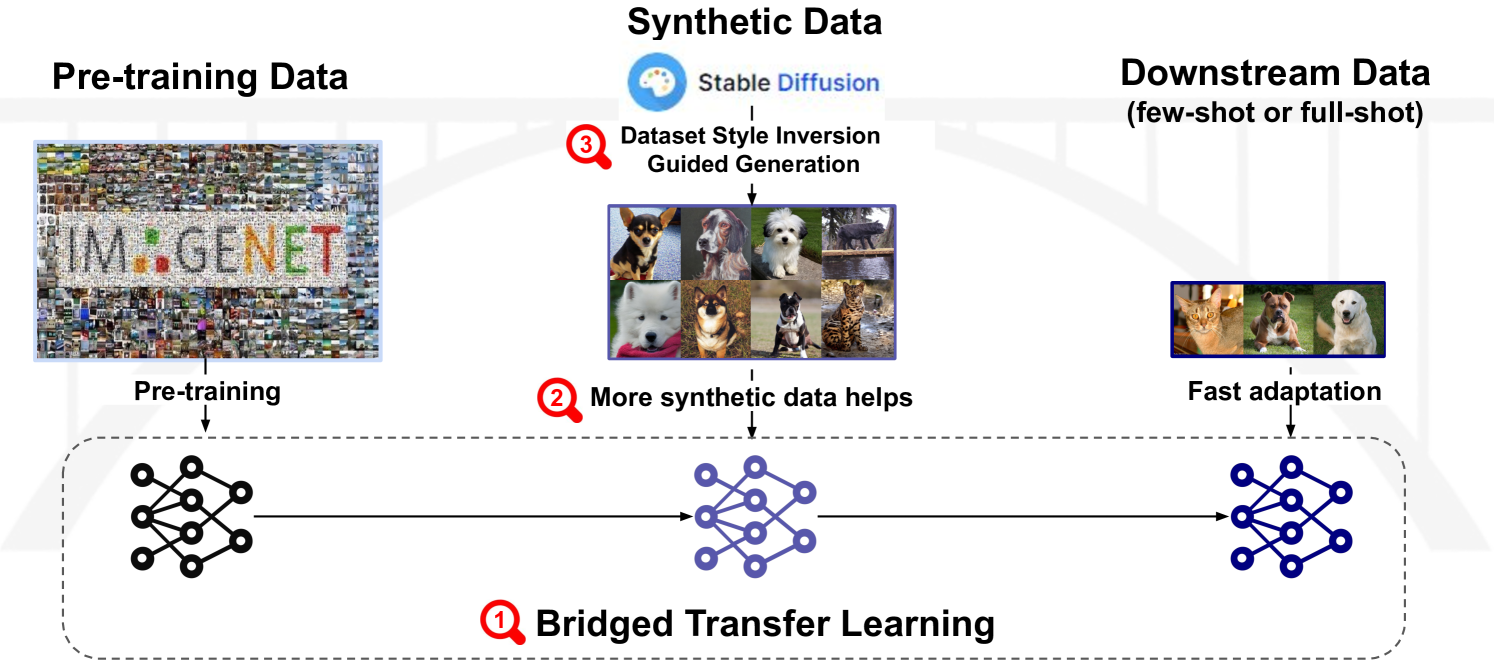
Is Synthetic Image Useful for Transfer Learning? An Investigation into Data Generation, Volume, and Utilization
Yuhang Li, Xin Dong, Chen Chen, Jingtao Li, Yuxin Wen, Michael Spranger, Lingjuan Lyu
0
0
Synthetic image data generation represents a promising avenue for training deep learning models, particularly in the realm of transfer learning, where obtaining real images within a specific domain can be prohibitively expensive due to privacy and intellectual property considerations. This work delves into the generation and utilization of synthetic images derived from text-to-image generative models in facilitating transfer learning paradigms. Despite the high visual fidelity of the generated images, we observe that their naive incorporation into existing real-image datasets does not consistently enhance model performance due to the inherent distribution gap between synthetic and real images. To address this issue, we introduce a novel two-stage framework called bridged transfer, which initially employs synthetic images for fine-tuning a pre-trained model to improve its transferability and subsequently uses real data for rapid adaptation. Alongside, We propose dataset style inversion strategy to improve the stylistic alignment between synthetic and real images. Our proposed methods are evaluated across 10 different datasets and 5 distinct models, demonstrating consistent improvements, with up to 30% accuracy increase on classification tasks. Intriguingly, we note that the enhancements were not yet saturated, indicating that the benefits may further increase with an expanded volume of synthetic data.
4/4/2024
Stable Diffusion Dataset Generation for Downstream Classification Tasks
Eugenio Lomurno, Matteo D'Oria, Matteo Matteucci
0
0
Recent advances in generative artificial intelligence have enabled the creation of high-quality synthetic data that closely mimics real-world data. This paper explores the adaptation of the Stable Diffusion 2.0 model for generating synthetic datasets, using Transfer Learning, Fine-Tuning and generation parameter optimisation techniques to improve the utility of the dataset for downstream classification tasks. We present a class-conditional version of the model that exploits a Class-Encoder and optimisation of key generation parameters. Our methodology led to synthetic datasets that, in a third of cases, produced models that outperformed those trained on real datasets.
5/7/2024
📊
On the Stability of Iterative Retraining of Generative Models on their own Data
Quentin Bertrand, Avishek Joey Bose, Alexandre Duplessis, Marco Jiralerspong, Gauthier Gidel
0
0
Deep generative models have made tremendous progress in modeling complex data, often exhibiting generation quality that surpasses a typical human's ability to discern the authenticity of samples. Undeniably, a key driver of this success is enabled by the massive amounts of web-scale data consumed by these models. Due to these models' striking performance and ease of availability, the web will inevitably be increasingly populated with synthetic content. Such a fact directly implies that future iterations of generative models will be trained on both clean and artificially generated data from past models. In this paper, we develop a framework to rigorously study the impact of training generative models on mixed datasets -- from classical training on real data to self-consuming generative models trained on purely synthetic data. We first prove the stability of iterative training under the condition that the initial generative models approximate the data distribution well enough and the proportion of clean training data (w.r.t. synthetic data) is large enough. We empirically validate our theory on both synthetic and natural images by iteratively training normalizing flows and state-of-the-art diffusion models on CIFAR10 and FFHQ.
4/3/2024
🏋️
Exploring Limits of Diffusion-Synthetic Training with Weakly Supervised Semantic Segmentation
Ryota Yoshihashi, Yuya Otsuka, Kenji Doi, Tomohiro Tanaka, Hirokatsu Kataoka
0
0
The advance of generative models for images has inspired various training techniques for image recognition utilizing synthetic images. In semantic segmentation, one promising approach is extracting pseudo-masks from attention maps in text-to-image diffusion models, which enables real-image-and-annotation-free training. However, the pioneering training method using the diffusion-synthetic images and pseudo-masks, i.e., DiffuMask has limitations in terms of mask quality, scalability, and ranges of applicable domains. To overcome these limitations, this work introduces three techniques for diffusion-synthetic semantic segmentation training. First, reliability-aware robust training, originally used in weakly supervised learning, helps segmentation with insufficient synthetic mask quality. %Second, large-scale pretraining of whole segmentation models, not only backbones, on synthetic ImageNet-1k-class images with pixel-labels benefits downstream segmentation tasks. Second, we introduce prompt augmentation, data augmentation to the prompt text set to scale up and diversify training images with a limited text resources. Finally, LoRA-based adaptation of Stable Diffusion enables the transfer to a distant domain, e.g., auto-driving images. Experiments in PASCAL VOC, ImageNet-S, and Cityscapes show that our method effectively closes gap between real and synthetic training in semantic segmentation.
4/16/2024